- The paper proposes leveraging fine-tuned LLMs to create interactive Linux honeypots that replicate realistic server behavior and thwart adversarial detection.
- Methodology features synthesizing diverse datasets, specialized prompts for terminal emulation and expert modes, and efficient fine-tuning with LoRA and QLoRA.
- Experimental results reveal rapid model convergence and improved output similarity metrics, highlighting the potential for scalable, adaptive cyber defense.
LLM Honeypot: Leveraging LLMs for Advanced Interactive Honeypot Systems
Introduction and Motivation
Traditional honeypots, while essential in cyber defense, have long been limited by predictable interaction patterns and superficial emulation that render them vulnerable to detection by sophisticated adversaries. Low-interaction honeypots, in particular, suffer from constrained behavioral simulation, making them susceptible to fingerprinting and restricted information collection. To address these limitations, this work proposes leveraging fine-tuned LLMs to revolutionize honeypot realism and interactivity, enabling adaptive, high-fidelity emulation of Linux server behavior.
Methodology
Data Collection, Processing, and Model Training
A comprehensive dataset is foundational to achieving the behavioral realism needed for LLM-powered honeypots. The paper synthesizes data from three distinct sources:
- Real-world attack data: SSH and Telnet command logs from Cowrie honeypot deployments.
- Common command coverage: The top 100 frequently used Linux commands, augmented with manual variations.
- Command-explanation pairs: Over 283 man page summaries and explanations.
All data underwent rigorous preprocessing, including tokenization and format standardization, to facilitate high-quality supervised fine-tuning.
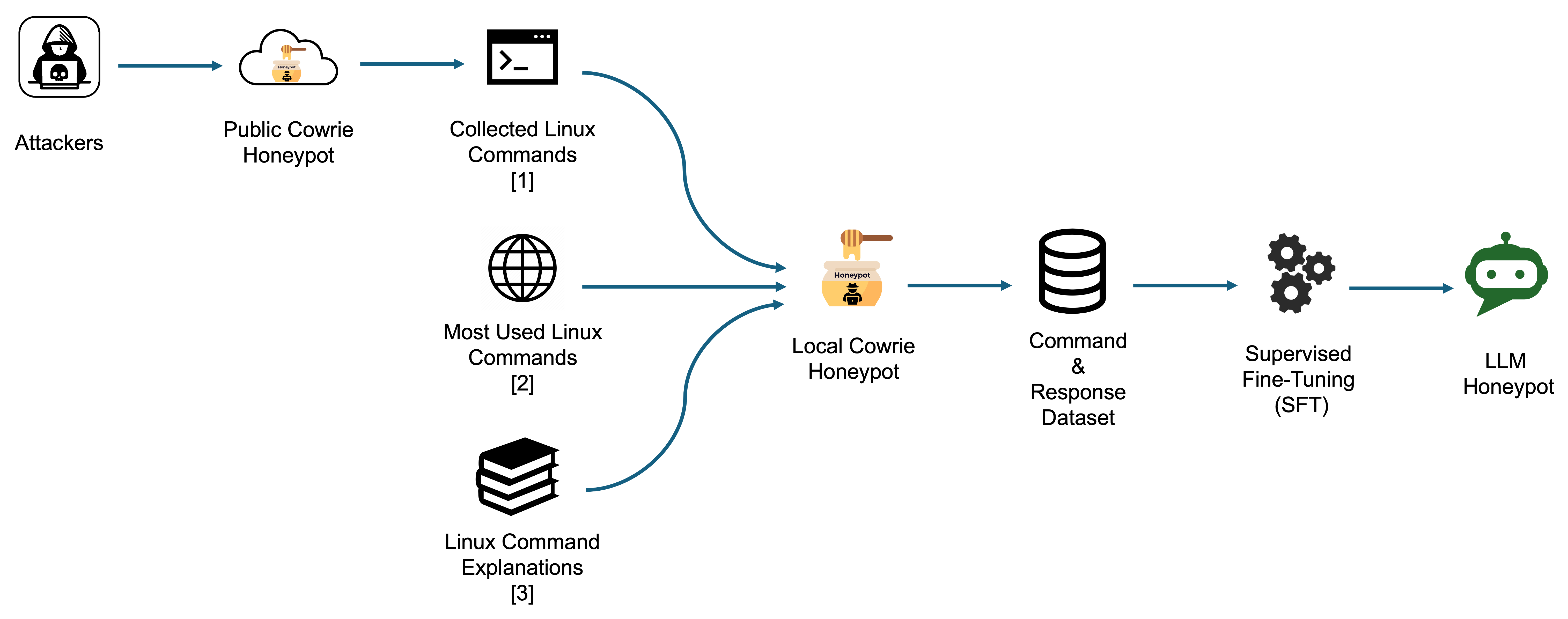
Figure 1: Data collection and model training pipeline for LLM honeypot development, integrating attacker logs, common Linux commands, and explanatory data.
Prompt Engineering and Command Role Allocation
Building on analysis of prior works, the study designs specialized prompts to steer model behavior under two operational roles:
- Linux terminal emulation: System prompts restrict responses to code blocks replicating pure terminal output, eliminating extraneous explanation.
- Linux expert mode: Prompts instruct the model to explicate commands, enhancing its understanding depth for complex interactions.
Model Selection and Fine-Tuning Techniques
The pipeline evaluates multiple recent LLM architectures including Llama3, Phi 3, CodeLlama, and Codestral. Code-centric models were less effective in general server simulation; performance-speed tradeoffs favored Llama3 8B for deployment practicality. Fine-tuning utilizes LoRA for parameter-efficient adaptation, QLoRA for 8-bit quantization, NEFTune for regularization, and Flash Attention 2 for computational optimization on longer contexts.
Interactive LLM-Honeypot Deployment Architecture
To bridge the gap between text generation and real network protocol interaction, the system integrates a custom SSH server wrapper using Paramiko. Incoming SSH traffic is processed at the IP layer, with all commands executed via the LLM model. The framework enables live attacker engagement, with full logging of IP addresses, credentials, and command-response histories for post-hoc behavioral profiling.

Figure 2: Interactive SSH-LLM honeypot server framework enabling attacker engagement, fine-tuned LLM inference, and advanced logging for behavioral analysis.
System Operation and Live Engagement Example
Live tests validate the functionality of the custom SSH server, with the fine-tuned LLM reliably producing authentic Linux responses under various attack scenarios.
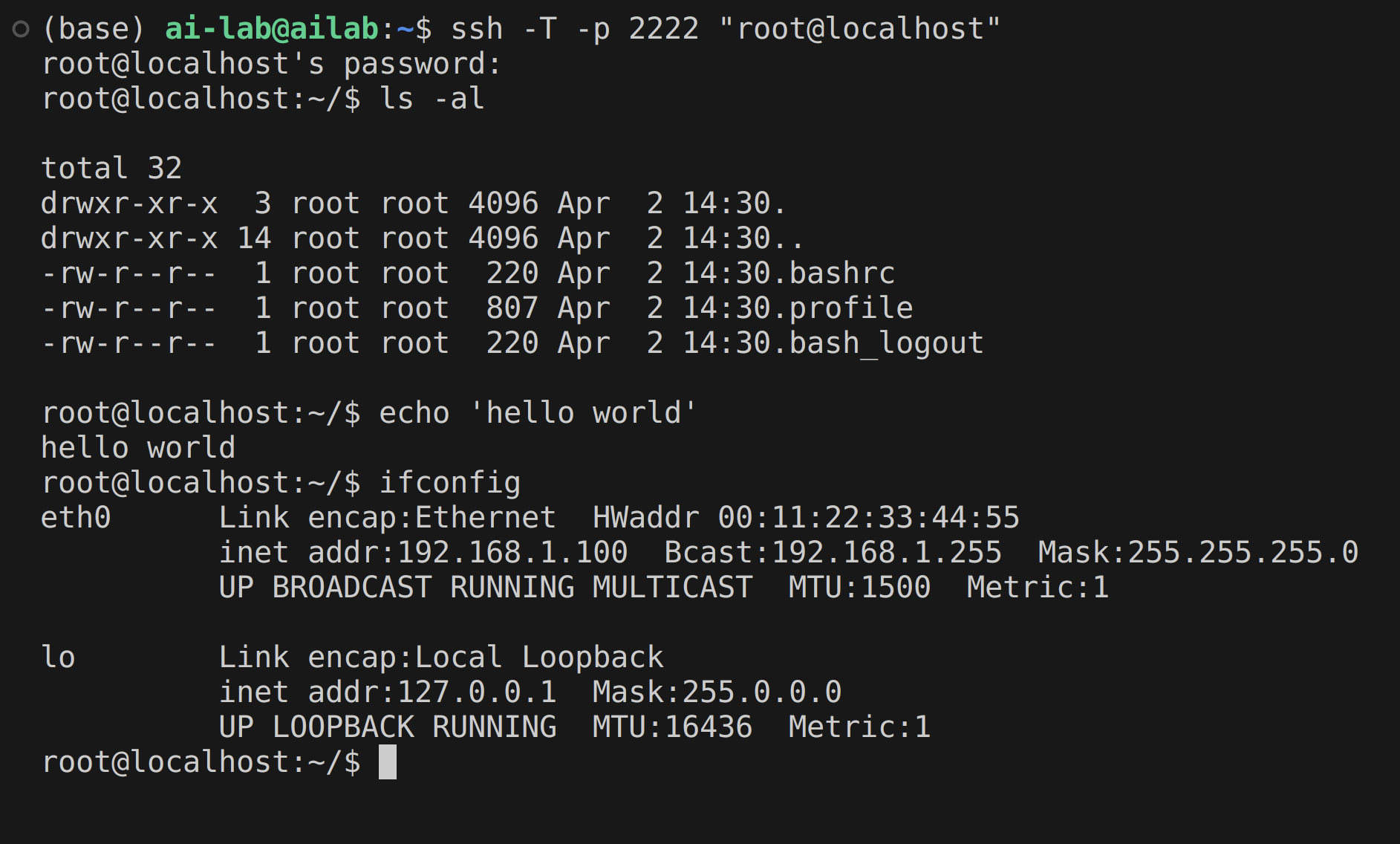
Figure 3: Example SSH honeypot interaction, demonstrating realistic command processing and output synthesis by the LLM-driven server.
Experimental Results
Training Loss Analysis
The model's training loss trajectory demonstrates rapid convergence over 36 SFT steps, completed within 14 minutes using dual RTX A6000 GPUs—achieving performance efficiency commensurate with practical deployment requirements.
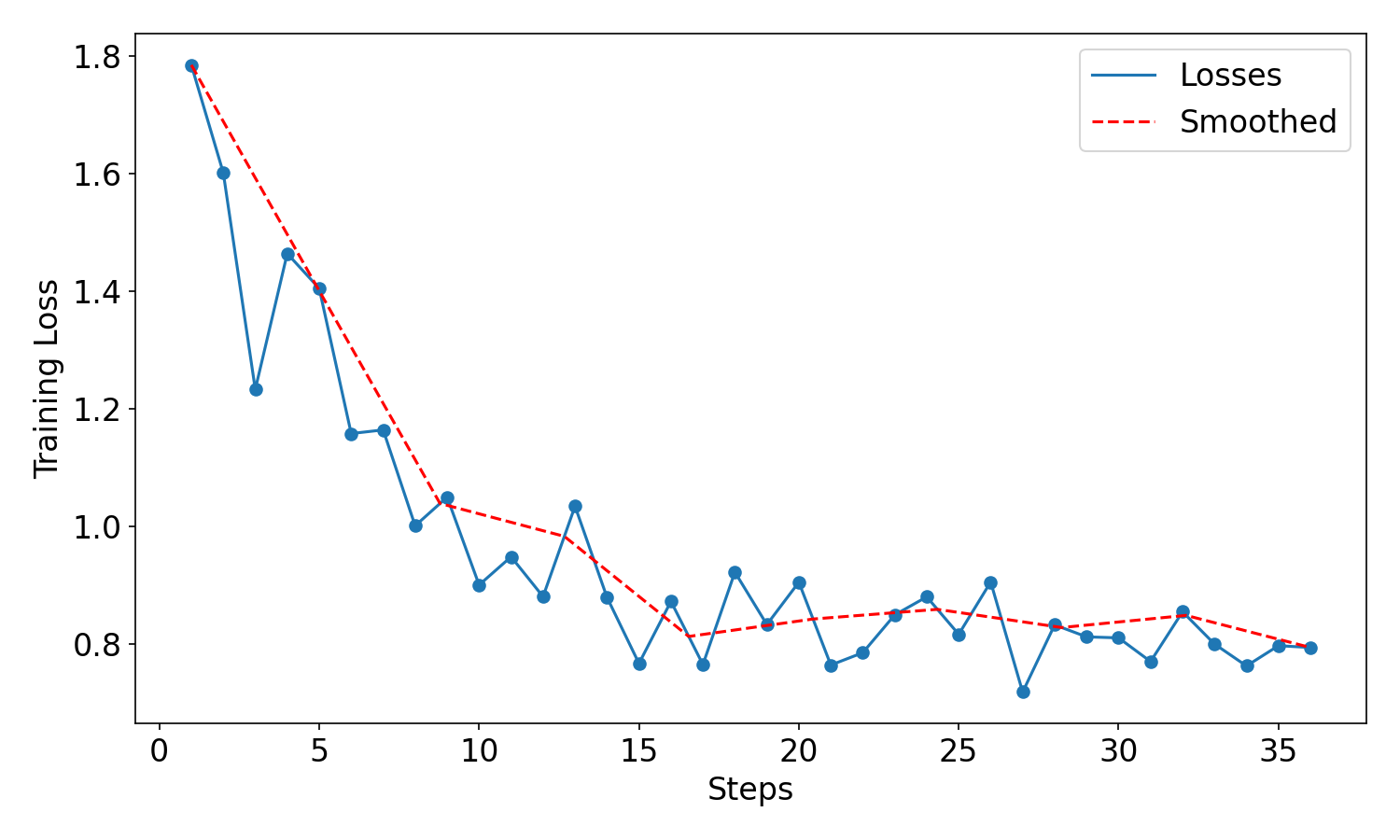
Figure 4: Training loss curve evidencing efficient learning and stable convergence during supervised fine-tuning.
Output Similarity Evaluation
Quantitative analysis employs cosine similarity, Jaro-Winkler similarity, and Levenshtein distance to compare generated outputs against Cowrie reference responses across 140 samples. The fine-tuned LLM achieved a mean cosine similarity of 0.695 (base: 0.663), Jaro-Winkler 0.599 (base: 0.534), and Levenshtein 0.285 (base: 0.332). These results signify statistically strong fidelity in replicating authentic server behavior, with strict prompt and training guardrails ensuring correct handling of invalid or out-of-distribution commands.
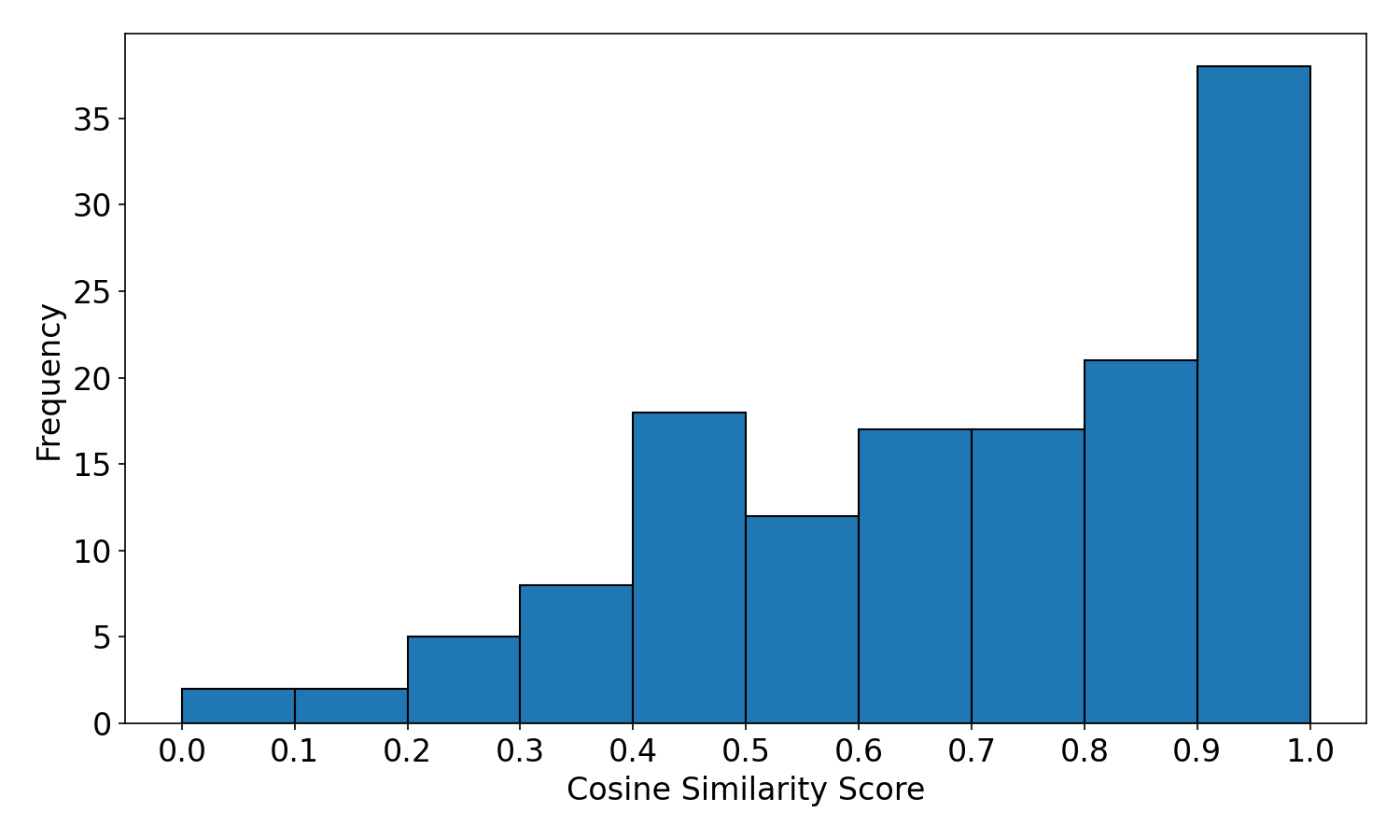
Figure 5: Histogram distribution of cosine similarity scores for 140 output samples, indicating predominance of high-fidelity terminal responses.
Implications and Future Directions
The demonstrated approach advances the state of honeypot technology by achieving realistic, dynamic engagement unattainable via rule-based or static emulation. LLM-driven honeypots can integrate adversarial learning, continuous online adaptation, and multi-role persona management, making detection by adversaries increasingly difficult.
Practically, such honeypots can scale to cloud environments for wide-area surveillance, ingest novel attack patterns, and support automated incident response pipelines. Theoretically, the work underscores the emerging paradigm in cybersecurity utilities—where foundation models, with codified behavioral guardrails, offer extensible simulation for TTP (Tactics, Techniques, and Procedures) analysis and threat intelligence. Research can progress toward:
- Online model retraining for unknown threat vectors.
- Cross-protocol honeypot simulation leveraging multimodal LLM architectures.
- Integration with XDR (Extended Detection and Response) frameworks for seamless threat ecosystem analysis.
Conclusion
By harnessing fine-tuned LLMs coupled with advanced prompt engineering and efficient deployment architectures, this research introduces a paradigm shift in honeypot design—delivering high-interaction, adaptive, and automated decoy systems capable of robust attacker engagement and behavioral analysis. The positive empirical results and extensible system design position LLM honeypots for significant practical adoption, informing future AI-driven developments in proactive cyber defense.
(2409.08234)