- The paper demonstrates that multimodal generative models effectively fuse images and text to tackle data sparsity and cold-start challenges in recommendation systems.
- It employs techniques like GAN, VAE, and contrastive learning to align cross-modal features and improve latent representation.
- The approach offers practical benefits for applications in e-commerce, augmented reality, and personalized content marketing.
Summary of "Multi-modal Generative Models in Recommendation System"
Multimodal generative models are transforming recommendation systems by integrating multiple data modalities such as images, text, audio, and video. The advent of generative AI has elevated user expectations for richer, more interactive experiences, and these models are capable of meeting such demands by recognizing both shared and complementary information across modalities. This document explores various generative approaches to multimodal recommendation systems, detailing the challenges, methodologies, and potential applications across different sectors.
Introduction to Multimodal Recommendation Systems
The Need for Multimodal Recommendation Systems
Traditional recommendation systems typically handle different data sources independently, which limits their ability to comprehensively understand user needs — especially when new users or products are introduced. Multimodal systems bridge this gap by combining diverse information about items and users, allowing preferences to transfer from known to unknown entities. For instance, when an ecommerce platform introduces a new product without previous sales data, multimodal models can link it to existing products based on visual characteristics, thus facilitating more accurate recommendations.
Key Challenges in Designing Multimodal Recommendation Systems
Building effective multimodal recommendation systems involves several key challenges:
- Alignment Across Modalities: It's crucial to ensure that features extracted from each modality map to similar points in an embedding space, capturing both shared and complementary information.
- Data Collection: Gathering aligned data from multiple modalities is more complex, with difficulties in labeling positive pairs for contrastive learning.
- Latent Space Complexity: Generative models necessitate large datasets and resources to learn adequate latent space representations, exacerbated by cross-modal alignment requirements.
Recent advances in generative models have begun addressing these challenges through enhanced unimodal encoders and decoders and improved latent space alignment techniques.
Contrastive Multimodal Recommendation Systems
Contrastive learning methodologies align multimodal data by encouraging embeddings of similar pairs to be closer together in latent space. CLIP and other models utilize internet-scale datasets to achieve state-of-the-art results in zero-shot classification and retrieval tasks.
Contrastive Language-Image Pre-training (CLIP)
CLIP uses contrastive learning on image-text pairs to align them in a shared embedding space. It significantly scales up capabilities using extensive datasets of images and captions collected from the web, crafted to balance word occurrences effectively.
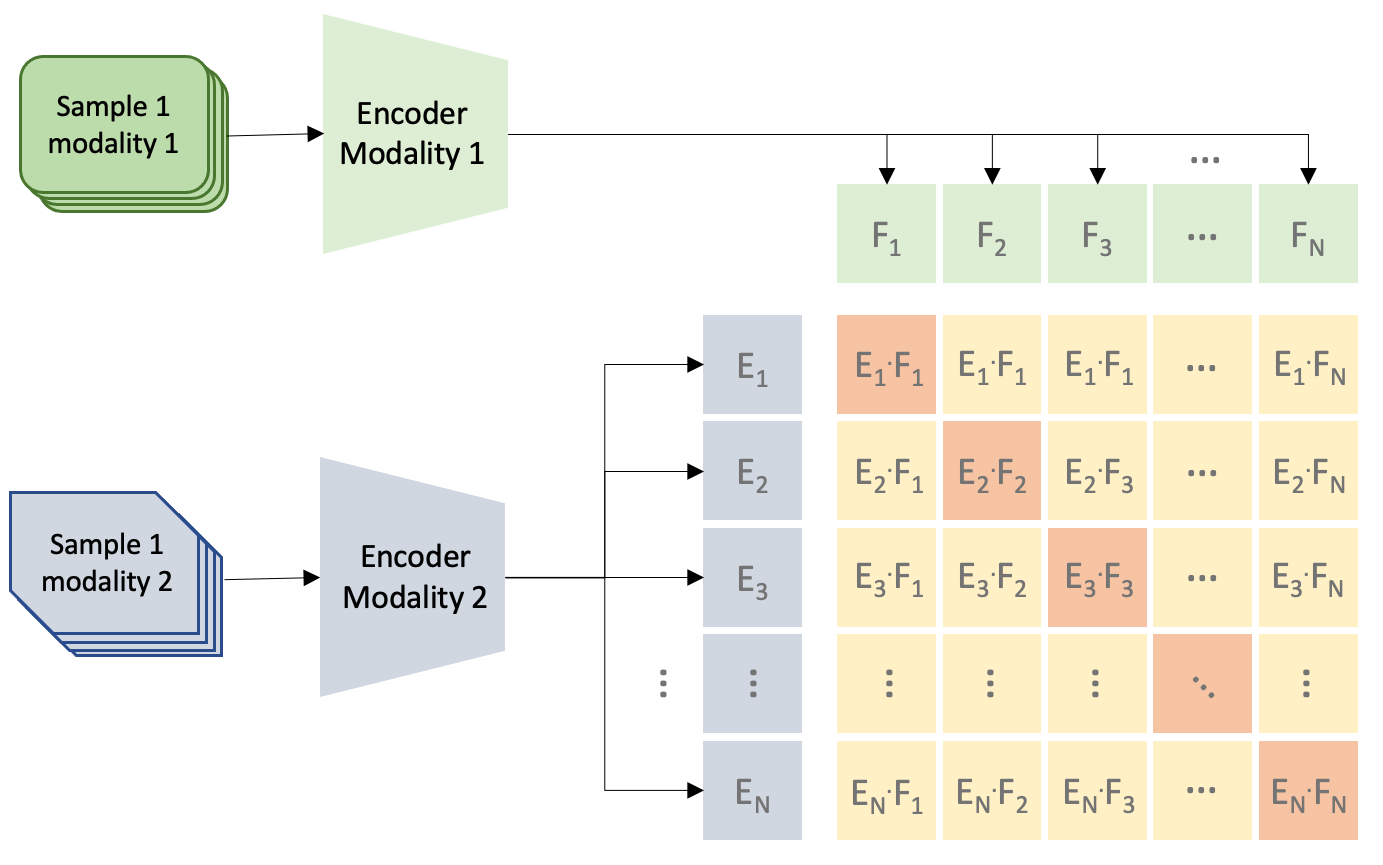
Figure 1: Contrastive pre-training used to train models such as CLIP. For each minibatch, the positive (diagonal) and negative (off-diagonal) pairs are used to compute the loss.
Other Contrastive Pre-training Approaches
Alternate methods utilize architectural innovations and unique objectives such as Align Before Fuse (ALBEF), which uses multimodal encoders and momentum distillation to improve upon strong zero-shot performance benchmarks established by CLIP.
Generative Multimodal Recommendation Systems
Generative models provide improved solutions to the inherent sparsity and uncertainty issues in recommendation data. The discussed models include GANs, VAEs, and Diffusion Models, each offering unique procedural innovations and application potential.
Generative Adversarial Networks (GANs)
GANs consist of a generator-discriminator pair where the generator creates data exemplars, and the discriminator evaluates them against real data samples. GAN applications extend to conditional models, multimodal data generation, and specific tasks like augmented reality in ecommerce.
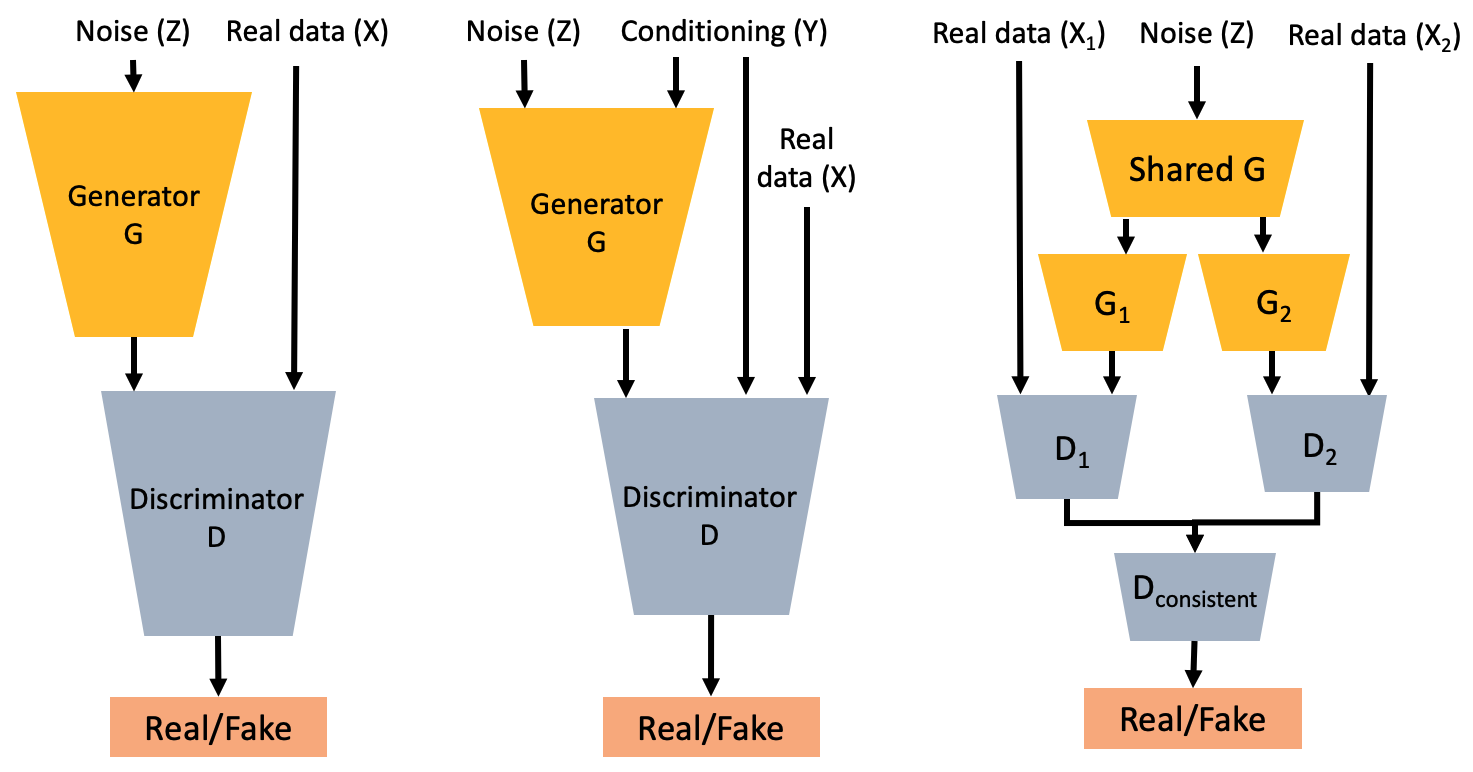
Figure 2: Generative Adversarial Networks (GANs) include a generator G that synthesizes images from latent variables, and a discriminator D that evaluates the authenticity of generated vs real images.
Variational AutoEncoders (VAEs)
VAEs encompass probabilistic encoder-decoder structures, utilizing latent space in tandem with reconstruction loss to model complex distributive representations. Multimodal extensions include shared encoder frameworks and contrastive alignment techniques, enhancing collaborative filtering and retrieval capabilities.
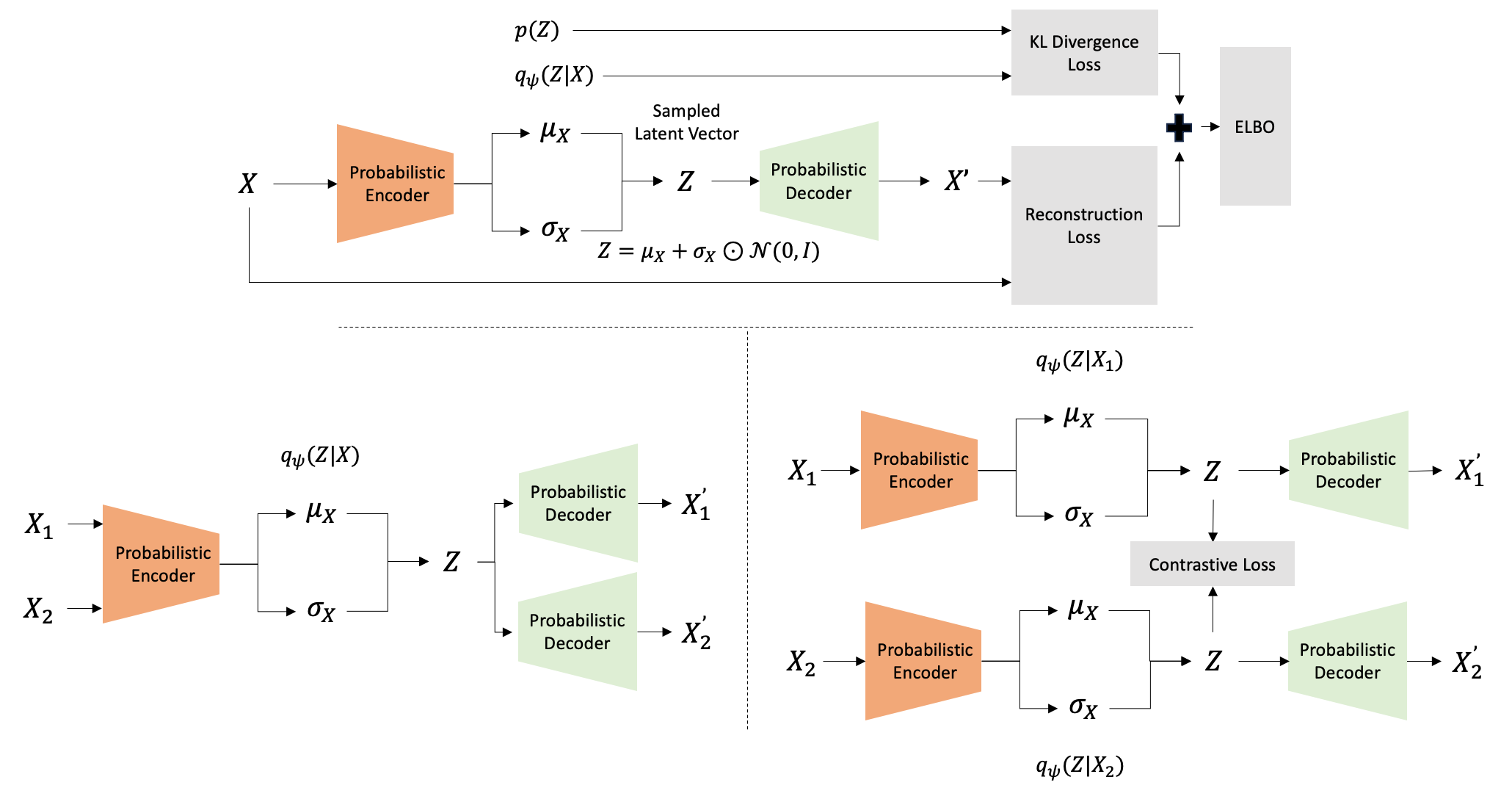
Figure 3: VAEs involve probabilistic encoders mapping inputs to latent vectors sampled to reconstruct original inputs, with modifications to support multimodal data.
Diffusion Models
Diffusion models represent an emerging paradigm in generative AI, utilizing forward and reverse processes to reconstruct original data, significantly improving generation quality for images, audio, and more.
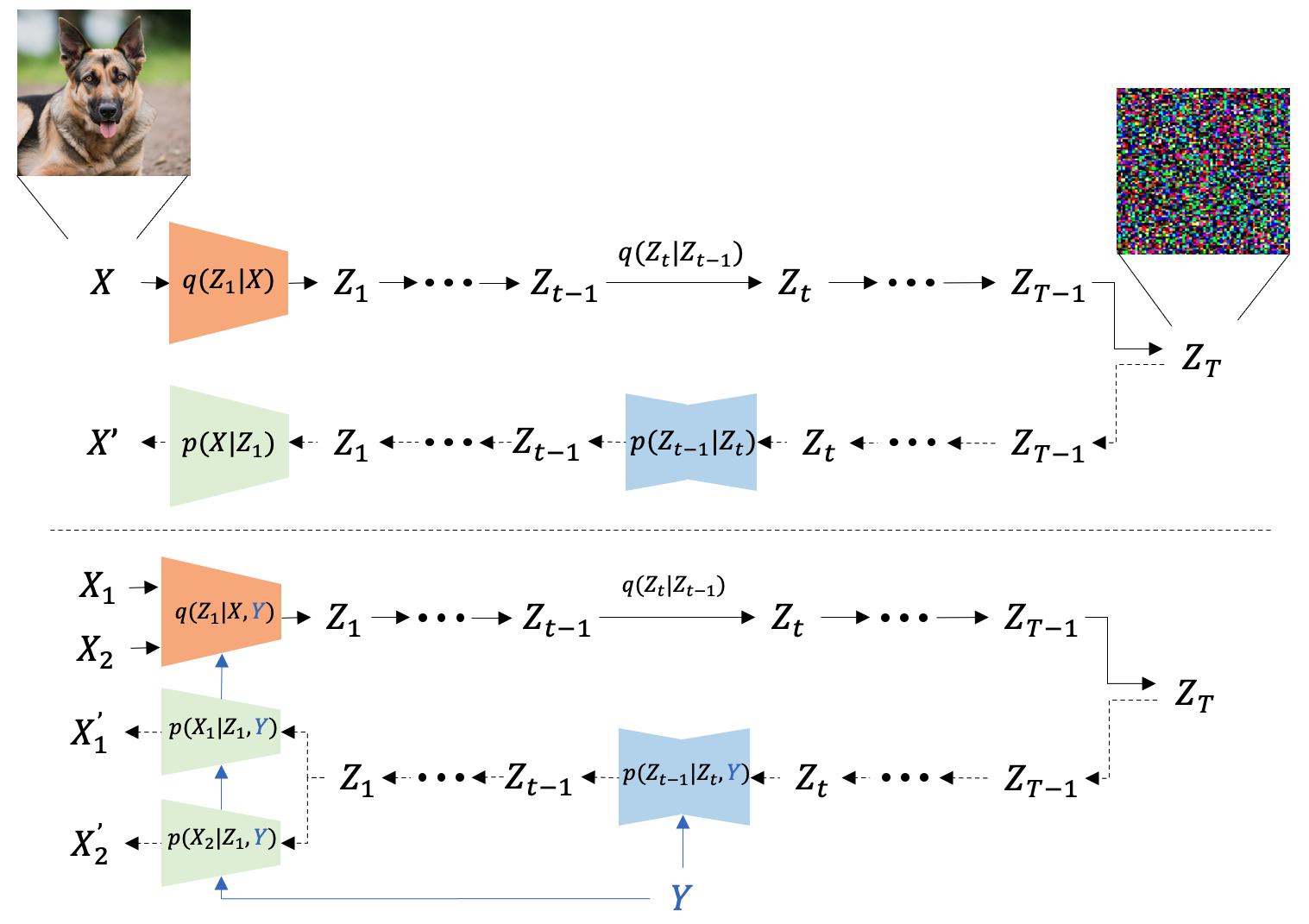
Figure 4: A diffusion model uses iterative noise addition and removal to transform samples into data channels, providing versatility across input modalities.
Interactive Multimodal Recommendation Models
Multimodal LLMs (MLLMs) extend LLM capabilities by integrating additional modalities. Architecture designs facilitate complex task-solving abilities, enabling enhanced user interaction and precise recommendations through adept handling of diverse inputs and outputs.
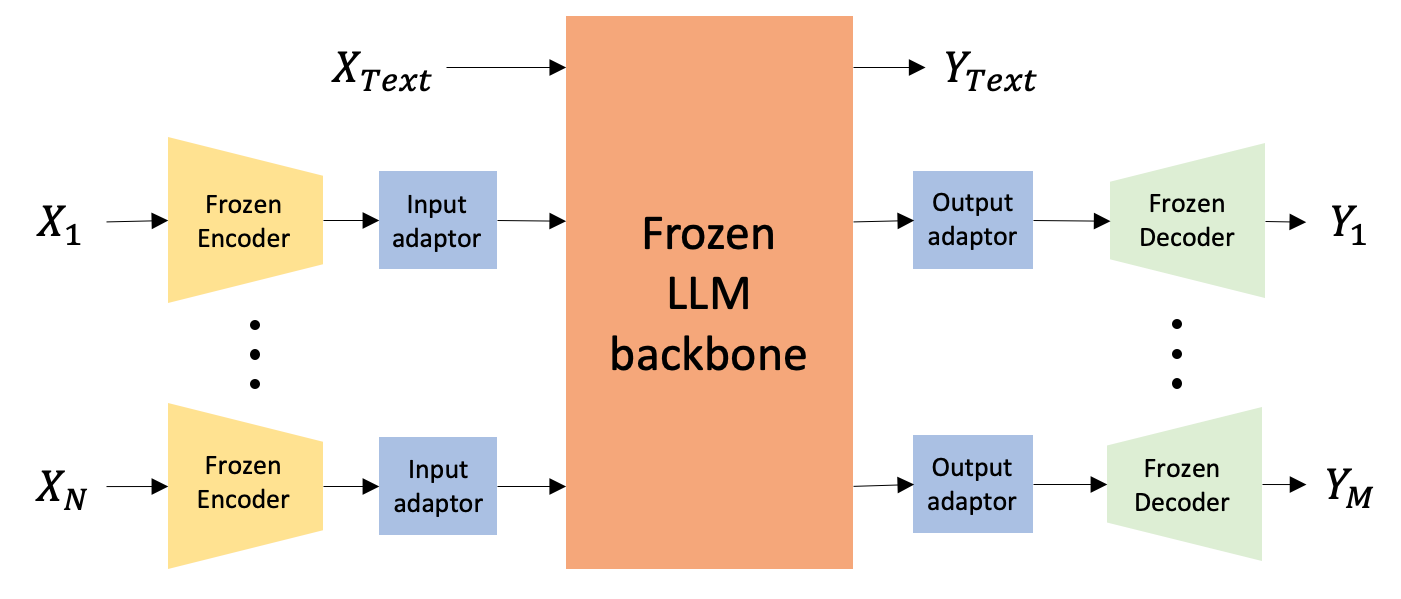
Figure 5: MLLM architectures project modality-specific features to a unified representation suitable for handling diverse input-output formats.
Applications of Multimodal Recommendation Systems
Generative multimodal systems are ripe for diverse applications:
- E-commerce: Improved product interaction with immersive experiences and visual try-ons.
- In-context Visualization: Utilizing AR and AI for better user engagement in product usage and decoration visualization.
- Marketing and Streaming: Creating personalized advertisement content and multimedia recommendations.
- Travel and Services: Offering comprehensive, contextual advice for complex event planning.
Conclusion
Multimodal recommendation systems represent a substantial leap forward in accurately mapping user preferences and delivering tailored experiences across various sectors. As generative models continue to evolve, we can anticipate even broader implementation of these technologies in enriching user interactions and enhancing system intelligence.