Grasp Any Region: Towards Precise, Contextual Pixel Understanding for Multimodal LLMs
Abstract: While Multimodal LLMs (MLLMs) excel at holistic understanding, they struggle in capturing the dense world with complex scenes, requiring fine-grained analysis of intricate details and object inter-relationships. Region-level MLLMs have been a promising step. However, previous attempts are generally optimized to understand given regions in isolation, neglecting crucial global contexts. To address this, we introduce Grasp Any Region (GAR) for comprehen- sive region-level visual understanding. Empowered by an effective RoI-aligned feature replay technique, GAR supports (1) precise perception by leveraging necessary global contexts, and (2) modeling interactions between multiple prompts. Together, it then naturally achieves (3) advanced compositional reasoning to answer specific free-form questions about any region, shifting the paradigm from passive description to active dialogue. Moreover, we construct GAR-Bench, which not only provides a more accurate evaluation of single-region comprehension, but also, more importantly, measures interactions and complex reasoning across multiple regions. Extensive experiments have demonstrated that GAR-1B not only maintains the state-of-the-art captioning capabilities, e.g., outperforming DAM-3B +4.5 on DLC-Bench, but also excels at modeling relationships between multiple prompts with advanced comprehension capabilities, even surpassing InternVL3-78B on GAR-Bench-VQA. More importantly, our zero-shot GAR-8B even outperforms in-domain VideoRefer-7B on VideoRefer-BenchQ, indicating its strong capabilities can be easily transferred to videos.
First 10 authors:




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
The paper introduces a new AI system called Grasp Any Region (GAR). It helps computers look at pictures more like people do: not just seeing the whole image, but also understanding any specific part you point to, while still using the bigger scene for context. It also presents GAR-Bench, a set of tests to check how well AIs understand specific parts of an image and the relationships between them.
What the researchers wanted to achieve
In simple terms, they aimed to:
- Help AI describe any chosen area in an image accurately, not just the whole image.
- Make sure the AI uses the whole scene’s context so it doesn’t get fooled (for example, not mistaking a frog-shaped slipper for a real frog).
- Let the AI reason about several chosen areas at once, like figuring out who is riding what, or which object is next to which.
- Build better tests (GAR-Bench) to fairly measure these skills, including both basic details and harder “put-things-together” questions.
How GAR works (explained simply)
Think of GAR like a smart detective with two superpowers:
- a wide-angle view to understand the whole scene,
- a magnifying glass to closely examine any area you care about.
Here’s the approach, using everyday language:
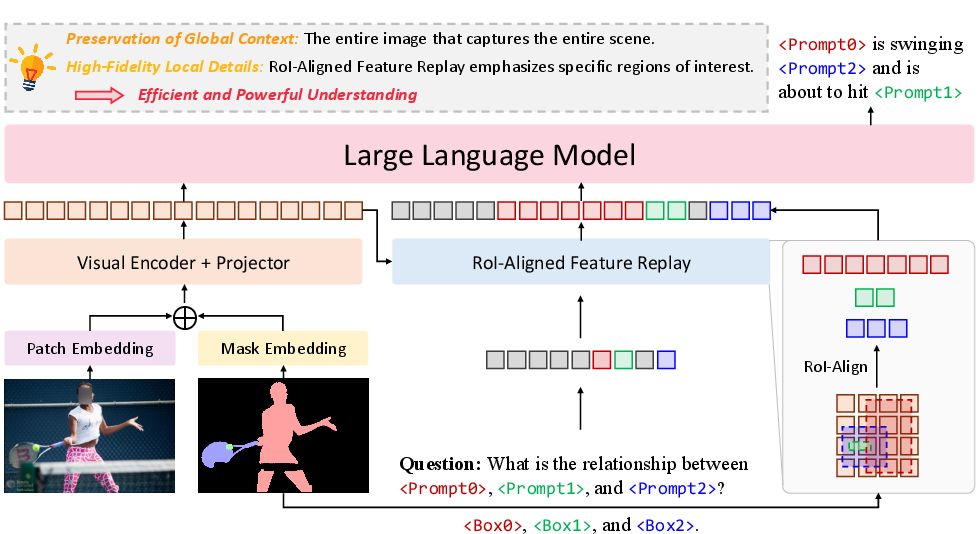
- Picking regions (“visual prompts”): You can mark one or more parts of an image (like coloring them in). These colored-in areas are called “masks.” They tell the model, “Focus here!”
- Keeping the big picture: Instead of cropping only the marked area, GAR first looks at the full image so it knows what’s happening around the area. This avoids silly mistakes caused by missing context.
- RoI-aligned feature replay (friendly analogy): “RoI” means “Region of Interest.” Imagine you have a big map of the whole city (the full image) with lots of useful details. RoI-Align is like cutting out a precise, well-aligned mini-map of just your neighborhood (your chosen region) from that big map. You keep all the local details but also keep them consistent with the bigger city map. “Feature replay” just means feeding those precise region details back into the LLM so it can talk about them clearly.
- Talking about multiple regions together: You can point to many areas at once (for example, a person and a bicycle), and GAR will figure out their relationship (like “the person is riding the bicycle”).
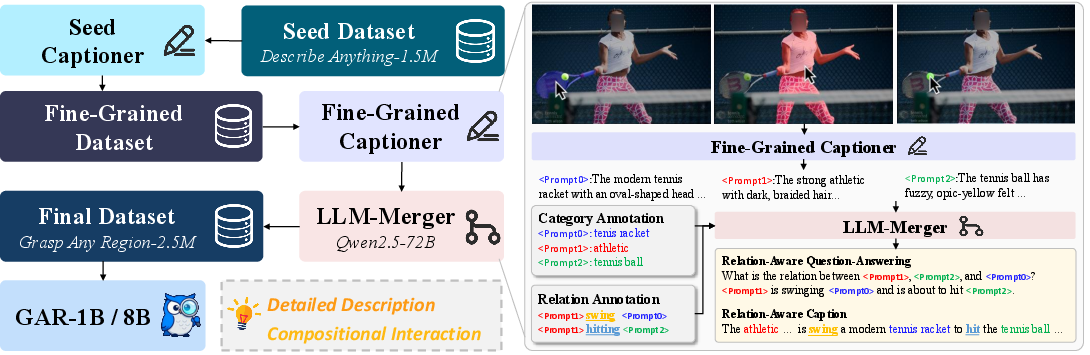
- Training data, in simple steps:
- First, they taught GAR to recognize fine-grained object details (using big image collections with very specific labels).
- Next, they taught it about relationships between objects (who is holding what, what’s next to what, etc.) by using a dataset that includes both objects and how they connect.
What they built to test it (GAR-Bench)
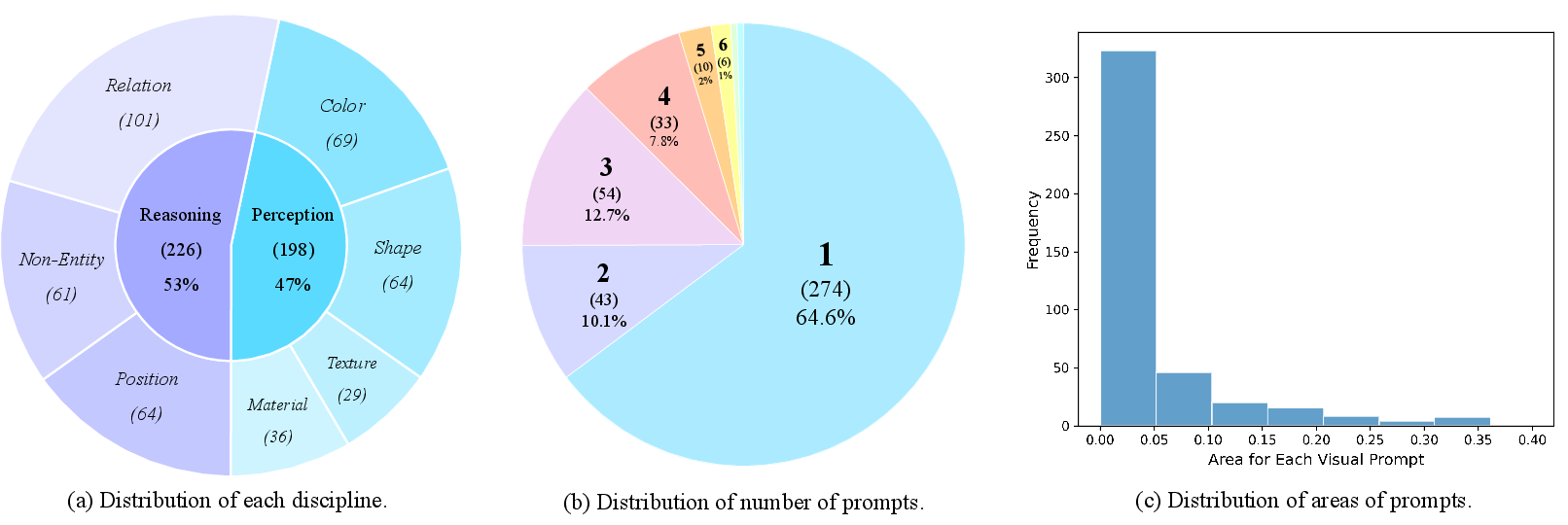
To check these skills properly, the team made GAR-Bench with two parts:
- GAR-Bench-Cap (Captioning): Tests whether the model can describe relationships between multiple marked regions (like “Prompt A is sitting on Prompt B”), not just describe each object separately.
- GAR-Bench-VQA (Question Answering): Asks questions about:
- Perception: basic attributes of a marked thing (color, shape, material, texture).
- Reasoning: trickier stuff like position in a group (e.g., “second from the left”), spotting non-real things (reflections, shadows, screens), and understanding relationships between several marked regions at the same time.
Main results and why they matter
Here are the key takeaways, explained plainly:
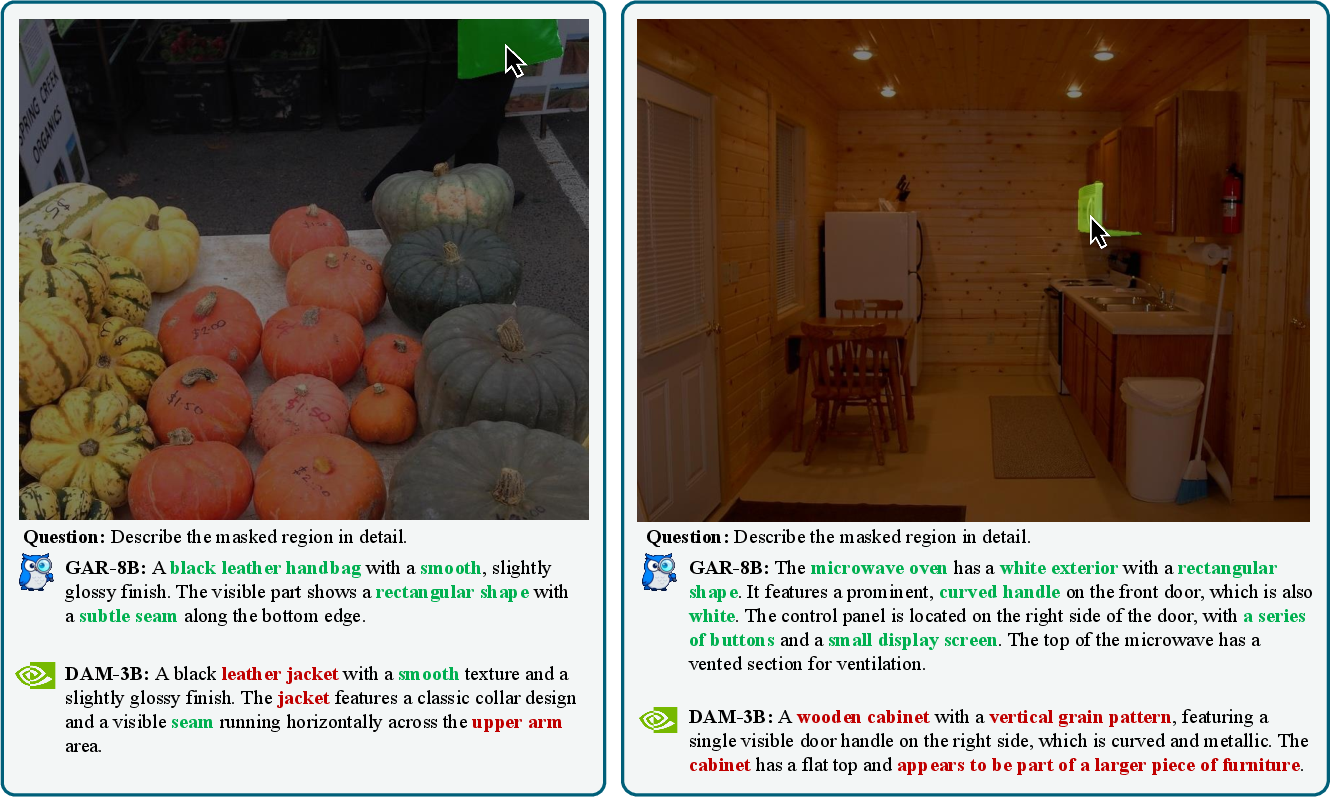
- Better at region-level understanding: GAR creates more precise captions for marked areas than earlier methods, because it uses the full scene for context and doesn’t rely only on crops.
- Strong multi-region reasoning: GAR can understand how multiple selected areas relate to each other, even when there are distracting regions. On the new GAR-Bench tests, the small GAR-1B model beat some much larger public models at multi-region understanding, and GAR-8B performed even better.
- Great at fine-grained details: GAR did especially well on questions about textures and detailed attributes, showing it captures small visual clues.
- Competitive with very large models: Despite being smaller, GAR sometimes outperformed powerful, much larger models on the new benchmarks for region understanding and relationship reasoning.
- Works on videos without extra training: Even though GAR was trained on images, it transferred surprisingly well to video tasks (by sampling frames). In some tests, it even beat a model trained specifically for video regions. This suggests GAR’s “look-wide-and-zoom-in” strategy is robust.
Why this research matters
- More accurate image understanding: From describing the exact pattern on a shirt to telling that a “person” in a mirror is just a reflection, GAR reduces common misunderstandings caused by missing context.
- Smarter multi-object reasoning: Many real-world tasks need understanding of how things interact (people using tools, traffic situations, or items arranged on shelves). GAR’s ability to reason about relationships is a big step forward.
- Better, fairer evaluation: GAR-Bench offers clearer, more realistic tests of what region-aware AI can actually do, encouraging progress on skills that matter in practice.
- Practical impact: This approach could improve image search, photo editing helpers, accessibility tools (describing specific parts of a scene for visually impaired users), robotics (grasping or navigating around objects), and video understanding (sports analysis, security, education).
In short, GAR helps AI “grasp any region” by keeping both the small details and the big picture in mind, making its descriptions and answers more precise, more contextual, and more useful.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, written to be concrete and actionable for follow-up research.
- Lack of native temporal modeling: video results are obtained by frame sampling without temporal reasoning; develop cross-frame region encoders, temporal RoI replay, and motion-aware relation modules to handle tasks like temporal description and future prediction.
- Scaling to many prompts: the approach claims “arbitrary” prompts but does not characterize accuracy, memory, or latency when handling dozens/hundreds of regions; systematically measure compute vs. performance trade-offs and design scalable multi-prompt aggregation.
- Overlapping and nested regions: behavior with overlapping, nested, or heavily occluded prompts is not evaluated; introduce hierarchical/graph reasoning and conflict resolution for shared pixels and part–whole relations.
- RoI feature extraction fidelity: using bounding-box RoI-Align for masks may mix background and lose fine boundaries; compare masked RoI pooling, deformable RoI, soft mask attention, or point-based sampling to retain precise shape information.
- Context window requirements: the amount and type of global context needed for different tasks is not quantified; ablate AnyRes tiling, resolution, and context radius to identify minimal context for robust region disambiguation.
- Robustness to prompt noise: sensitivity to imperfect masks (inaccurate, sparse, noisy, adversarial, or partial masks) is not studied; stress-test with controlled mask perturbations and add robustness objectives/augmentations.
- Compositional generalization: generalization to unseen combinations of objects, relations, and attributes is not measured; create held-out compositional splits (objects × relations × contexts) and evaluate zero-shot recomposition.
- Positional/ordinal reasoning weakness: “Position” scores lag notably; devise explicit grid/ordinal encodings, counting modules, or structural priors to improve row/column and rank identification in groups.
- Non-entity recognition coverage: the scope and failure modes (e.g., reflections vs. screens vs. posters vs. AR overlays vs. mannequins) are not deeply analyzed; expand and stratify non-entity categories with hard negatives and report per-type performance.
- Multi-turn interaction: the method is optimized for single-turn queries; investigate multi-turn region-centric dialogue, iterative refinement of prompts, and tool use (e.g., segment-then-reason loops).
- Prompt modality breadth: only binary masks are supported; extend to points, scribbles, polygons, bounding boxes, referring expressions, and mixed-modal prompts, and study cross-prompt consistency.
- Data generation bias and noise: large portions of training data (fine-grained and relational) are synthesized/validated by LLMs; quantify hallucination, bias, and label noise, and assess benefits of human verification or stronger cross-checking.
- Benchmark judge dependency: GAR-Bench captioning relies on GPT-4o judging; measure inter-judge agreement (LLM vs. human vs. alternative LLMs), release rubrics, and include a human-rated subset for calibration.
- Benchmark coverage and scale: clarify dataset size, domain diversity, and difficulty; add occlusion-heavy, crowded, long-tail categories, and cross-lingual prompts to test generality and fairness.
- Potential train–test contamination: PSG-derived training data and GAR-Bench might share sources or visual distributions; explicitly audit and document image/source overlap and enforce strict separation.
- Uncertainty and calibration: the model does not report confidence over region-level answers; add calibrated uncertainty estimates, abstention, and selective answering for safety-critical settings.
- Efficiency reporting: no end-to-end compute, memory, or latency results are provided for high-resolution AnyRes plus multi-prompt RoI replay; benchmark throughput and optimize for real-time/edge deployments.
- Backbone/architecture sensitivity: effects of different vision encoders, multi-scale features, or fusion strategies (gating, cross-attention, token budgeting) are not explored; provide systematic ablations beyond the cited table.
- Scene-graph completeness: relations may be largely pairwise from PSG; study higher-arity and long-chain relational reasoning (≥3 prompts), distractor-dense scenes, and full scene-graph extraction quality.
- Domain transfer limits: outside of photos and limited video, performance on documents, UI/screens, medical, aerial/remote sensing, cartoons, or synthetic data is unknown; conduct domain-shift evaluations and adaptation studies.
- Safety and bias at region level: risks in localized descriptions (e.g., identity attributes, stereotypes) are not audited; add fairness/privacy analyses and region-aware content moderation.
- Video prompt tracking: the method does not address how region prompts persist across frames; develop mask propagation/tracking and temporal consistency losses for long videos beyond 16 frames.
- Training objectives: learning is primarily language modeling; test auxiliary objectives (contrastive grounding, relation classification, mask-aware feature alignment) to strengthen localization and relations.
- Evaluation metrics for relational captioning: reliance on LLM judges masks metric design gaps; propose reproducible, reference-based or structured metrics for relation correctness, grounding, and factuality.
- Failure-mode taxonomy: a systematic error analysis (e.g., small objects, fine texture, heavy clutter, lighting, atypical viewpoints) is missing; publish a taxonomy and targeted stress-tests to guide future improvements.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging GAR’s RoI-aligned feature replay, multi-prompt interaction, and strong region-level captioning/VQA performance. Each item includes the sector, typical tools/workflows that could emerge, and key assumptions/dependencies.
- Bold: Region-aware accessibility and alt-text generation (Accessibility, Publishing, Education)
- Use GAR to generate precise, context-aware descriptions of selected regions in images and multi-panel graphics (e.g., charts, UI screenshots, scientific figures), improving screen-reader experiences and compliance with accessibility standards.
- Tools/workflows: CMS plug-ins and browser extensions where users or automated segmentation tools (e.g., SAM) select regions and GAR returns detailed, relation-aware captions; batch processing for large content libraries.
- Assumptions/dependencies: Reliable mask/ROI creation (human or auto-segmentation), adequate image resolution, OCR integration for text-rich screenshots, human review for compliance and tone.
- Bold: Product attribute extraction and listing enrichment (Retail/e-commerce)
- Extract fine-grained attributes (color, shape, texture, material) and relations (e.g., “person is holding the bag”) from product photos to automate catalog tagging, recommendations, and search enrichment.
- Tools/workflows: PIM enrichment pipelines combining detector/segmenter (e.g., boxes→SAM masks) with GAR to produce structured attributes and relation-aware captions; verification UI for merchandisers.
- Assumptions/dependencies: Domain adaptation for product categories and studio imagery, consistent photography, robust OCR if packaging text is needed.
- Bold: Visual QA in manufacturing quality control (Manufacturing)
- Operators highlight suspected defects or assemblies; GAR provides precise descriptions and relational checks (e.g., “fastener A misaligned with bracket B”), and filters non-entities (reflections/shadows) to reduce false positives.
- Tools/workflows: Tablet-based inspection apps with mask selection; GAR-driven checklists; integration with MES/QMS.
- Assumptions/dependencies: High-resolution imagery, domain-specific fine-tuning for defects/parts, reliable segmentation of components, controlled lighting.
- Bold: Content moderation and compliance auditing (Media, Policy)
- Identify policy-relevant regions (logos, sensitive content, disclaimers) and generate contextual rationales considering relationships across multiple prompts (e.g., “text disclaimer is occluded by object X”).
- Tools/workflows: Moderation dashboards that propose masks from detectors; GAR returns region-specific reasoning; audit logs with region overlays.
- Assumptions/dependencies: Accurate candidate region detection, clear organizational policy taxonomies, human-in-the-loop review.
- Bold: Screenshot and UI/UX review automation (Software)
- Analyze multi-panel layouts, UI states, and on-screen text; GAR’s strong MDVP-Bench performance supports structured reporting of UI elements and their relations (e.g., “button is disabled, tooltip overlaps panel”).
- Tools/workflows: QA tools for engineers/designers; CI pipelines that auto-capture UI screenshots and generate reports; localization checks using region-aware OCR+captioning.
- Assumptions/dependencies: OCR integration, robust mask proposal for UI components, consistent styling across builds.
- Bold: Semi-automatic dataset labeling and active learning (Academia, ML Ops)
- Use GAR to produce fine-grained regional captions, attribute labels, and multi-prompt relational QA pairs, accelerating annotation for vision datasets.
- Tools/workflows: Annotation toolkits that let annotators draw/approve masks; GAR suggests captions and VQA; GAR-Bench used to evaluate annotation quality and model comprehension.
- Assumptions/dependencies: Human validation, licensing compatibility with target datasets, careful prompt design to avoid bias.
- Bold: Video referential captioning and object-centric Q&A in static slices (Media, Sports)
- Zero-shot transfer to referential video tasks for describing selected objects and their relations in sampled frames (e.g., “player in mask <Prompt1> passes to player <Prompt2>”).
- Tools/workflows: Sports analytics and highlight generation using 16-frame sampling; mask selection via detectors; GAR captions/answers for on-screen overlays.
- Assumptions/dependencies: Limited temporal reasoning (trained on images), need for reliable per-frame segmentation/tracking, post-editing for broadcast quality.
- Bold: Robotics prototyping for object-centric assistance (Robotics)
- In lab or controlled settings, use GAR to verify object attributes and non-entities before grasp attempts (e.g., avoid reflections), and to explain relations among target objects.
- Tools/workflows: HRI interfaces where operators mark ROIs; GAR produces cues for manipulation (material/texture hints for gripper settings); scene checks prior to pick-and-place.
- Assumptions/dependencies: Static scenes or limited motion, integration with existing perception/segmentation stacks, domain fine-tuning for materials and tools.
- Bold: Scientific figure and microscopy reporting (Academia)
- Generate contextual, multi-ROI captions explaining relationships among annotated structures in microscopy or engineering images.
- Tools/workflows: Lab notebooks or ELN plug-ins allowing ROI masks; GAR returns detailed descriptions and relation-based Q&A; export to methods/results sections.
- Assumptions/dependencies: Domain-specific vocabulary and fine-tuning, careful masking of relevant structures, human validation.
- Bold: Region-conditioned visual search in DAM systems (Software)
- Query large image libraries by region-specific attributes and relations (e.g., “find images where <Prompt1> is riding <Prompt2> and the helmet is red”).
- Tools/workflows: DAM/enterprise search with ROI selection and GAR-backed structured indexing; interactive retrieval UX.
- Assumptions/dependencies: Indexing pipelines that incorporate GAR outputs, consistent masking workflows, privacy/compliance for personal images.
Long-Term Applications
The following applications require further research, scaling, or development—particularly in temporal modeling, safety-critical validation, domain adaptation, and on-device efficiency.
- Bold: Real-time, compositional video analytics with multi-object reasoning (Security, Retail, Transportation)
- Extend GAR’s multi-prompt reasoning to streams, tracking entities and relationships across time (e.g., “person picks up item, leaves store without paying”).
- Tools/workflows: Stream processing platforms with online segmentation/tracking; GAR-like temporal module; alerting dashboards with region overlays.
- Assumptions/dependencies: Robust temporal modeling and training, scalable compute, privacy compliance, false-alarm mitigation.
- Bold: Autonomous driving and robot decision-making with region-centric scene graphs (Automotive, Robotics)
- Use GAR-style context-preserving ROI reasoning to maintain dynamic scene graphs for planning (e.g., “pedestrian <Prompt1> approaching crosswalk <Prompt2>”).
- Tools/workflows: Perception stacks that pass ROIs from detectors to a GAR-derived reasoning module; integration with planners and safety cases.
- Assumptions/dependencies: Domain-specific training at scale, rigorous safety certification, latency constraints, sensor fusion beyond RGB.
- Bold: Clinical decision support in medical imaging (Healthcare)
- Provide ROI-specific Q&A and relation-aware reporting (e.g., “lesion <Prompt1> abuts vessel <Prompt2>”) with stronger domain knowledge and regulatory approvals.
- Tools/workflows: PACS viewer plug-ins; radiology workflows with mask-based annotations; GAR-derived structured reports.
- Assumptions/dependencies: Medical-domain datasets and fine-tuning, strict validation/QA, explainability requirements, regulatory clearance.
- Bold: AR smart glasses for “point-and-ask” region-aware assistance (Consumer, Education)
- Real-time ROI selection via gaze/gestures with on-device region-level understanding (e.g., “what is this part?”; “how does <Prompt1> relate to <Prompt2>?”).
- Tools/workflows: Lightweight GAR variants optimized for edge; segmentation-on-device; spatial anchoring of prompts.
- Assumptions/dependencies: Efficient on-device inference, battery constraints, robust user interaction, privacy-by-design.
- Bold: Regulatory auditing of advertising and disclosures (Policy, Finance)
- Automatically evaluate the placement and relational context of disclaimers, risk statements, and mandated elements (e.g., “disclaimer overlapped by graphic <Prompt2>”).
- Tools/workflows: Ad compliance suites with mask proposals for text and visuals; GAR-based relation checks; standardized reporting for regulators.
- Assumptions/dependencies: Clear policy codification, OCR reliability, human verification, handling of diverse creative formats.
- Bold: Industrial digital twins linking ROIs to CAD/3D models (Manufacturing, Energy)
- Map image/video regions to modeled parts and reason about fit, alignment, and interactions in 3D scenes.
- Tools/workflows: Vision-to-CAD alignment; GAR-derived scene graph over ROIs; maintenance/assembly assist tools.
- Assumptions/dependencies: Extension to 3D and multi-view, robust registration, domain data and calibration.
- Bold: Tool-use and compositional manipulation planning (Robotics)
- Leverage multi-ROI relational reasoning to plan sequences using tools (e.g., “use tool <Prompt1> to operate component <Prompt2>”).
- Tools/workflows: Integration with task planners; ROI-based affordance reasoning; simulation-to-real pipelines.
- Assumptions/dependencies: Embodied training with temporal reasoning, tactile feedback integration, safety constraints.
- Bold: Cross-camera, multi-view region reasoning for large sites (Construction, Infrastructure)
- Unify ROIs across cameras to reason about relationships and progress (e.g., “component installed relative to region targets across views”).
- Tools/workflows: Multi-view segmentation/tracking; GAR-style cross-view alignment; site dashboards.
- Assumptions/dependencies: Calibration and correspondence, temporal continuity, multi-sensor fusion.
- Bold: Scalable education assistants for visual domains (STEM, Arts)
- Region-centric interactive tutoring in anatomy, circuit design, or art composition, with multi-object relational explanations.
- Tools/workflows: Classroom/lab apps combining segmentation tools and GAR; curriculum-aligned Q&A generation; progress tracking.
- Assumptions/dependencies: Domain curricula and fine-tuning, content governance, age-appropriate interaction models.
Cross-cutting assumptions and dependencies
- Accurate ROI/mask generation is critical; typical workflow combines detector boxes with SAM for masks.
- Domain adaptation and fine-tuning substantially improve precision in specialized sectors (medical, manufacturing, automotive).
- Current video capabilities rely on frame sampling; robust temporal reasoning will require dedicated video training.
- Compute and latency constraints must be addressed for edge and real-time deployments (AR, robotics, autonomy).
- Human-in-the-loop review remains important for safety, compliance, and quality assurance.
- Ethical use, privacy protection, and license compliance are necessary across applications using user or public imagery.
Glossary
- Agentic models: Systems that plan and reason through multi-step interactions or tools, often via multi-turn dialogues, to solve tasks. "these agentic models require complex multi-turn conversations"
- AnyRes: A variable-resolution processing strategy used in LLaVA-NeXT that tiles or scales images to preserve detail across large inputs. "Specifically, our model processes the full, uncropped image (with the encoded mask prompt) with AnyRes~\citep{liu2024llavanext}, producing a global feature map that is rich in contextual information."
- Bounding box: A rectangular region that encloses an object or area of interest, often used to localize regions before feature extraction. "Based on the input mask, we then derive a corresponding bounding box for the region of interest and employ RoI-Align~\citep{he2017mask} to gather the relevant feature vectors directly from the global feature map."
- Compositional reasoning: Reasoning that combines multiple pieces of information (objects, attributes, relations) to infer higher-level conclusions. "advanced compositional reasoning to answer specific free-form questions about any region"
- Feature map: A spatial grid of feature vectors produced by a neural network backbone that encodes visual information across the image. "producing a global feature map that is rich in contextual information."
- Fine-grained recognition: The ability to distinguish subtle category or attribute differences within closely related classes. "However, we observe deficiencies in its fine-grained recognition capability, limiting the quality of generated captions for more complex scenarios."
- GAR-Bench: A benchmark suite introduced in the paper to evaluate region-level understanding, including multi-prompt captioning and VQA. "we introduce GAR-Bench, which not only provides a more accurate evaluation of single-region comprehension, but also, more importantly, measures interactions and complex reasoning across multiple regions."
- LLM-Merger: A role assigned to a LLM used to merge/generated enriched relational descriptions and QA pairs from multiple sources. "Subsequently, we regard Qwen2.5-72B~\citep{team2024qwen25} as the LLM-Merger, together with the original annotations provided by the PSG dataset~\citep{yang2022panoptic}, to generate: (1) 144K rich object descriptions ..."
- Mask embedding: A learned vector representation derived from a binary mask that conditions the vision backbone on the region(s) of interest. "This zero-initialized~\citep{zhang2023adding} mask embedding is then added to ViT's~\citep{dosovitskiy2021image} patch embeddings."
- Mask prompt: A binary mask provided as a visual prompt to specify the region(s) of interest for region-level understanding. "GAR first encodes the full, uncropped image (together with the mask prompt) with AnyRes~\citep{liu2024llavanext}."
- Multimodal LLMs (MLLMs): LLMs augmented with vision (and possibly other modalities) that can process and reason over images and text jointly. "While Multimodal LLMs (MLLMs) excel at holistic understanding, they struggle in capturing the dense world with complex scenes..."
- Non-Entity Recognition: The task of determining whether a prompted region corresponds to a real physical entity versus a reflection, shadow, or depiction. "Non-Entity Recognition is designed to test this specific capability by requiring the model to leverage sufficient global context."
- Open-class category-level image recognition: Recognition that can handle categories beyond a fixed training label set, including rare or long-tail classes. "Open-class category-level image recognition requires the model to recognize the category of the object and part entities."
- Ordinal logic: Reasoning about order and position (e.g., nth from left/top) within a structured arrangement. "Position evaluates the model's grasp of spatial arrangement and ordinal logic within a global context."
- Panoptic Scene Graph (PSG): A dataset combining panoptic segmentation with scene graph relations to capture objects and their relationships. "we incorporated the Panoptic Scene Graph (PSG) dataset~\citep{yang2022panoptic}, which is rich in relational information."
- Patch embeddings: Vector representations of image patches (tokens) used by Transformer-based vision backbones. "This zero-initialized~\citep{zhang2023adding} mask embedding is then added to ViT's~\citep{dosovitskiy2021image} patch embeddings."
- Relation (GAR-Bench subtask): A VQA subtask requiring identification of spatial or logical relationships among multiple prompted regions, often with distractors. "Relation measures the capacity for complex compositional reasoning across multiple prompts."
- RoI-Align: A pooling operation that precisely extracts features from a region of interest by avoiding quantization misalignment. "employ RoI-Align~\citep{he2017mask} to gather the relevant feature vectors directly from the global feature map."
- RoI-aligned feature replay: The paper’s technique that extracts context-aware local features for prompted regions from a global feature map computed on the full image. "we propose an RoI-aligned feature replay technique."
- Scene graph: A structured representation of objects (nodes) and their relationships (edges) in an image. "It requires the model to build a mental ``scene graph'', which is essential for comprehending complex object assemblies and interactions in cluttered, real-world environments."
- Segmentation mask: A pixel-level binary map indicating which pixels belong to a region or object of interest. "or segmentation masks~\citep{yuan2024osprey, lian2025describe}"
- Semantic IoU: Intersection-over-Union measured in semantic space (e.g., via embeddings/similarity), assessing both recognition and localization quality. "achieving top scores of 93.6 semantic similarity and 88.7 semantic IoU on LVIS~\citep{gupta2019lvis}"
- Vision Transformer (ViT): A Transformer-based vision backbone that operates on sequences of image patch tokens. "ViT's~\citep{dosovitskiy2021image} patch embeddings."
- Visual prompt: A visual cue (e.g., mask or box) given to the model to indicate a region for targeted analysis. "We simply regard masks as visual prompts, since masks have less ambiguity than other representations."
- Visual Question Answering (VQA): A task where a model answers questions about visual content, often requiring perception and reasoning. "a multifaceted visual question answering task (GAR-Bench-VQA)."
- Zero-initialized: Parameter initialization to zeros, used here for the mask-embedding branch to stabilize integration. "This zero-initialized~\citep{zhang2023adding} mask embedding is then added to ViT's~\citep{dosovitskiy2021image} patch embeddings."
- Zero-shot: Evaluation or transfer without task-specific fine-tuning on the target dataset. "our zero-shot GAR-8B even outperforms in-domain VideoRefer-7B on VideoRefer-Bench$^{\text{Q}$"
Collections
Sign up for free to add this paper to one or more collections.

