Daisy-TTS: Simulating Wider Spectrum of Emotions via Prosody Embedding Decomposition
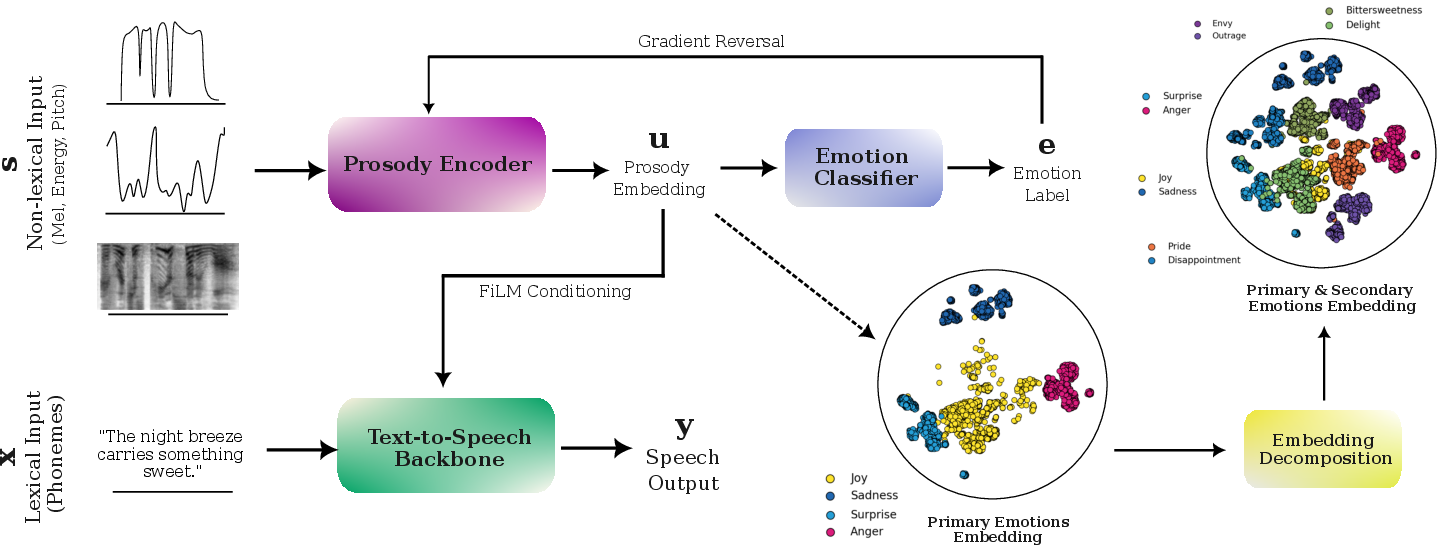
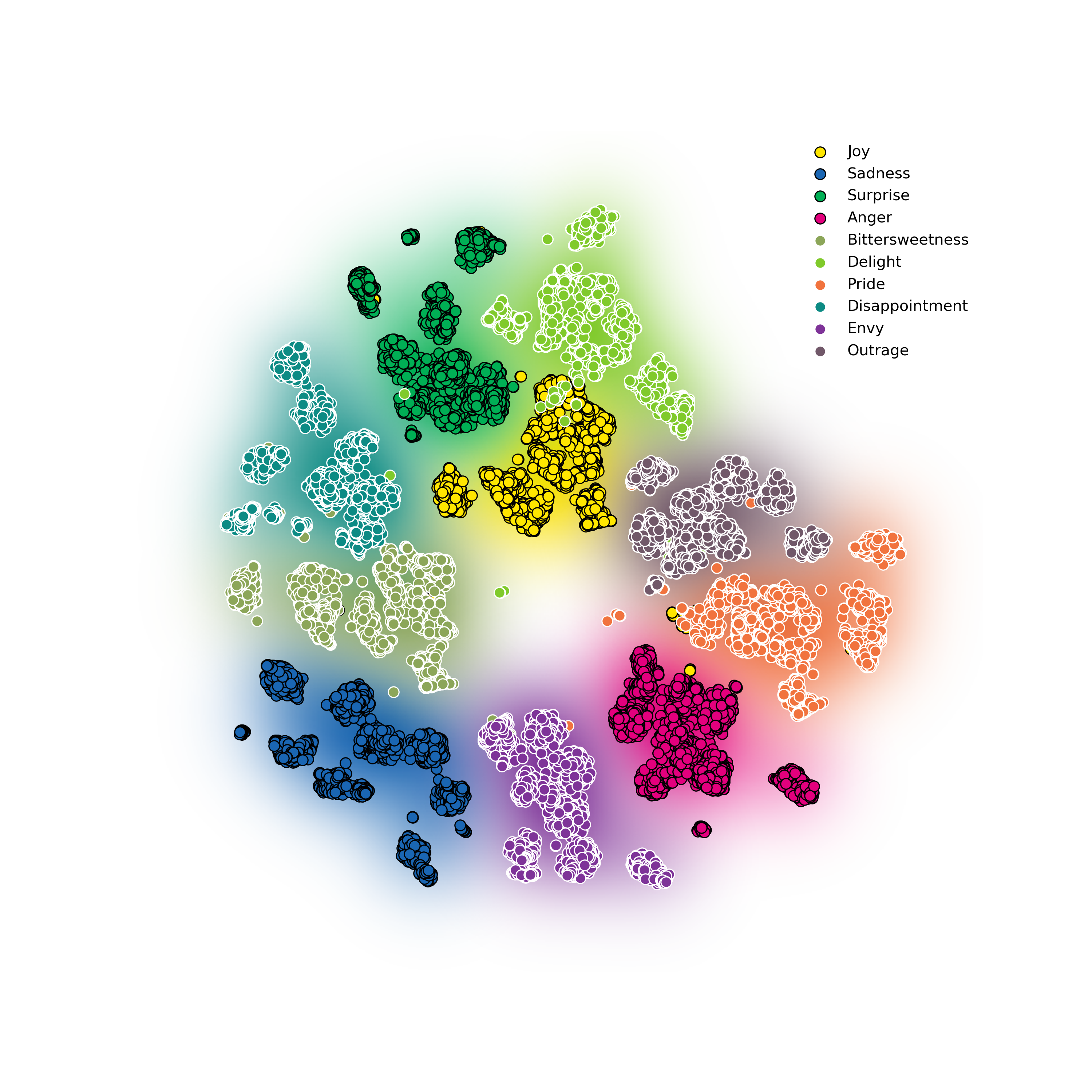
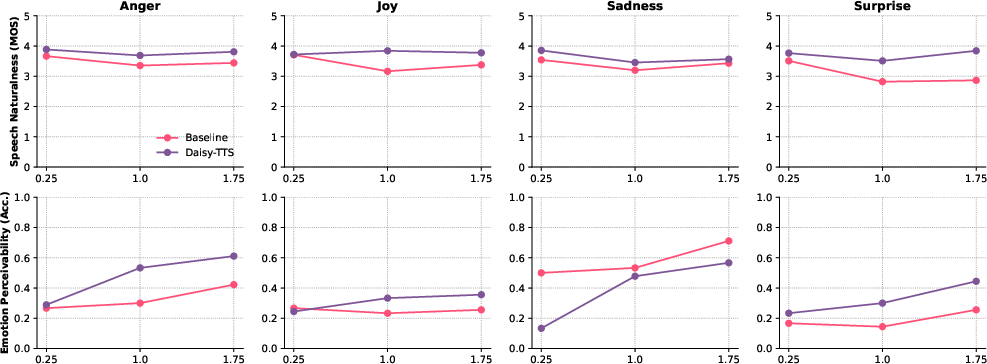
Abstract: We often verbally express emotions in a multifaceted manner, they may vary in their intensities and may be expressed not just as a single but as a mixture of emotions. This wide spectrum of emotions is well-studied in the structural model of emotions, which represents variety of emotions as derivative products of primary emotions with varying degrees of intensity. In this paper, we propose an emotional text-to-speech design to simulate a wider spectrum of emotions grounded on the structural model. Our proposed design, Daisy-TTS, incorporates a prosody encoder to learn emotionally-separable prosody embedding as a proxy for emotion. This emotion representation allows the model to simulate: (1) Primary emotions, as learned from the training samples, (2) Secondary emotions, as a mixture of primary emotions, (3) Intensity-level, by scaling the emotion embedding, and (4) Emotions polarity, by negating the emotion embedding. Through a series of perceptual evaluations, Daisy-TTS demonstrated overall higher emotional speech naturalness and emotion perceiveability compared to the baseline.
- Volker Blanz and Thomas Vetter. 2023. A morphable model for the synthesis of 3d faces. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 157–164.
- The primacy of categories in the recognition of 12 emotions in speech prosody across two cultures. Nature human behaviour, 3(4):369–382.
- 3d morphable face models – past, present and future.
- Paul Ekman. 1992. An argument for basic emotions. Cognition & emotion, 6(3-4):169–200.
- Yaroslav Ganin and Victor Lempitsky. 2015. Unsupervised domain adaptation by backpropagation.
- Denoising diffusion probabilistic models.
- Glow-tts: A generative flow for text-to-speech via monotonic alignment search.
- Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis.
- Emotional end-to-end neural speech synthesizer.
- Ilya Loshchilov and Frank Hutter. 2019. Decoupled weight decay regularization.
- Sylvie Mozziconacci. 2002. Prosody and emotions. In Proc. Speech Prosody 2002, pages 1–9.
- Film: Visual reasoning with a general conditioning layer.
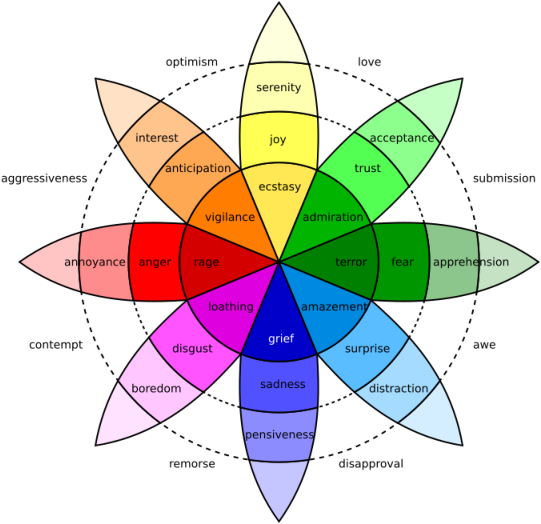
- Robert Plutchik. 1982. A psychoevolutionary theory of emotions.
- Robert Plutchik. 1984. Emotions: A general psychoevolutionary theory. Approaches to emotion, 1984(197-219):2–4.
- Grad-tts: A diffusion probabilistic model for text-to-speech.
- Exploring emotional prototypes in a high dimensional tts latent space. In Interspeech 2021, interspeech 2021. ISCA.
- U-net: Convolutional networks for biomedical image segmentation.
- James A Russell. 1980. A circumplex model of affect. Journal of personality and social psychology, 39(6):1161.
- Klaus R Scherer and Paul Ekman. 2014. Approaches to emotion. Psychology Press.
- Dagmar Schuller and Björn Schuller. 2020. A review on five recent and near-future developments in computational processing of emotion in the human voice. Emotion Review, 13:175407391989852.
- Towards end-to-end prosody transfer for expressive speech synthesis with tacotron.
- Emomix: Emotion mixing via diffusion models for emotional speech synthesis.
- Emotion ratings: How intensity, annotation confidence and agreements are entangled.
- Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-sne. Journal of machine learning research, 9(11).
- Style tokens: Unsupervised style modeling, control and transfer in end-to-end speech synthesis.
- Principal component analysis. Chemometrics and intelligent laboratory systems, 2(1-3):37–52.
- Daft-exprt: Cross-speaker prosody transfer on any text for expressive speech synthesis. In Interspeech 2022, interspeech 2022. ISCA.
- Non-parallel sequence-to-sequence voice conversion with disentangled linguistic and speaker representations. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28:540–552.
- Seen and unseen emotional style transfer for voice conversion with a new emotional speech dataset. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 920–924. IEEE.
- Emotional voice conversion: Theory, databases and esd.
- Speech synthesis with mixed emotions.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

