- The paper presents MAD-Sherlock, a multi-agent debate framework that integrates external information retrieval to verify image-text pairs for misinformation detection.
- It employs independent agent debates mimicking human discourse, achieving state-of-the-art accuracy improvements of up to 5% over benchmark datasets.
- The approach delivers coherent, evidence-based explanations that enhance user trust and offer a scalable, domain-independent solution for digital media.
Introduction
The paper "MAD-Sherlock: Multi-Agent Debate for Visual Misinformation Detection" introduces an innovative approach to tackle the pervasive problem of visual misinformation, particularly the pairing of unaltered images with misleading text. The proposed framework, MAD-Sherlock, leverages a multi-agent debate system to determine the veracity of image-text pairs. This approach is domain- and time-agnostic, achieving state-of-the-art accuracy without requiring task-specific fine-tuning. It also provides in-depth explanations, enhancing trust and facilitating adoption by users.
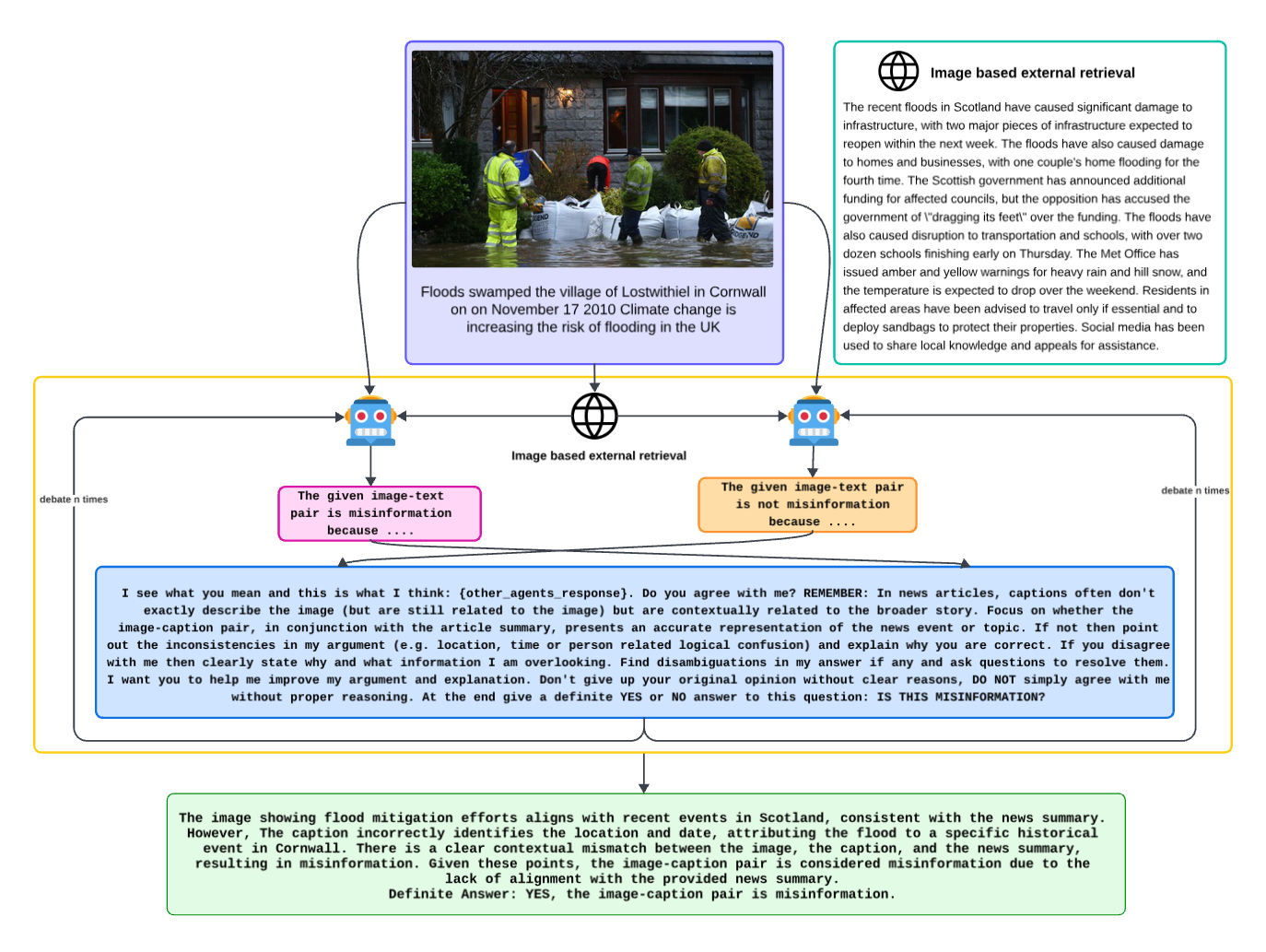
Figure 1: Overview of MAD-Sherlock: Multiple agents evaluate the same image-text pair and engage in a debate to detect misinformation.
Methodology
Debate Framework
MAD-Sherlock frames misinformation detection as a debate among multiple agents. Each agent independently assesses an image-text pair and forms an opinion. The agents then participate in a debate, where they must present and defend their positions. The debate continues until consensus is reached or a predetermined number of rounds is completed. This mimicry of human discourse allows the system to reflect diverse perspectives, improving its ability to detect subtle contextual inconsistencies.
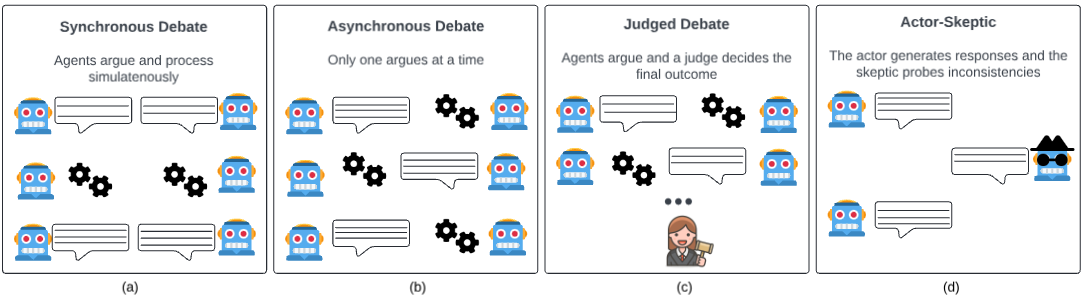
Figure 2: Debating Strategies: Various strategies were tested to determine the most effective setup for the debate.
External Information Retrieval
A crucial component of MAD-Sherlock is its external information retrieval module, which utilizes the Bing Visual Search API to gather contextual data, such as relevant articles involving the presented image. This information is summarized by a LLM (Llama-13B) and used by agents to support their arguments during the debate. This process enriches the context available to the agents, enabling a more informed debate.

Figure 3: Structure of the external information retrieval module, highlighting its integration with the debate framework.
Experiments and Results
MAD-Sherlock was evaluated on three benchmark datasets: NewsCLIPpings, VERITE, and MMFakeBench. It consistently outperformed existing methods, with accuracy improvements of 2%, 3%, and 5%, respectively, compared to the best prior approaches. This superior performance is attributed to the system's ability to provide coherent, evidence-based explanations, which were positively received in user studies. The debate framework's inherent explainability also enhances trust among users, both professionals and non-experts.
Implications and Future Directions
MAD-Sherlock's ability to detect and explain out-of-context misinformation has significant implications for combating misinformation in digital media. By offering a scalable, domain-independent solution, it can be deployed across various platforms without additional fine-tuning. Future research could explore its application to other forms of media, such as video, and its integration with multilingual capabilities. Additionally, improving the agents' ability to handle ambiguous or contradictory information sources could further enhance its robustness.
Conclusion
MAD-Sherlock represents a significant advancement in the field of misinformation detection, combining multi-agent debate with external information retrieval to achieve superior accuracy and explainability. Its design allows for adaptability across different domains, offering a promising tool for enhancing media literacy and trust in digital content. Future work should focus on expanding its capabilities and ensuring its deployment in diverse informational contexts.