- The paper introduces the MQL4GRec framework that unifies multimodal item content through quantitative translators using vector quantizers and RQ-VAE.
- The paper employs novel language generation tasks combined with pre-training strategies to facilitate efficient knowledge transfer and boost NDCG performance.
- The experiments demonstrate significant improvements over baseline methods, highlighting the framework’s scalability and adaptability for sequential recommendation tasks.
Multimodal Quantitative Language for Generative Recommendation
The paper "Multimodal Quantitative Language for Generative Recommendation" presents a novel approach to enhancing generative recommendation systems through a unified multimodal quantitative language framework. This framework aims to bridge the gap between various item domains and modalities, enabling efficient knowledge transfer across recommendation tasks. The authors introduce a method named Multimodal Quantitative Language for Generative Recommendation (MQL4GRec) that leverages this unified language to improve recommendation performance by integrating multimodal information and pre-trained LLMs (PLMs).
MQL4GRec Framework
The core innovation of this work is the MQL4GRec framework, which translates item content from diverse domains and modalities into a cohesive quantitative language. This transformation utilizes quantitative translators consisting of vector quantizers that map item content into a standardized vocabulary shared across modalities (Figure 1).
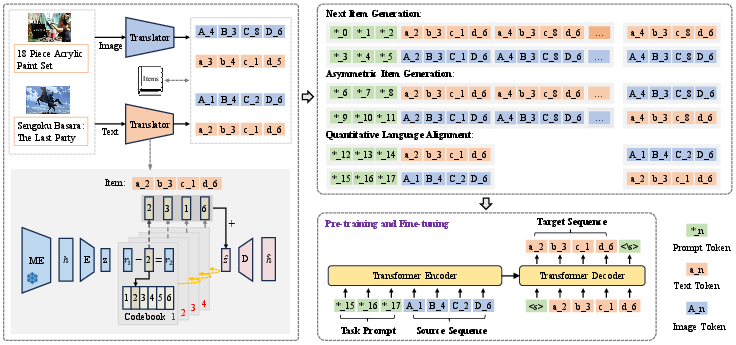
Figure 1: The overall framework of MQL4GRec. We regard the quantizer as a translator, converting item content from different domains and modalities into a unified quantitative language, thus bridging the gap between them (left). Subsequently, we design a series of quantitative language generation tasks to facilitate the transfer of recommendation knowledge through pre-training and fine-tuning (right).
Quantitative Translators
MQL4GRec employs Residual-Quantized Variational AutoEncoders (RQ-VAE) to process item embeddings from multiple modalities, like text and image, into discrete token representations in the quantitative language. The RQ-VAE encodes high-dimensional data into a sequence of codewords (tokens) that form the vocabulary for representing items.
Quantitative Language Generation Tasks
The framework supports various language generation tasks, including Next Item Generation and Asymmetric Item Generation, to enrich the quantitative language with semantic and domain knowledge. Additionally, it incorporates tasks for Quantitative Language Alignment to ensure cohesive integration of semantic information across modalities.
Experimental Results
The framework was evaluated across multiple datasets in the context of sequential recommendation tasks. The experiments demonstrated significant improvements over baseline methods like TIGER, VIP5, and P5-CID, achieving notable gains in NDCG metrics across diverse datasets (Table 1). The improvements are attributed to the enhanced knowledge transfer capability facilitated by the unified language representation and task design.
Impact of Pre-training
The paper further explored the impact of pre-training datasets and epochs on recommendation performance. Results indicated that pre-training on larger and varied datasets enhances the model's performance by leveraging rich semantic information for generative purposes. However, pre-training too extensively without proper task alignment may lead to overfitting, as observed in variations across different datasets (Figures 2 and 3).
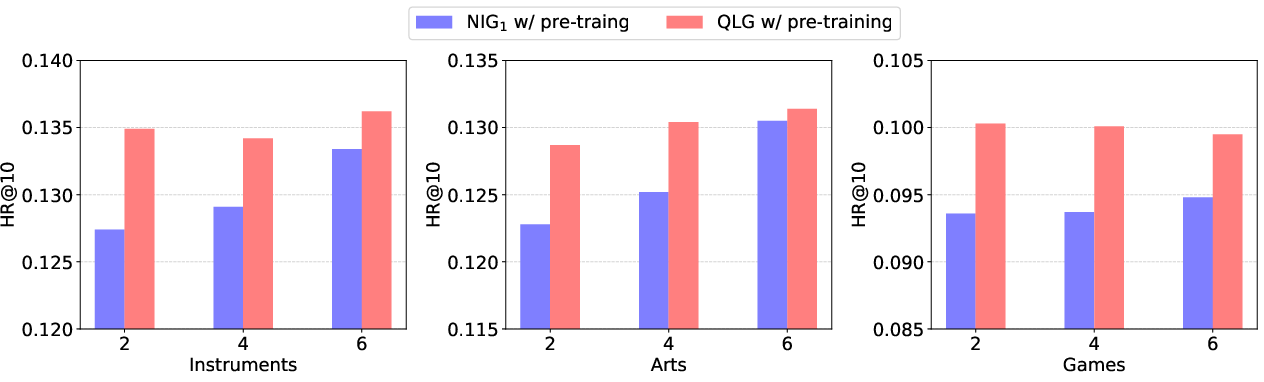
Figure 2: The impact of varying amounts of pre-training datasets on recommendation performance.
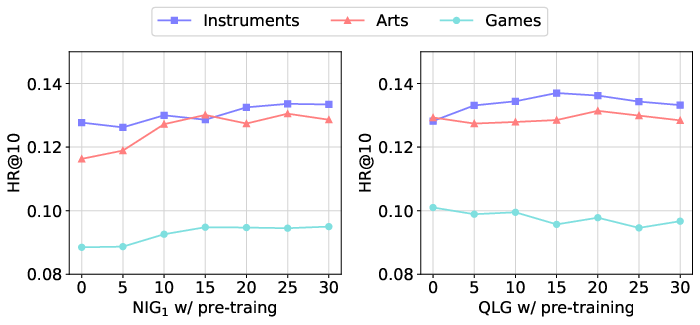
Figure 3: The impact of different pre-training epochs on recommendation performance.
Implementation Considerations
Handling of Collisions
An advanced token reallocation method is proposed to handle item collisions caused by similar modality information. This method reallocates tokens based on distance metrics, ensuring unique representation across items.
Deployment and Scalability
The devised approach emphasizes scalability due to its reliance on a shared and concise vocabulary, reducing the computational overhead typical in dealing with complex multimodal content.
Conclusions
The MQL4GRec framework signifies an advancement in generative recommendation systems by intricately integrating multimodal information into a uniform language representation that enhances knowledge transfer and recommendation performance. Future avenues involve optimizing the inference efficiency of the generative models and further exploring scenarios with incomplete multimodal content information. This work paves the way for more universal and adaptable recommendation systems that leverage complex multimodal data effectively.