- The paper introduces ResGen, which directly predicts cumulative vector embeddings of masked RVQ tokens to decouple sampling complexity from sequence length and depth.
- ResGen employs a probabilistic discrete diffusion model with a hierarchical, masked prediction strategy using a mixture-of-Gaussians to enhance reconstruction fidelity.
- Experimental results on ImageNet and text-to-speech demonstrate competitive FID, WER, and CER scores with faster sampling and scalable performance.
Efficient Generative Modeling with Residual Vector Quantization-Based Tokens
Introduction
This paper introduces ResGen, a discrete diffusion model leveraging Residual Vector Quantization (RVQ) for efficient, high-fidelity generative modeling. The approach is motivated by the need to balance data fidelity and computational efficiency in generative models, particularly when scaling to high-resolution images and long audio sequences. RVQ enables compact, hierarchical token representations, but prior generative models suffer from increased sampling complexity as token depth grows. ResGen addresses this by directly predicting cumulative vector embeddings of masked tokens, decoupling sampling complexity from both sequence length and depth, and formulating the process within a principled probabilistic framework.
RVQ Tokenization and Masked Prediction
RVQ extends VQ-VAE by iteratively quantizing residuals, producing token sequences with greater depth but reduced length, thus maintaining high reconstruction fidelity. The hierarchical structure of RVQ tokens presents challenges for generative modeling, especially for autoregressive models whose sampling steps scale with the product of sequence length and depth.
ResGen introduces a masking strategy tailored for RVQ tokens, progressively masking tokens from the highest quantization layers (fine details) to the lowest (coarse features). During training, the model predicts the sum of masked embeddings at each position, rather than individual tokens, using a mixture of Gaussians to model the latent distribution. This multi-token prediction avoids conditional independence assumptions along depth and aligns with the RVQ dequantization process.
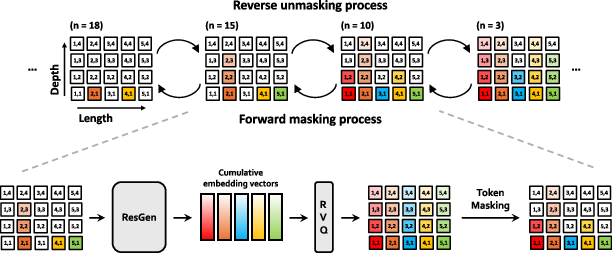
Figure 1: Overview of forward masking and reverse unmasking in ResGen, illustrating coarse-to-fine token filling via cumulative RVQ embedding prediction.
The token masking and prediction process is cast as a discrete diffusion model. The forward process incrementally masks tokens without replacement, modeled as draws from a multivariate hypergeometric distribution. The reverse process reconstructs the original sequence by iteratively predicting cumulative embeddings and quantizing them back to tokens.
The training objective is derived from the variational lower bound of the data log-likelihood, with losses corresponding to prior, diffusion, and reconstruction terms. The multi-token prediction is formalized via variational inference, focusing on the likelihood of cumulative embeddings conditioned on partially masked sequences.
Implementation Details
ResGen is implemented using a transformer backbone similar to DiT-XL, with modifications for RVQ token embedding and mixture-of-Gaussians output heads. Training involves a masking schedule that distributes masked tokens across positions and depths, and the mixture-of-Gaussians objective is decomposed into classification and regression losses to encourage diverse component usage. Low-rank projection is employed to scale the number of mixture components efficiently.
Sampling proceeds iteratively, with confidence-based unmasking guided by log probabilities derived from the mixture model. Temperature scaling and top-p sampling are used to balance diversity and fidelity.
Experimental Results
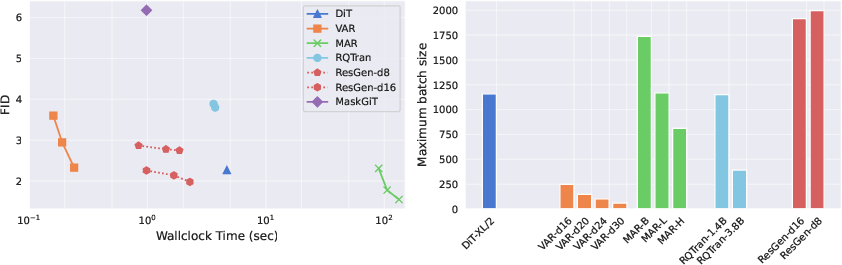
ResGen is evaluated on conditional image generation (ImageNet 256×256) and zero-shot text-to-speech synthesis. In both domains, ResGen demonstrates superior or comparable performance to autoregressive and non-autoregressive baselines, with strong trade-offs between quality, speed, and memory efficiency.











Figure 3: VAR-d30 model comparison (FID=1.92) for reference against ResGen.







Figure 4: Randomly generated 256×256 samples by ResGen trained on ImageNet, demonstrating high-fidelity synthesis.
Ablation and Sampling Analysis
Ablation studies reveal that increasing sampling steps improves generation quality, and temperature/top-p scaling can be tuned for optimal diversity and fidelity. The model achieves high-quality generation with a relatively small number of iterations, attributed to the unmasking process being easier than denoising in conventional diffusion models.
Implications and Future Directions
ResGen's decoupling of sampling complexity from token depth and sequence length enables scalable, efficient generative modeling for high-resolution images and long audio sequences. The approach is generalizable across modalities and demonstrates strong memory efficiency, making it suitable for deployment in resource-constrained environments.
Potential future directions include:
- Incorporating key-value caching in transformers to further accelerate sampling.
- Extending the framework to support alternative quantization methods such as Finite Scalar Quantization (FSQ).
- Providing a formal theoretical justification for the observed efficiency in low-step inference.
Conclusion
ResGen presents an efficient, principled approach to generative modeling with RVQ-based tokens, achieving high-fidelity synthesis without compromising speed or scalability. The direct prediction of cumulative embeddings, probabilistic formulation, and empirical results establish ResGen as a robust solution for discrete generative modeling in both vision and audio domains. The methodology opens avenues for further research in quantization strategies, transformer optimization, and theoretical analysis of discrete diffusion processes.