Multi-agent cooperation through learning-aware policy gradients
Abstract: Self-interested individuals often fail to cooperate, posing a fundamental challenge for multi-agent learning. How can we achieve cooperation among self-interested, independent learning agents? Promising recent work has shown that in certain tasks cooperation can be established between learning-aware agents who model the learning dynamics of each other. Here, we present the first unbiased, higher-derivative-free policy gradient algorithm for learning-aware reinforcement learning, which takes into account that other agents are themselves learning through trial and error based on multiple noisy trials. We then leverage efficient sequence models to condition behavior on long observation histories that contain traces of the learning dynamics of other agents. Training long-context policies with our algorithm leads to cooperative behavior and high returns on standard social dilemmas, including a challenging environment where temporally-extended action coordination is required. Finally, we derive from the iterated prisoner's dilemma a novel explanation for how and when cooperation arises among self-interested learning-aware agents.
- Melting Pot 2.0. arXiv preprint arXiv:2211.13746, 2023.
- What learning algorithm is in-context learning? Investigations with linear models. In International Conference on Learning Representations, 2023.
- Multi-Agent Reinforcement Learning: Foundations and Modern Approaches. MIT Press, 2024.
- R. Axelrod and W. D. Hamilton. The evolution of cooperation. Science, 211(4489):1390–1396, Mar. 1981.
- The DeepMind JAX Ecosystem, 2020.
- The good shepherd: An oracle agent for mechanism design. arXiv preprint arXiv:2202.10135, 2022.
- R. Bellman. A Markovian decision process. Journal of Mathematics and Mechanics, pages 679–684, 1957.
- Learning a synaptic learning rule. Technical report, Université de Montréal, Département d’Informatique et de Recherche opérationnelle, 1990.
- JAX: composable transformations of Python+NumPy programs, 2018.
- Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 2020.
- C. Claus and C. Boutilier. The dynamics of reinforcement learning in cooperative multiagent systems. AAAI/IAAI, 1998(746-752):2, 1998.
- Building machines that learn and think with people. arXiv preprint arXiv:2408.03943, 2024.
- Meta-value learning: a general framework for learning with learning awareness. arXiv preprint arXiv:2307.08863, 2023.
- Griffin: mixing gated linear recurrences with local attention for efficient language models. arXiv preprint arXiv:2402.19427, 2024.
- RL2: Fast reinforcement learning via slow reinforcement learning. In International Conference on Learning Representations, 2017.
- A social path to human-like artificial intelligence. Nature Machine Intelligence, 5(11):1181–1188, 2023.
- Model-agnostic meta-learning for fast adaptation of deep networks. In International Conference on Machine Learning, 2017.
- Learning with opponent-learning awareness. In International Conference on Autonomous Agents and Multiagent Systems, 2018a.
- DiCE: The infinitely differentiable Monte Carlo estimator. In International Conference on Machine Learning, 2018b.
- D. Fudenberg and D. K. Levine. The theory of learning in games, volume 2. MIT press, 1998.
- Socially intelligent machines that learn from humans and help humans learn. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 381(2251):20220048, July 2023.
- G. Hardin. The tragedy of the commons. Science, 162(3859):1243–1248, 1968.
- Array programming with NumPy. Nature, 585(7825):357–362, 2020.
- Flax: A neural network library and ecosystem for JAX, 2024. URL http://github.com/google/flax.
- A survey of learning in multiagent environments: Dealing with non-stationarity. arXiv preprint arXiv:1707.09183, 2017.
- Multi-task deep reinforcement learning with popart. In Proceedings of the AAAI Conference on Artificial Intelligence, 2019.
- Learning to learn using gradient descent. In International Conference on Artificial Neural Networks, Lecture Notes in Computer Science. Springer, 2001.
- J. D. Hunter. Matplotlib: A 2D graphics environment. Computing in Science & Engineering, 9(3):90–95, 2007.
- Planning and acting in partially observable stochastic domains. Artificial Intelligence, 101(1):99–134, 1998.
- Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- Scaling opponent shaping to high dimensional games. In International Conference on Autonomous Agents and Multiagent Systems, 2024.
- A policy gradient algorithm for learning to learn in multiagent reinforcement learning. In International Conference on Machine Learning, 2021.
- H. W. Kuhn. Extensive games and the problem of information. Princeton University Press, 1953.
- In-context reinforcement learning with algorithm distillation. arXiv preprint arXiv:2210.14215, 2022.
- Multi-agent reinforcement learning in sequential social dilemmas. In International Conference on Autonomous Agents and Multiagent Systems, 2017.
- Stable opponent shaping in differentiable games. In International Conference on Learning Representations, 2019.
- Transformers as algorithms: generalization and stability in in-context learning. In International Conference on Machine Learning, 2023.
- Model-free opponent shaping. In International Conference on Machine Learning, 2022.
- Asynchronous methods for deep reinforcement learning. In International Conference on Machine Learning, 2016.
- J. F. Nash Jr. Equilibrium points in n-person games. Proceedings of the National Academy of Sciences, 36(1):48–49, 1950.
- M. A. Nowak and K. Sigmund. Tit for tat in heterogeneous populations. Nature, 355(6357):250–253, 1992. Publisher: Nature Publishing Group UK London.
- Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, 2023.
- Iterated Prisoner’s Dilemma contains strategies that dominate any evolutionary opponent. Proceedings of the National Academy of Sciences, 109(26):10409–10413, 2012.
- N. C. Rabinowitz. Meta-learners’ learning dynamics are unlike learners’. arXiv preprint arXiv:1905.01320, 2019.
- A. Rapoport. Prisoner’s dilemma—recollections and observations. In Game Theory as a Theory of a Conflict Resolution, pages 17–34. Springer, 1974.
- I. Rechenberg and M. Eigen. Evolutionsstrategie: Optimierung technischer Systeme nach Prinzipien der biologischen Evolution. Frommann-Holzboog Verlag, 1973.
- Evolutionary dynamics of social dilemmas in structured heterogeneous populations. Proceedings of the National Academy of Sciences, 103(9):3490–3494, 2006.
- J. Schmidhuber. Evolutionary principles in self-referential learning, or on learning how to learn: the meta-meta-… hook. Diploma thesis, Institut für Informatik, Technische Universität München, 1987.
- Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Y. Shoham and K. Leyton-Brown. Multiagent systems: Algorithmic, game-theoretic, and logical foundations. Cambridge University Press, 2008.
- Value-decomposition networks for cooperative multi-agent learning. arXiv preprint arXiv:1706.05296, 2017.
- R. S. Sutton and A. Barto. Reinforcement learning: An introduction. MIT Press, 2018.
- Policy gradient methods for reinforcement learning with function approximation. Advances in Neural Information Processing Systems, 12, 1999.
- M. Tan. Multi-agent reinforcement learning: Independent vs. cooperative agents. In International Conference on Machine Learning, 1993.
- Generative agent-based modeling with actions grounded in physical, social, or digital space using Concordia. arXiv preprint arXiv:2312.03664, 2023.
- J. von Neumann and O. Morgenstern. Theory of games and economic behavior. Princeton University Press, 1947.
- Uncovering mesa-optimization algorithms in Transformers. arXiv preprint arXiv:2309.05858, 2023.
- Learning to reinforcement learn. arXiv preprint arXiv:1611.05763, 2016.
- COLA: consistent learning with opponent-learning awareness. In International Conference on Machine Learning, 2022.
- Learning latent representations to influence multi-agent interaction. In Conference on Robot Learning, 2021.
- Multi-agent reinforcement learning: A selective overview of theories and algorithms. Handbook of Reinforcement Learning and Control, pages 321–384, 2021.
- Proximal learning with opponent-learning awareness. Advances in Neural Information Processing Systems, 35, 2022.
- K. J. Åström. Optimal control of Markov processes with incomplete state information I. Journal of Mathematical Analysis and Applications, 10:174–205, 1965.
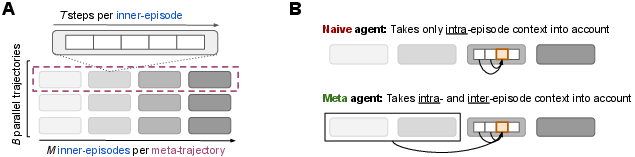
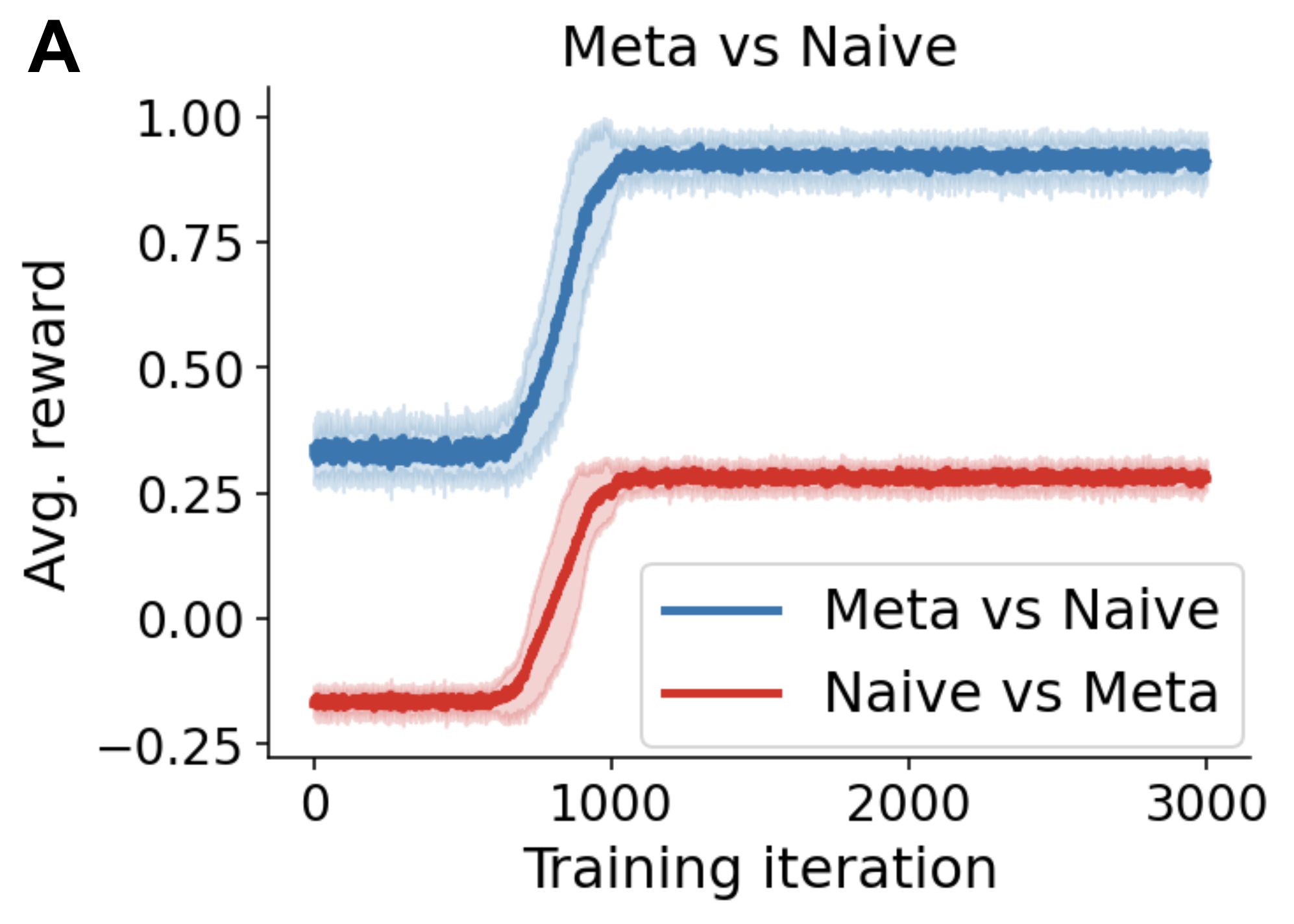
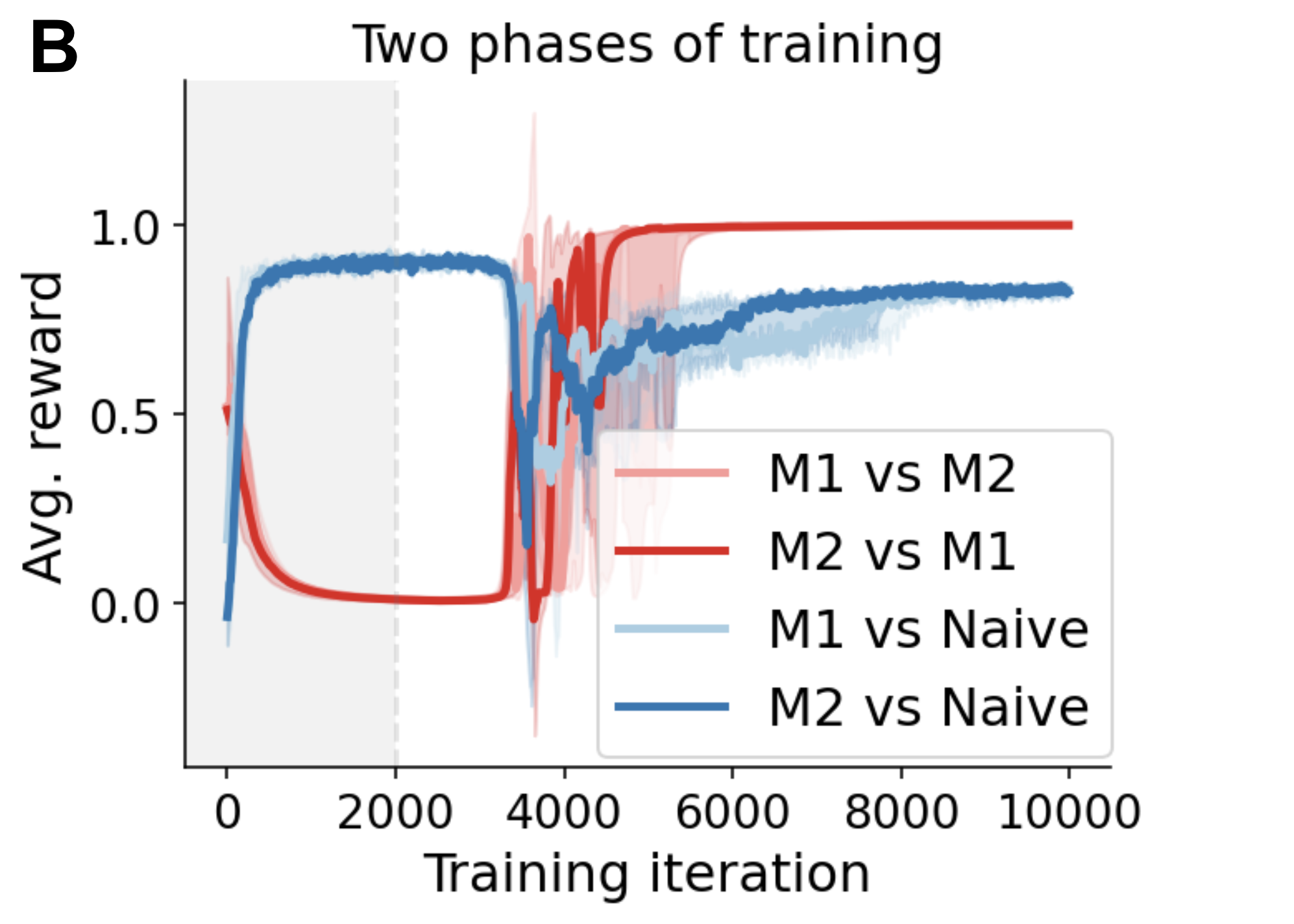
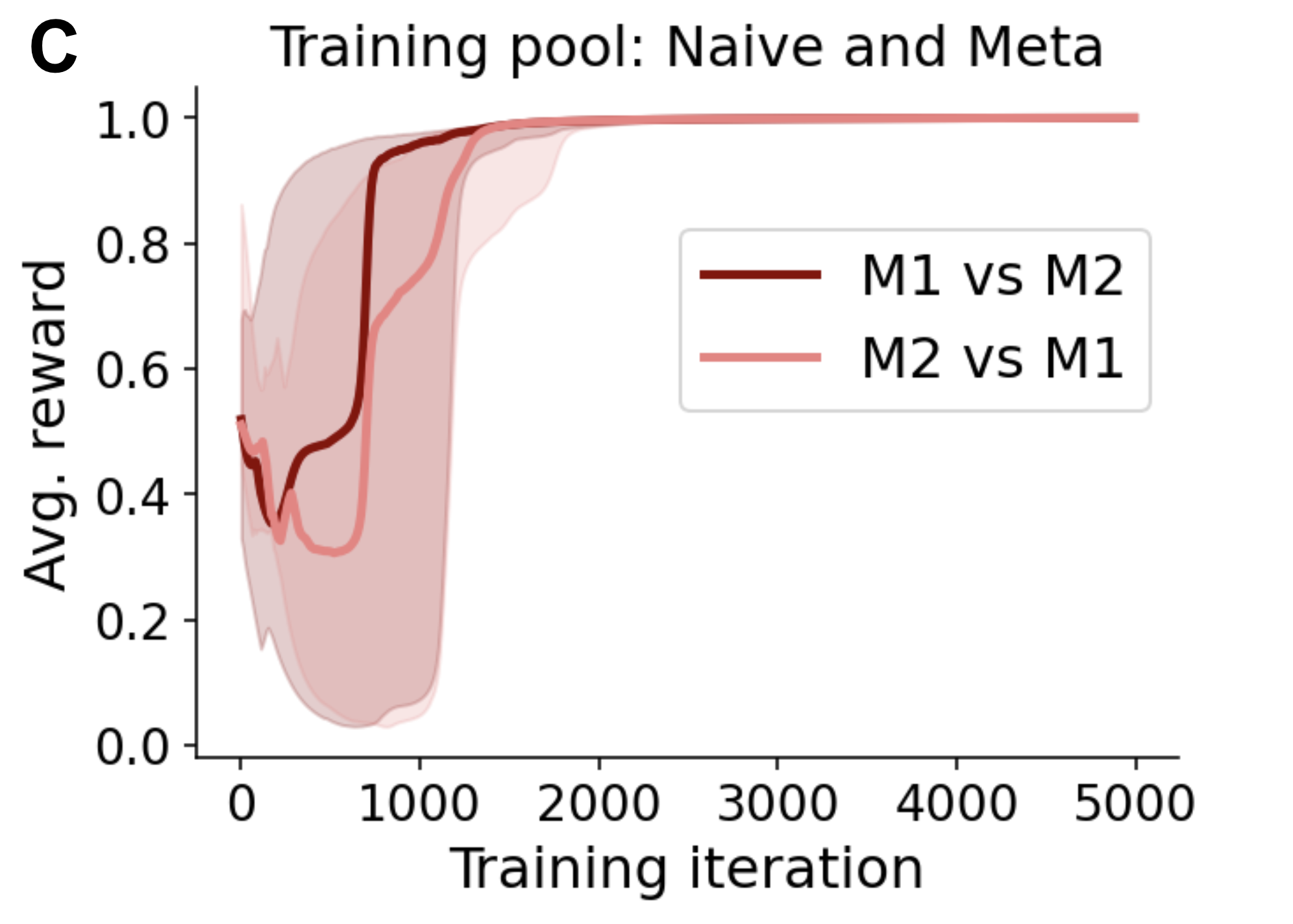
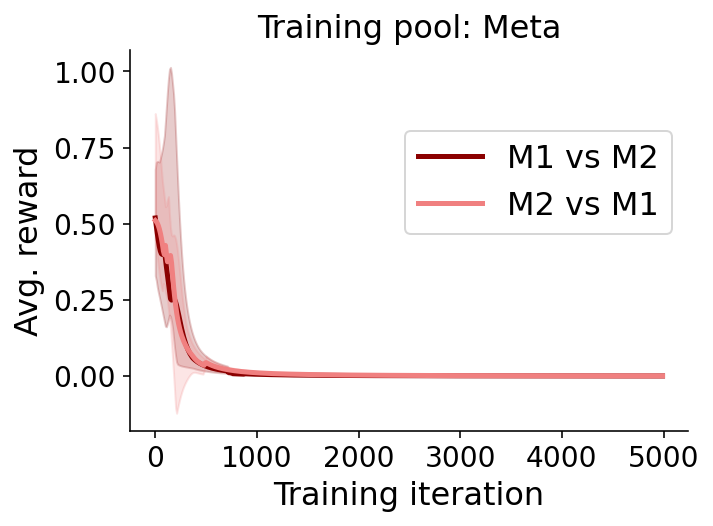
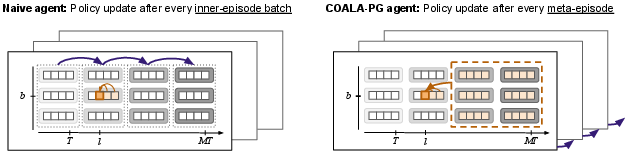
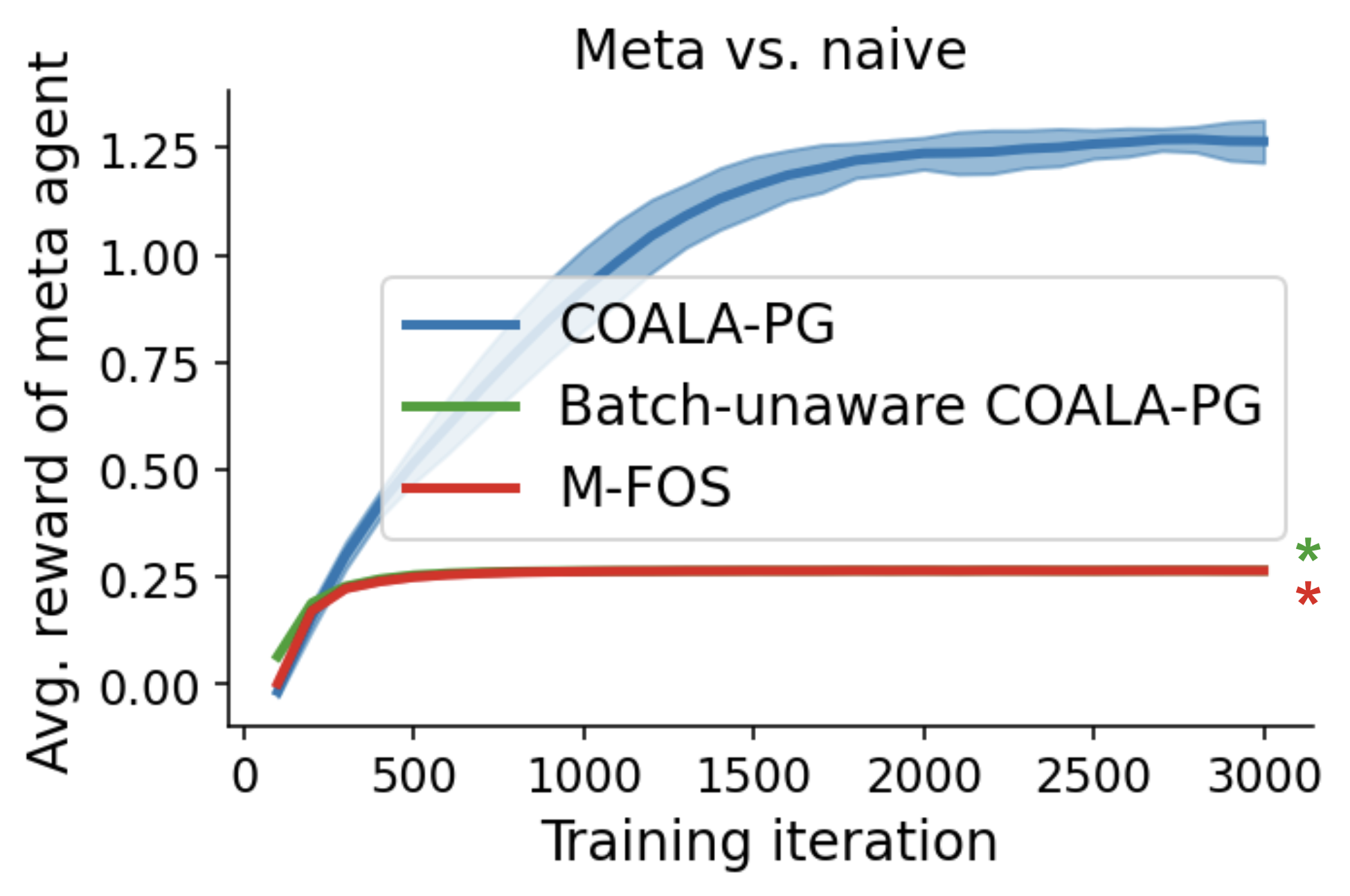
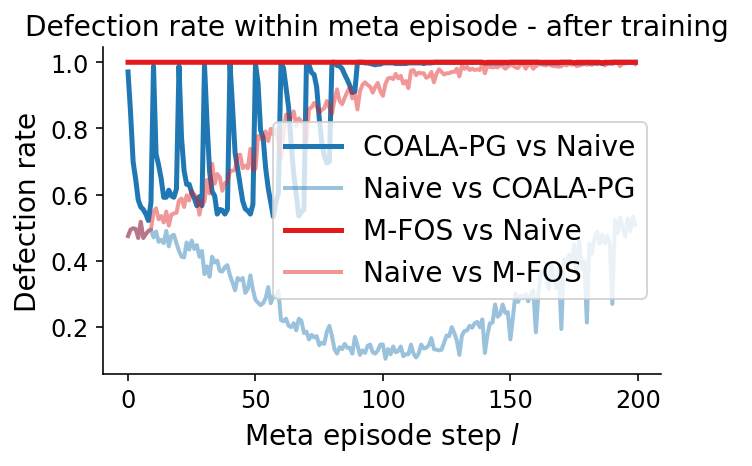

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

