- The paper demonstrates that moderate synthetic data mixtures (~30% HQ rephrasing) can accelerate LLM convergence by 5–10x.
- The paper validates scaling laws for both data and model size, showing that pure synthetic data underperforms compared to mixed datasets.
- The paper reveals that optimal mixture strategies vary by data type and model size, challenging theoretical claims of inevitable model collapse.
Synthetic Data in LLM Pre-training: Scaling Laws, Benefits, and Pitfalls
Introduction and Motivation
The paper presents a comprehensive empirical study of synthetic data in LLM pre-training, focusing on scaling laws, mixture strategies, and the nuanced trade-offs between data quality and diversity. The investigation is motivated by the increasing scarcity of high-quality natural text and the growing interest in synthetic data as a scalable alternative for foundational model training. The study systematically addresses three core research questions: (1) the effectiveness of synthetic data at scale, (2) the impact of different synthetic data types and generation methodologies, and (3) principles for optimal deployment, including mixture ratios and generator model selection.
Synthetic Data Generation Paradigms
Two primary synthetic data paradigms are evaluated:
- Web Rephrasing: Leveraging LLMs to rewrite existing web documents, producing either high-quality (HQ) rephrasings or question-answer (QA) formatted data. This approach aims to enhance data quality or inject instruction-following patterns into pre-training.
- Synthetic Textbooks (TXBK): Generating entirely novel, structured, and pedagogically oriented content, mimicking textbook chapters seeded from web-derived keywords.
Both paradigms are implemented using a consistent generator (Mistral-Instruct-7B), with careful prompt engineering and light post-filtering to ensure data quality and stylistic diversity.
Empirical Methodology
The study involves training over 1000 LLM variants (up to 3B parameters) on datasets of up to 200B tokens, consuming more than 100,000 GPU hours. The experimental design includes:
- Data Mixtures: Systematic variation of synthetic-to-natural data ratios (0%, 33%, 67%, 100%) for each synthetic type.
- Scaling Law Analysis: Fitting and validating scaling laws for both data and model size, enabling extrapolation to larger regimes.
- Evaluation: Per-token average perplexity (cross-entropy loss) on a diverse set of held-out domains from The Pile and Wikitext-103.
Data Scaling Laws and Mixture Effects
The data scaling law, L^(D)=DβB+E, is validated with high precision (RMABE 0.41%) for 1B-parameter models up to 200B tokens.
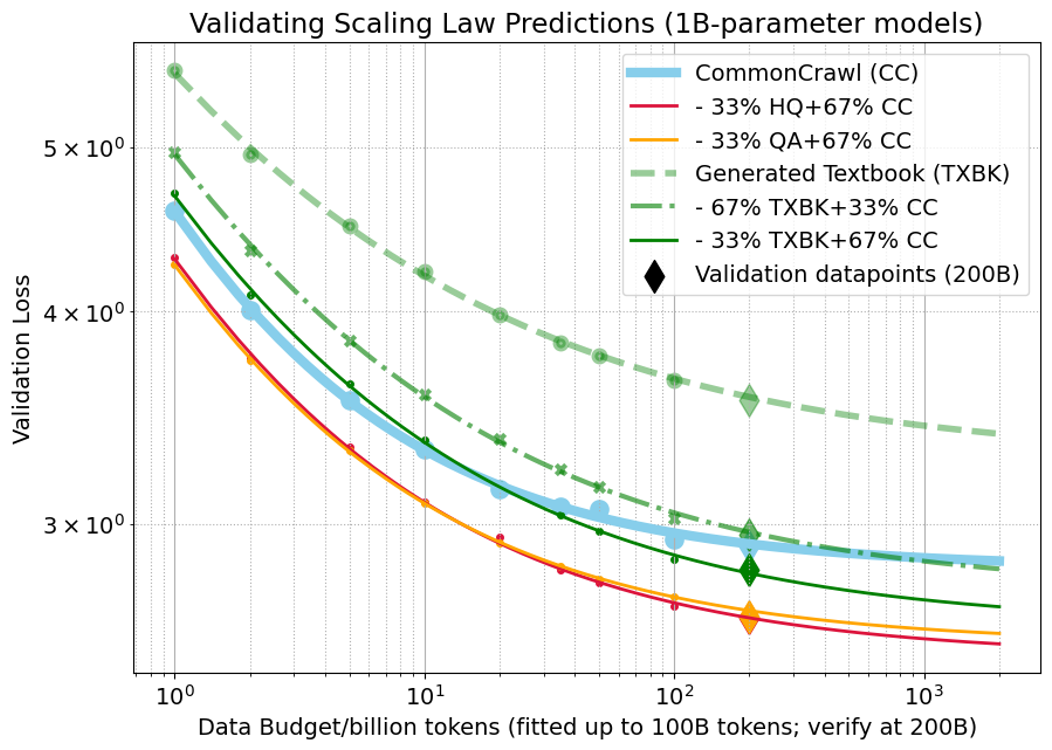
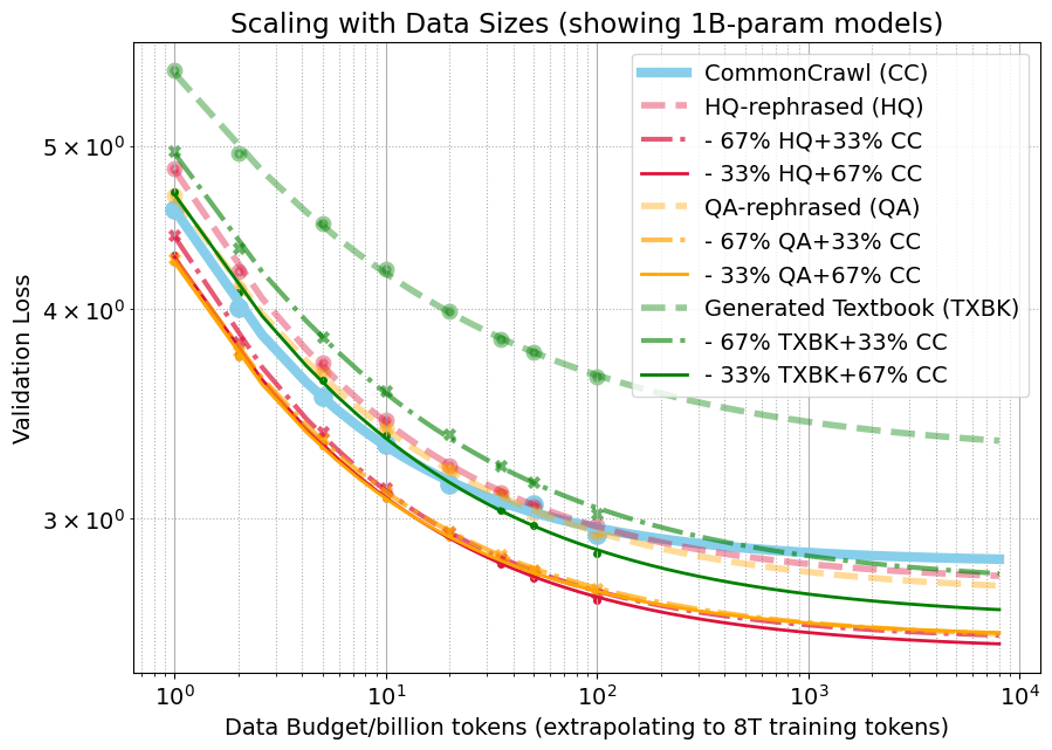
Figure 1: Data scaling law validation and extrapolation for 1B-parameter models across data mixtures.
Key findings:
- Pure synthetic data (HQ/QA/TXBK) does not outperform CommonCrawl (CC); TXBK is notably worse.
- Mixtures of synthetic and natural data consistently outperform pure synthetic. For HQ/QA, performance is robust to the synthetic ratio (33% vs. 67%), while for TXBK, lower synthetic fractions (33%) are clearly superior.
- Mixtures with ∼30% HQ synthetic data and 70% CC can accelerate convergence by 5–10x at large data budgets.
Model Scaling Laws
The model scaling law, L^(N)=NαA+E, is validated for models up to 3B parameters (RMABE 0.30%).
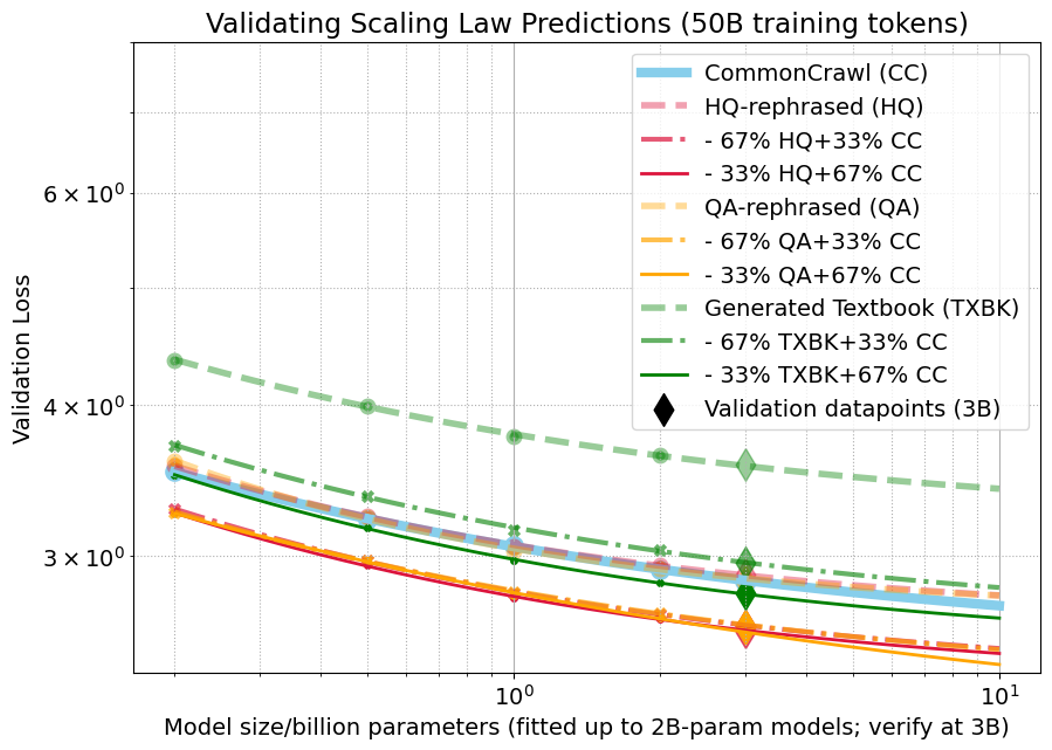
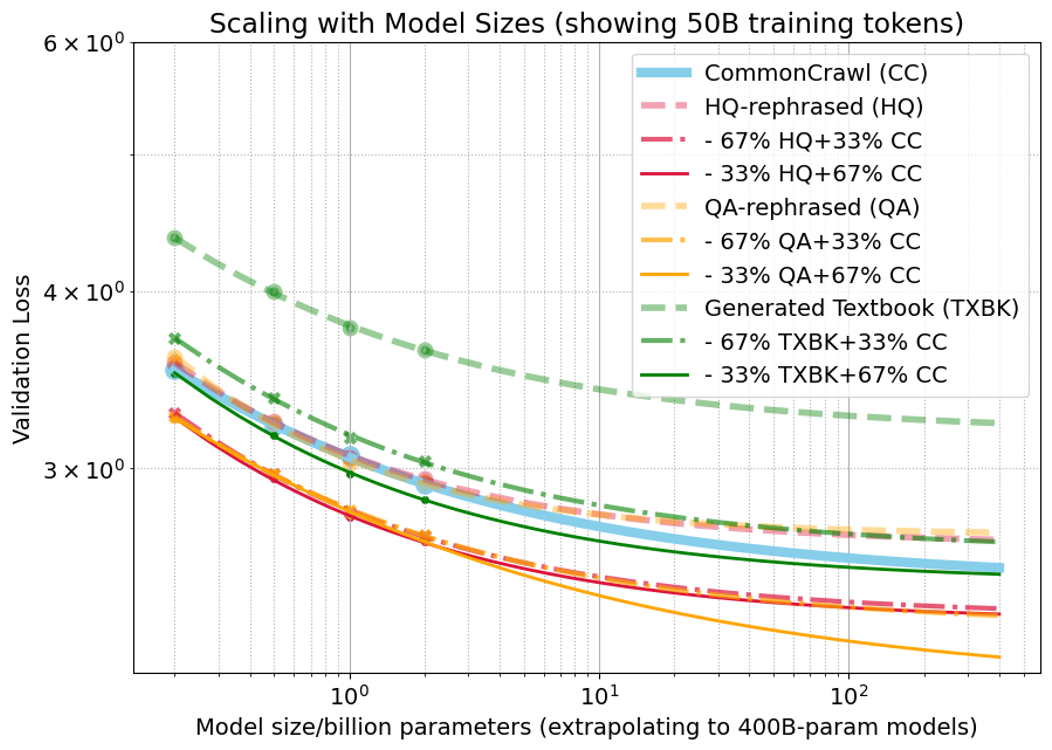
Figure 2: Model scaling law validation and extrapolation for 50B-token training across data mixtures.
Key observations:
- Pure synthetic data remains suboptimal for larger models; mixtures are necessary for competitive performance.
- Larger models are less tolerant of high synthetic data ratios; the advantage of synthetic mixtures diminishes as model size increases.
- TXBK mixtures are only beneficial at low synthetic ratios and for smaller models.
Irreducible Loss and Theoretical Limits
Joint scaling law fits estimate the irreducible loss E for each data mixture.
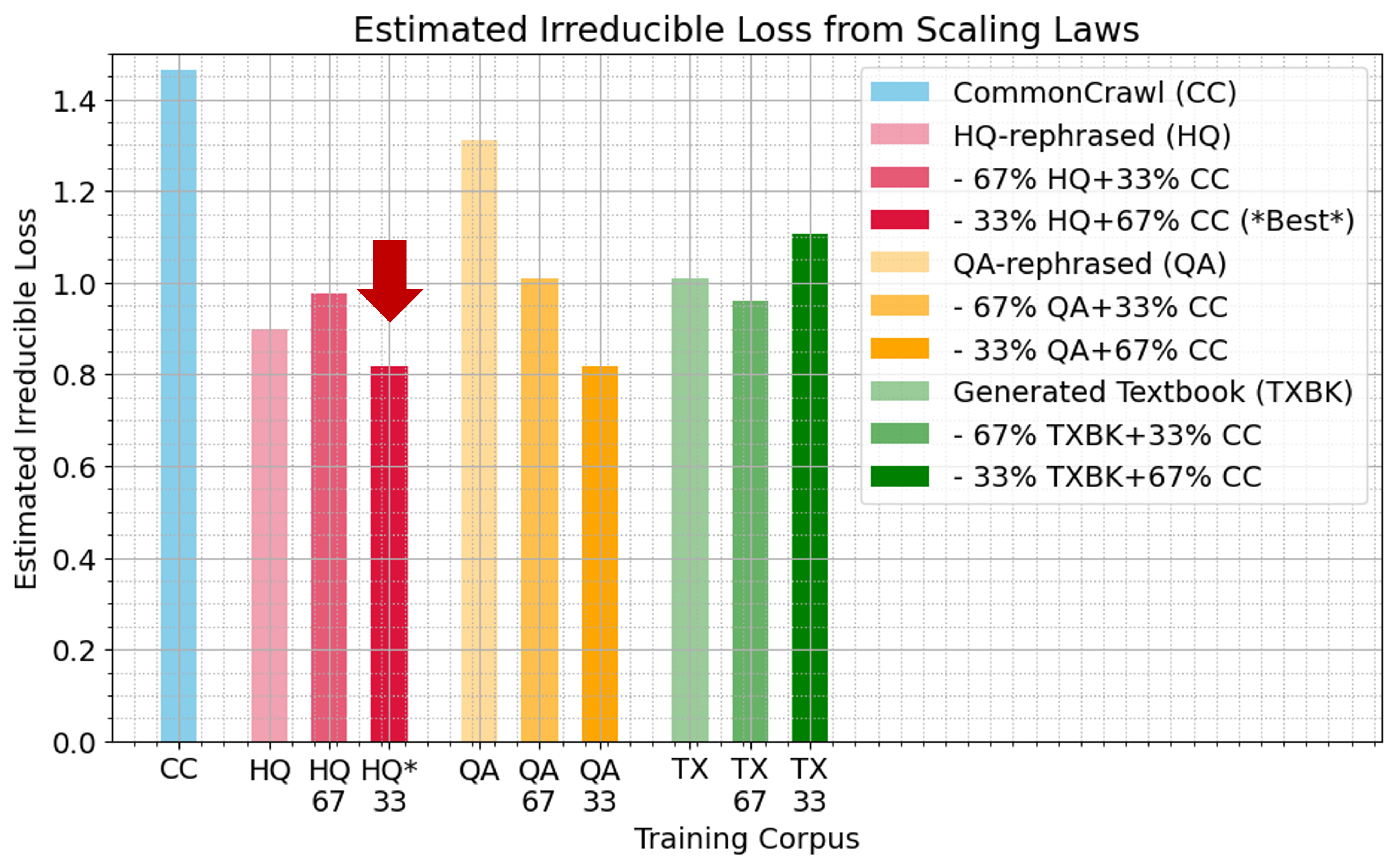
Figure 3: Estimated irreducible loss (E) for different data mixtures; lower is better.
Notably, mixtures involving synthetic data (except pure QA) are projected to achieve lower irreducible loss than pure CC, empirically challenging strong theoretical claims of inevitable "model collapse" from synthetic data inclusion.
Optimal Mixture Ratios
A fine-grained grid search over mixture ratios reveals:
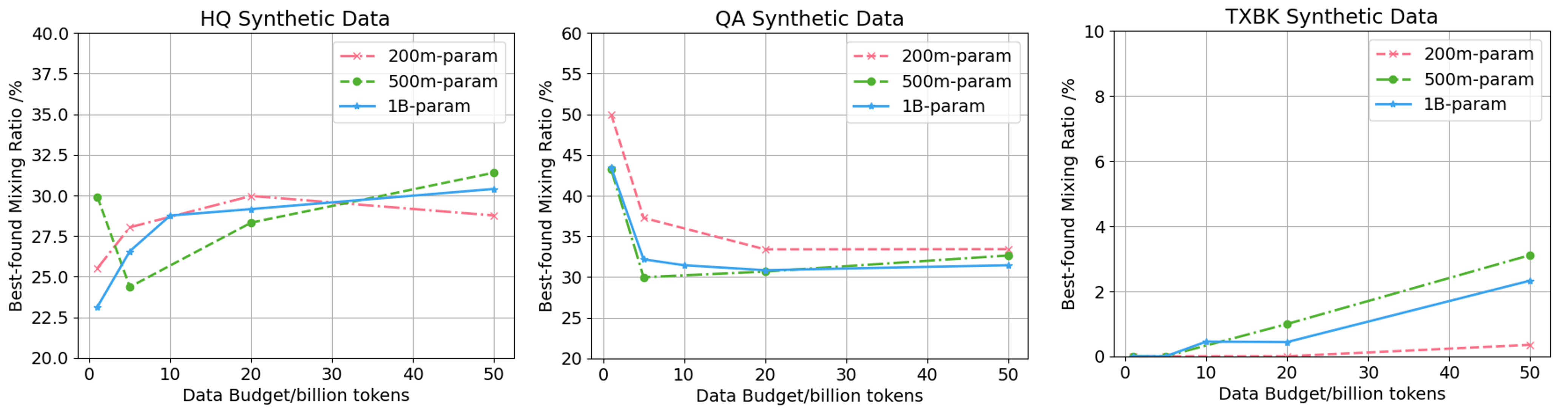
Figure 4: Best-found mixture ratios for HQ, QA, and TXBK synthetic data across model sizes and data budgets.
- Optimal HQ rephrased data ratio converges to ∼30% across scales.
- QA optimal ratio decreases with scale, from ∼50% to ∼30%.
- TXBK is only beneficial at minimal ratios (<5%) for small models, increasing with scale but always below HQ/QA.
Generator Model Capability
Ablation studies on generator size (Llama-3 3B/8B/70B) for rephrased data show:
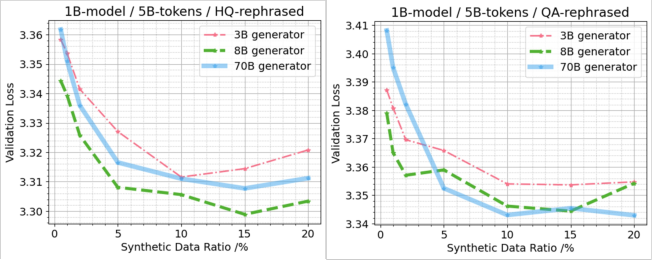
Figure 5: Validation loss for 1B-parameter models trained on HQ/QA rephrased data from Llama3-3B/8B/70B generators.
- Llama-3-8B generators outperform 3B, but 70B does not yield further gains; in some cases, 70B is worse than 8B.
- Generator scale beyond a moderate threshold does not guarantee better downstream performance; factors such as instruction-following fidelity and output diversity are critical.
Statistical Analysis and Diversity-Quality Trade-offs
Unigram analysis and Zipf fitting reveal:
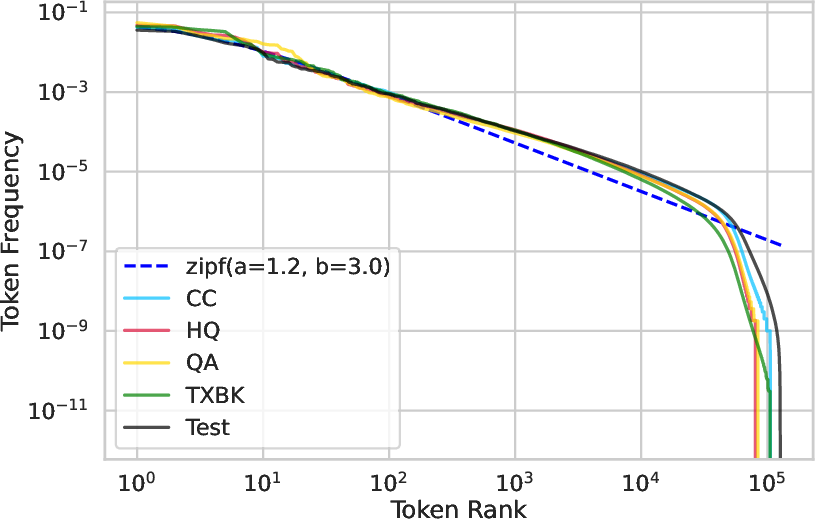
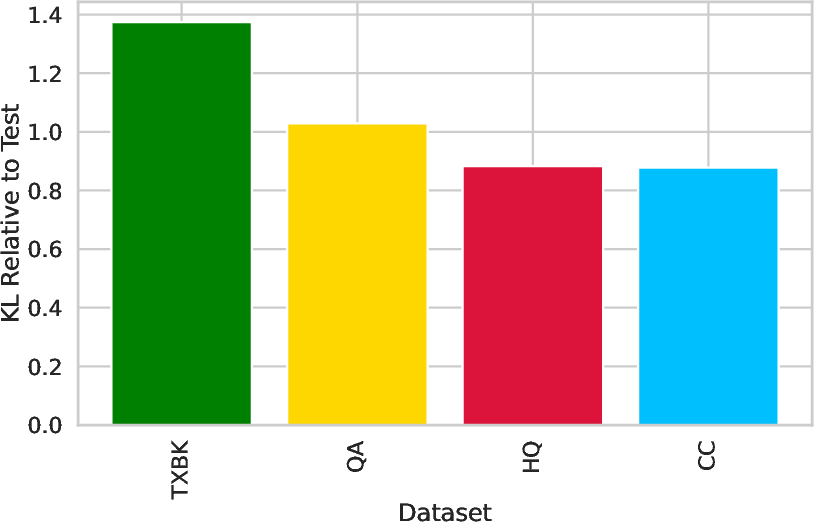
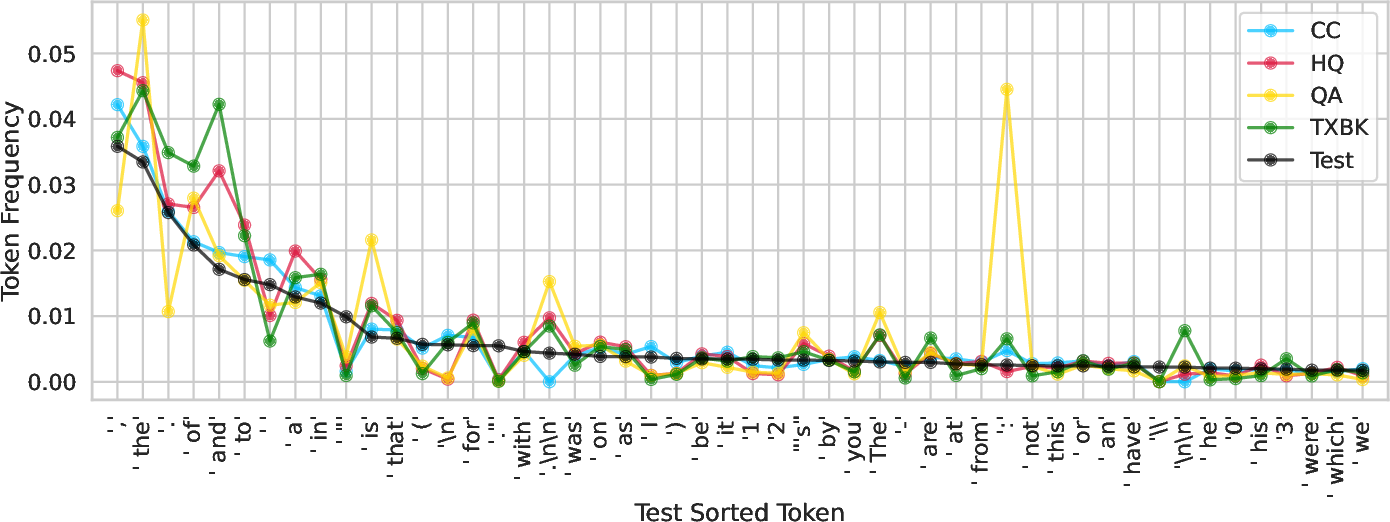
Figure 6: Unigram frequency analysis across training and test corpora.
- CommonCrawl has the widest unigram coverage and lowest KL-divergence to test sets, but this does not translate to superior downstream performance.
- No single training set offers complete coverage; high-loss tokens in evaluation are often rare or absent in training.
- Optimal mixtures do not minimize distributional distance; benefits arise from complex trade-offs between diversity and quality, not simple similarity.
Model Collapse: Empirical Evidence vs. Theory
The study provides mixed evidence regarding "model collapse":
- No degradation is observed for one-round (n=1) training on rephrased synthetic data, even at scale.
- Textbook-style synthetic data, especially at high ratios, does exhibit patterns consistent with model collapse (elevated loss, especially at small data budgets).
- Theoretical predictions of inevitable collapse from any synthetic data inclusion are empirically contradicted for rephrased data mixtures.
Practical Implications and Future Directions
- Synthetic data is not a universal solution; its utility is highly conditional on data type, mixture ratio, and generator model.
- Empirically optimal strategies involve moderate synthetic fractions (∼30%) and careful generator selection.
- Scaling trends suggest diminishing returns for synthetic data as model size increases; future work should target dynamic mixture strategies and more sophisticated synthetic data generation.
- Long-term and multi-generational effects (iterative synthetic training) remain underexplored; further research is needed to clarify the boundaries of model collapse and the role of diversity.
Conclusion
This systematic study demonstrates that strategic incorporation of rephrased synthetic data can substantially accelerate LLM pre-training and lower irreducible loss, but only under carefully controlled mixture ratios and generator choices. The findings challenge strong theoretical claims of universal model collapse from synthetic data, instead revealing a nuanced landscape where diversity-quality trade-offs, data type, and scale all interact. The results provide actionable guidance for practitioners and highlight open questions for future research, particularly regarding the long-term dynamics of synthetic data and the development of more targeted, robust generation methodologies.