- The paper introduces the GMAH algorithm, a novel hierarchical RL structure that autonomously generates dynamic subgoals to enhance multi-agent collaboration.
- The approach integrates QMIX networks with adaptive goal generation using auto-encoders, leading to improved sample efficiency and stable convergence.
- Experimental results in Mini-Grid and Trash-Grid environments demonstrate superior coordination and performance compared to state-of-the-art baselines.
Subgoal-based Hierarchical Reinforcement Learning for Multi-Agent Collaboration
In recent advancements, reinforcement learning (RL) has shown significant potential in various domains; however, it often struggles within complex multi-agent environments. This paper introduces a novel hierarchical architecture that improves training stability and efficiency by autonomously generating effective subgoals, thereby advancing multi-agent collaboration.
Introduction
The research community has encoded numerous successes in RL, merging Q-learning with neural networks to develop potent models capable of tackling complex domains such as autonomous driving and robotic navigation. Despite these achievements, constraints such as algorithm instability and low sampling efficiency remain intractable in multi-agent systems due to the widely known curse of dimensionality.
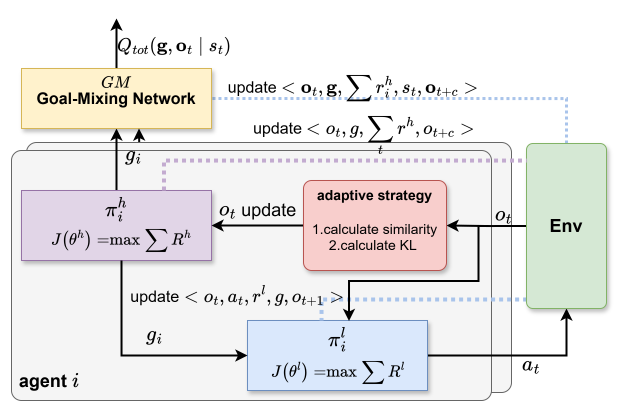
Figure 1: The overall GMAH structure.
Hierarchical reinforcement learning (HRL) addresses these challenges by leveraging abstract models to decompose tasks into simpler subtasks. This paper enhances HRL by integrating it with a QMIX network to address the critical issue of credit assignment in multi-agent systems while proposing a dynamic subgoal generation structure to adapt to environmental fluctuations.
Subgoal-based HRL Approach
The architecture (Figure 1) introduces a novel subgoal-based methodology for hierarchical learning in a multi-agent framework, termed the GMAH algorithm, to decompose tasks effectively.
General Architecture
The proposal segments an agent's policy into high-level and low-level functions. The high-level policy uses prior task knowledge to set strategic subgoals, whereas the low-level policy is incentivized through intrinsic rewards to achieve these subgoals. This hierarchical structure fosters enhanced task execution and coordination among agents.
Task-Tree Style Subgoal Generation
Task decomposition is operationalized through a task-tree structure, simplifying the learning process by managing the subgoal space. This refined approach significantly reduces the problem's dimensionality, focusing on the generation of explicit, attainable subgoals over abstract, cumbersome representations (Figure 2 and 3).
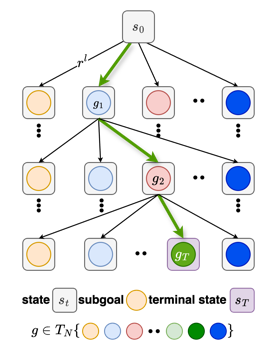
Figure 2: A typical diagram of task tree.
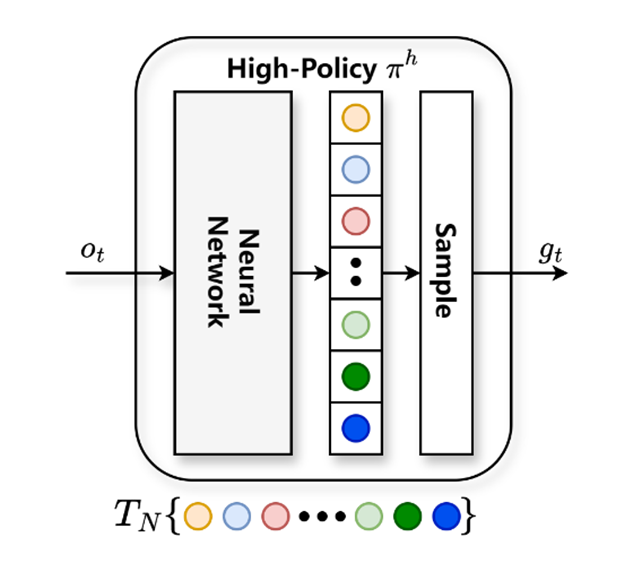
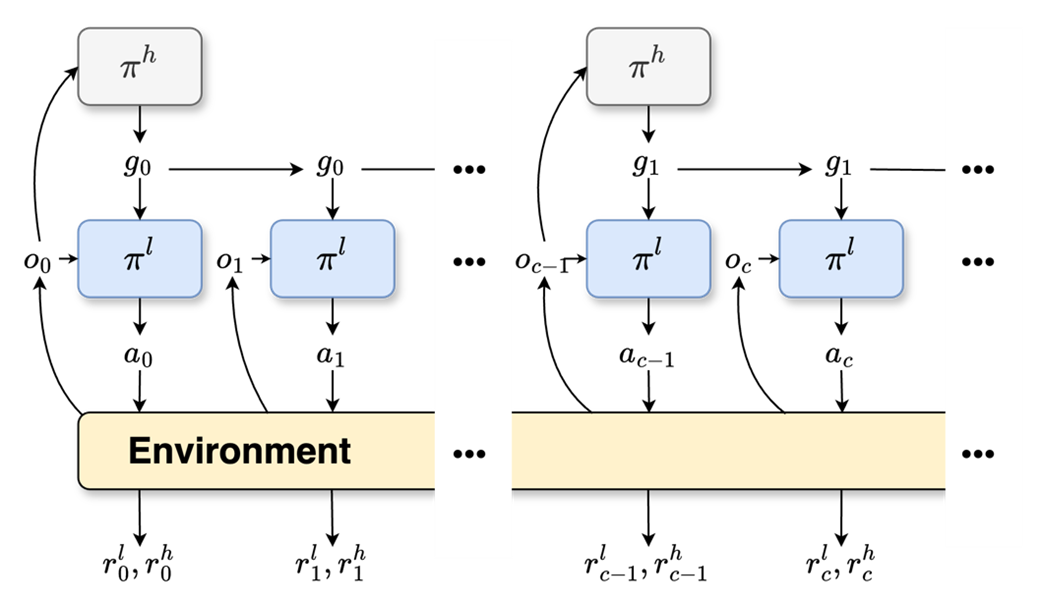
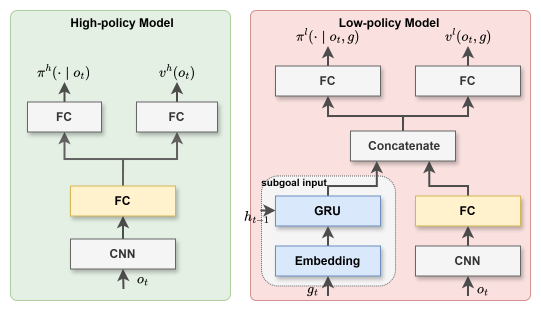
Figure 3: (a) High-Policy Network Model. (b) Hierarchical architecture applied by single agent in GMAH algorithm. (c) Network Model of GMAH.
Adaptive Goal Generation Strategy
Advancing further, the GMAH integrates a flexible goal update strategy that discards the traditional fixed-c interval in favor of adaptive adjustments based on environmental interactions (Figure 4). An auto-encoder refines these subgoals, ensuring response to significant environmental shifts, thus enhancing adaptability and communication-limited system efficiency.
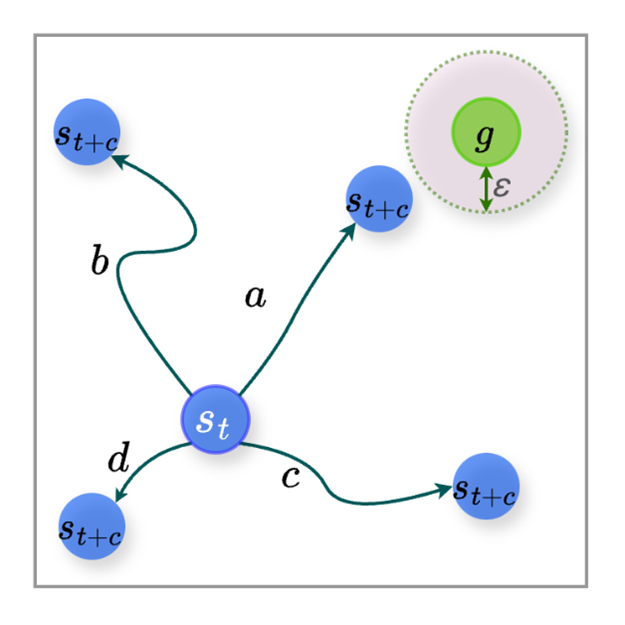
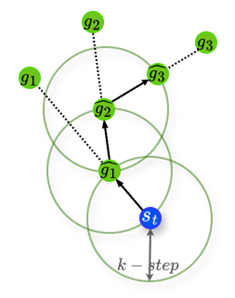
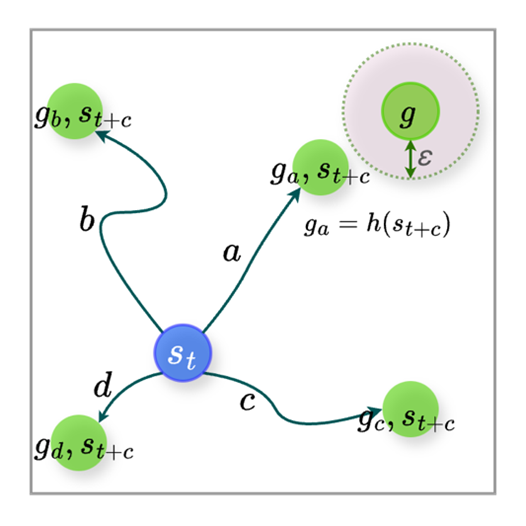
Figure 4: (a) Trajectory example of agent c-step interaction. (b) Adjacency Constraint on Goal Space of HRAC. Goal Relabel on Trajectory of agent c-step interaction: (c) relabel the abstract subgoal, and (d) relabel subgoal of GMAH.
Fine-Tuning and Scaling Considerations
The GMAH uses a goal mixing network to manage multi-agent integration effectively (Figure 5). This component ensures efficient multi-agent interpolation through joint goal functions, which improve credit assignment quality and foster cohesive agent strategies.
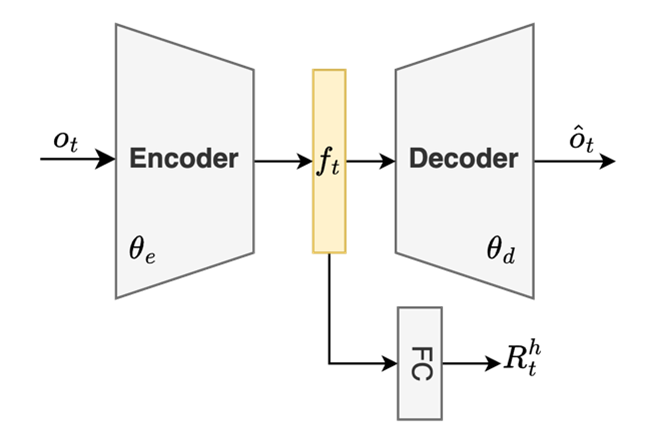
Figure 6: Auto-Encoder with Successor Feature Correction.
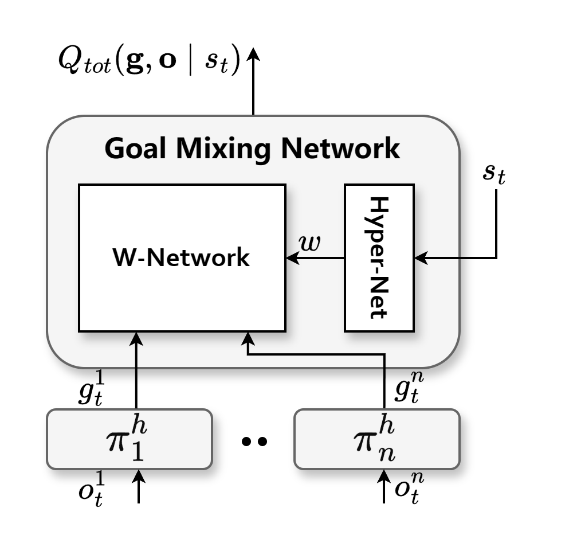
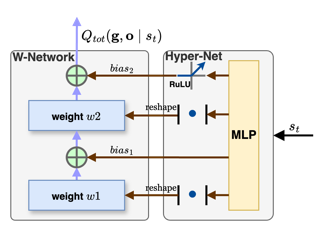
Figure 5: (a) Goal Mixing Network. (b) Hyper-Net and Weight-Network.
Experimental Analysis
The GMAH algorithm's performance was critically assessed within controlled environments, Mini-Grid for single-agent systems, and Trash-Grid for multi-agent collaboration scenarios, revealing several insights into its empirical advantages.
Mini-Grid Environment
In the Mini-Grid setup, GMAH demonstrated superior sample efficiency and convergence speed compared to conventional RL algorithms such as PPO and A2C. Key results in Figure 7 and 9 highlight GMAH's capacity to maintain high performance from the onset of training, crucially outperforming baselines.
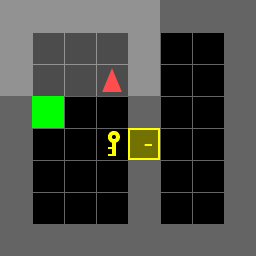
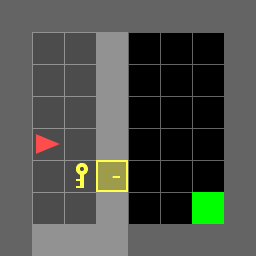
Figure 8: Mini-Grid Door Key Environment Diagram: (a) in the same room, and (b) in different rooms.
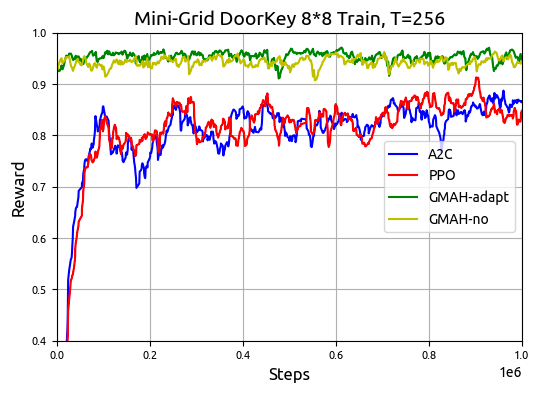
Figure 7: Result of GMAH-adapt, GMAH-no, PPO and A2C during training with T=256.
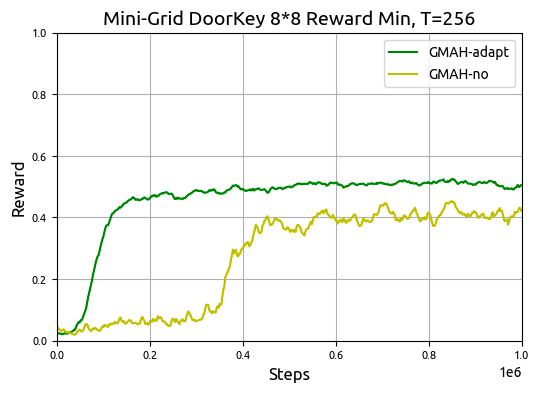
Figure 9: Min Reward of GMAH-adapt and GMAH-no during training with T=256.
Trash-Grid Environment
In a multi-agent Trash-Grid environment (Figure 10 and 14), the hierarchical architecture proved advantageous for dynamic task allocation among agents, improving collective efficiency in task execution compared to MAPPO, QMIX, and COMA. Enhanced exploration and data utilization efficiency were evidenced by heatmap data (Figure 11 and 16).
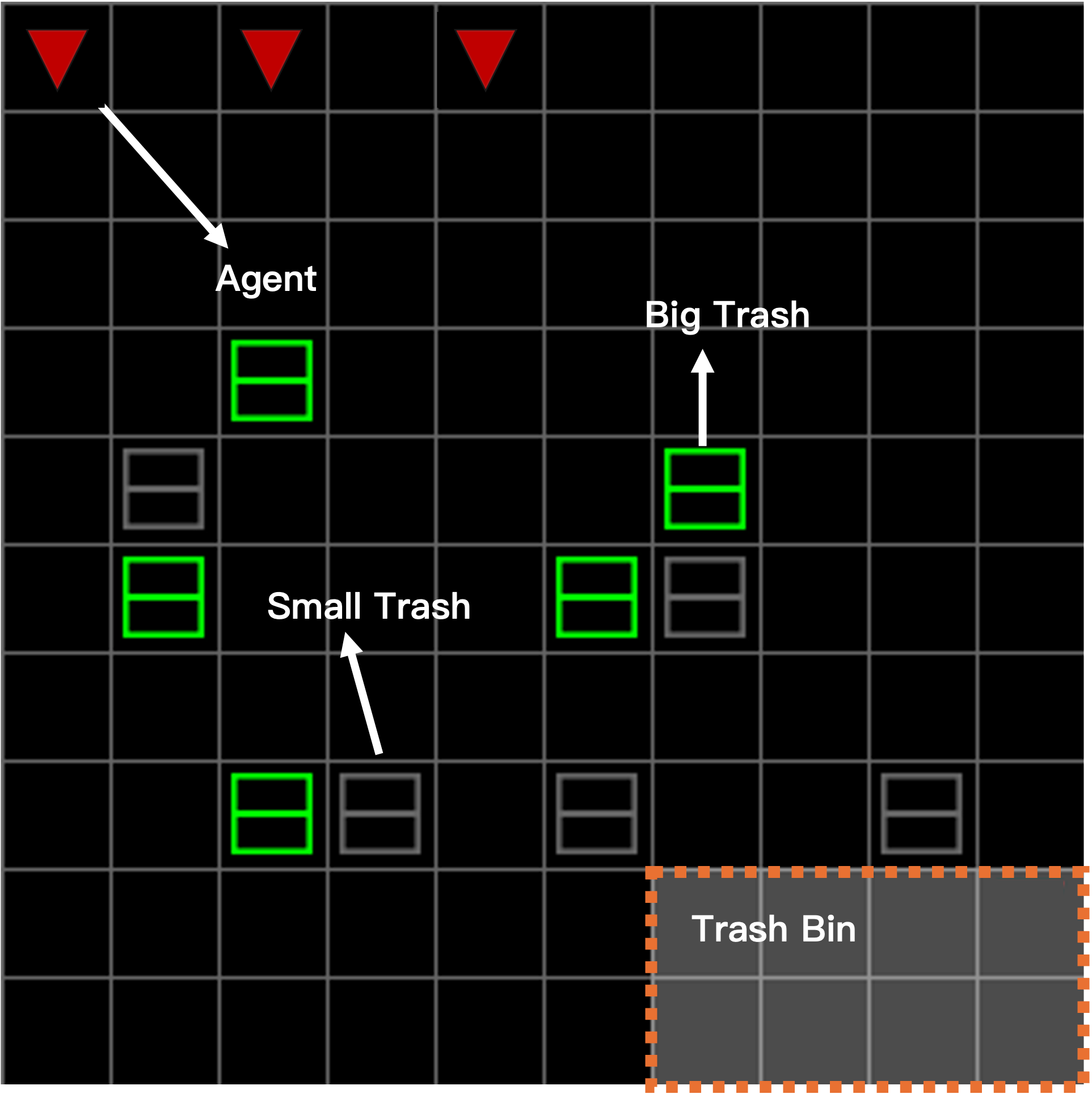
Figure 10: Tras-Grid environment diagram.
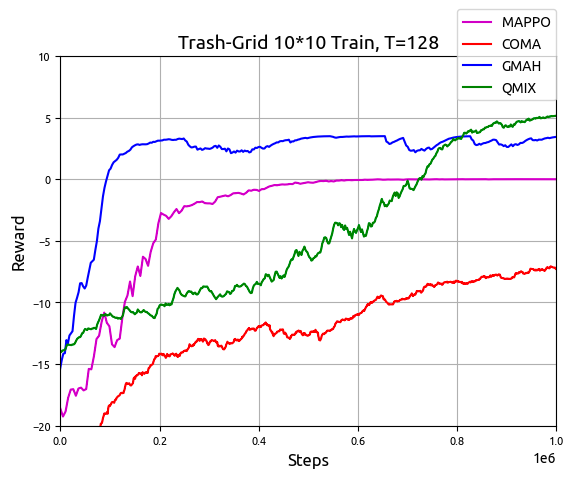
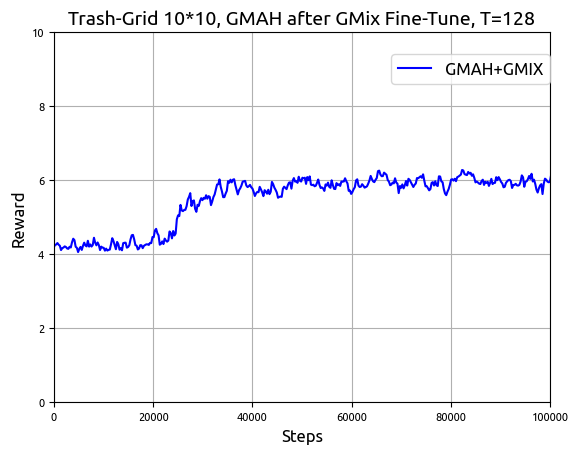
Figure 12: Training result of GMAH, MAPPO, COMA and QMIX in Trash-Grid environment with T=128. (a) The experimental results of training $1,000,000$ steps by four methods, (b) Results of $100,000$ steps of fine-tuning training for GMAH using a goal mixing network.
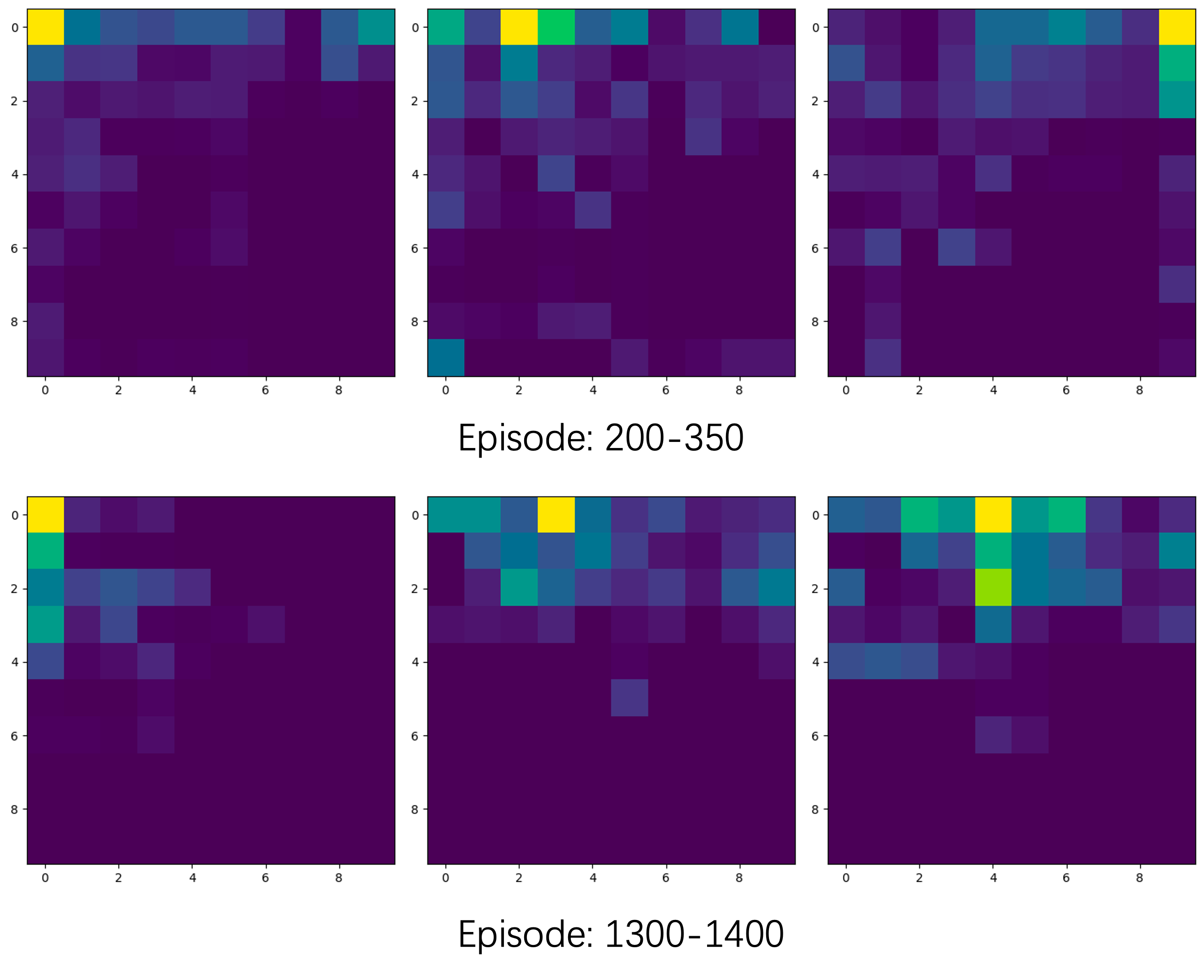
Figure 11: During the training of MAPPO, the heat map counts the movement trajectories of the agents (the number of visits to each grid) in several episodes, representing the results of the three agents from left to right.
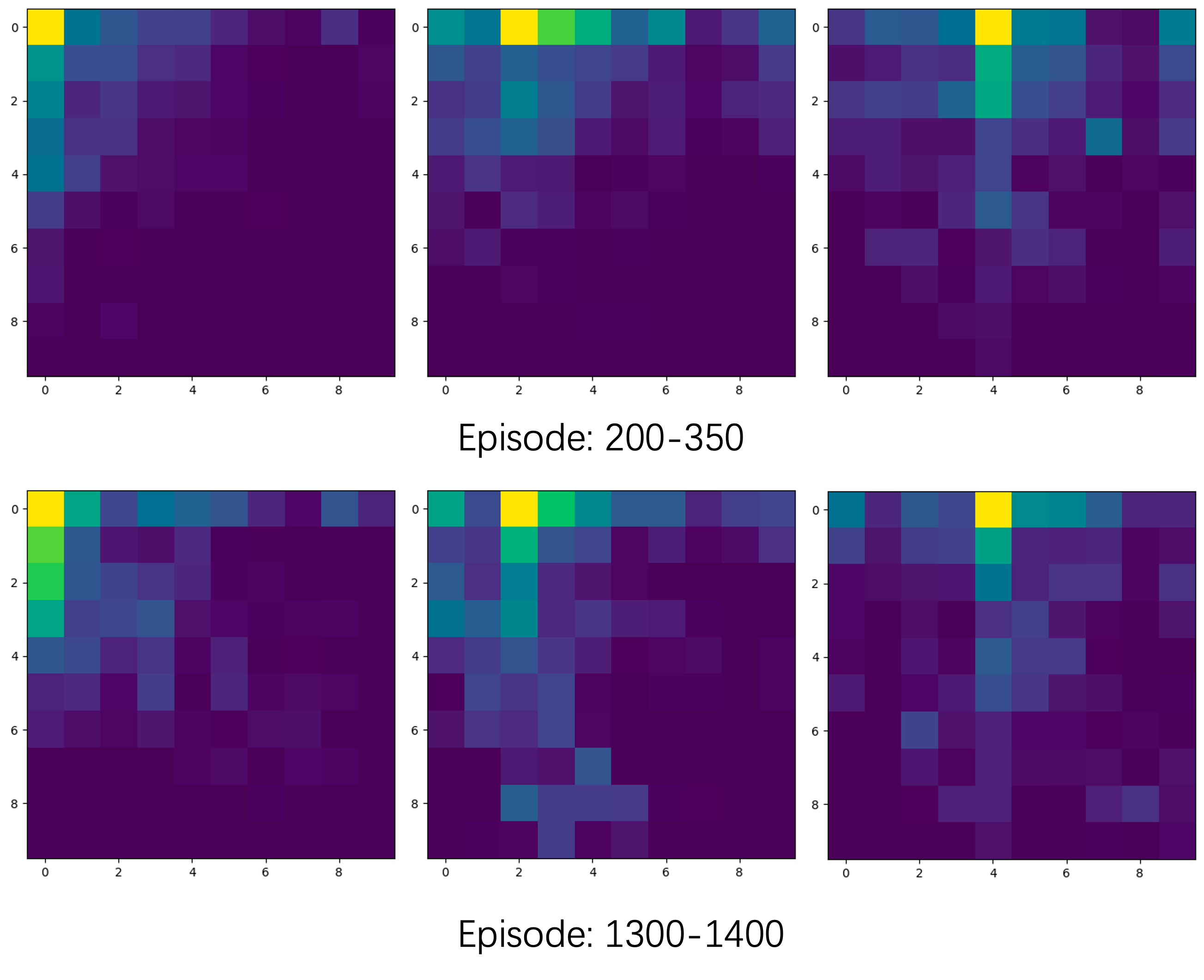
Figure 13: During the training of GMAH, the heat map counts the movement trajectories of the agents (the number of visits to each grid) in several episodes, representing the results of the three agents from left to right.
Conclusion
By establishing a robust hierarchical learning architecture, the GMAH algorithm markedly enhances multi-agent collaboration through sophisticated goal abstraction and dynamic adaptability. This method's efficiency in decomposing complex tasks into manageable subtasks is substantiated across various experimental setups, positioning GMAH as a promising approach for future RL research in dynamic, multi-agent systems. The findings invite further investigation into improving low-level policy efficacy and refining goal adaptation mechanisms.
