- The paper introduces an innovative environment wrapper that augments any RL setting with goal-conditioning, enabling reward-free, autonomous learning.
- It employs multiple goal selection strategies including random, novelty-driven, and intermediate success rate methods to enhance convergence compared to reward-guided baselines.
- Empirical results show rapid stabilization in aggregate goal success while highlighting challenges in individual goal retention and episodic forgetting.
Environment-Agnostic Goal-Conditioning for Reward-Free Autonomous Learning
Introduction
This paper investigates the paradigm of reward-free autonomous learning in reinforcement learning (RL) via environment-agnostic goal-conditioning. The authors present a systematic study of transforming regular RL environments into goal-conditioned ones by wrapping the environment to make any observation a potential goal. The agent is trained without reference to external reward signals, relying solely on self-selected goals for exploration and learning. The method is agnostic to environment specifics and underlying off-policy learning algorithms, and is implemented as a modular extension to the Stable-Baselines3 RL framework.
Methodological Framework
Goal-Conditioned Environment Wrapping
The central methodological innovation is an environment wrapper that augments any RL environment with goal-conditioning capabilities. Goals correspond to points in the observation space, and are provided as inputs to the agent alongside regular observations. This wrapping enables evaluation of goal achievement independent of inherent environment termination or native reward functions.
Modular components include:
- Goal Success Evaluation: Either normalized distance (continuous spaces) or exact matching (discrete spaces).
- Goal Termination: Episodes terminate when the agent reaches the specified goal.
- Goal Selection: Three strategies are implemented:
- Uniform random sampling
- Novelty-driven selection, prioritizing rarely visited cells via visitation counts
- Intermediate success rate selection, targeting goals with performance closest to a predefined success rate
All strategies supplement selection with a baseline randomized portion to avoid local minima in goal targeting.
Training and Architecture Details
Agents are trained with off-policy algorithms, primarily DQN with Hindsight Experience Replay (HER). Network architectures include a standard multilayer perceptron and a ResNet-inspired variant. Hyperparameters and training durations are set to match the complexity of each environment.
Experimental Setup
Experiments are conducted on three environments:
- Cliff Walker: Discrete grid world with deterministic transitions and unreachable cliff states.
- Frozen Lake: Discrete grid, stochastic transitions, multiple goals with varying attainability.
- Pathological Mountain Car: Continuous state space, two terminals (one hard-to-reach), no per-step penalty.
Evaluation metrics include goal success rates (both average and individual), reward over time, and ability to achieve specific (hard) goals.
Empirical Results
Efficiency Relative to Reward-Guided Baselines
In Cliff Walker, the goal-conditioned agent consistently reaches optimal behavior faster than the externally rewarded baseline.
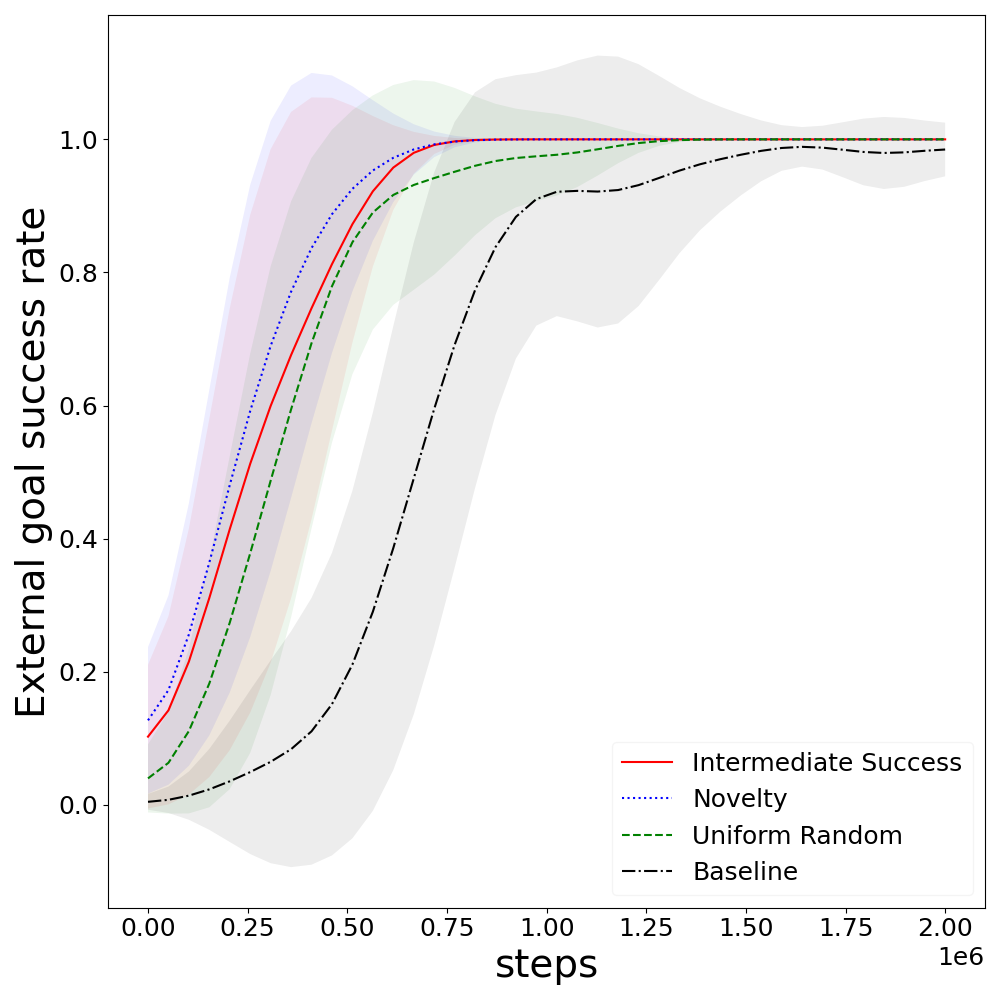
Figure 1: Comparative time to reach optimal policy in Cliff Walker.
The agent, despite being oblivious to external negative reward signals, displays superior convergence speed, demonstrating that reward-free goal conditioning does not compromise task proficiency.
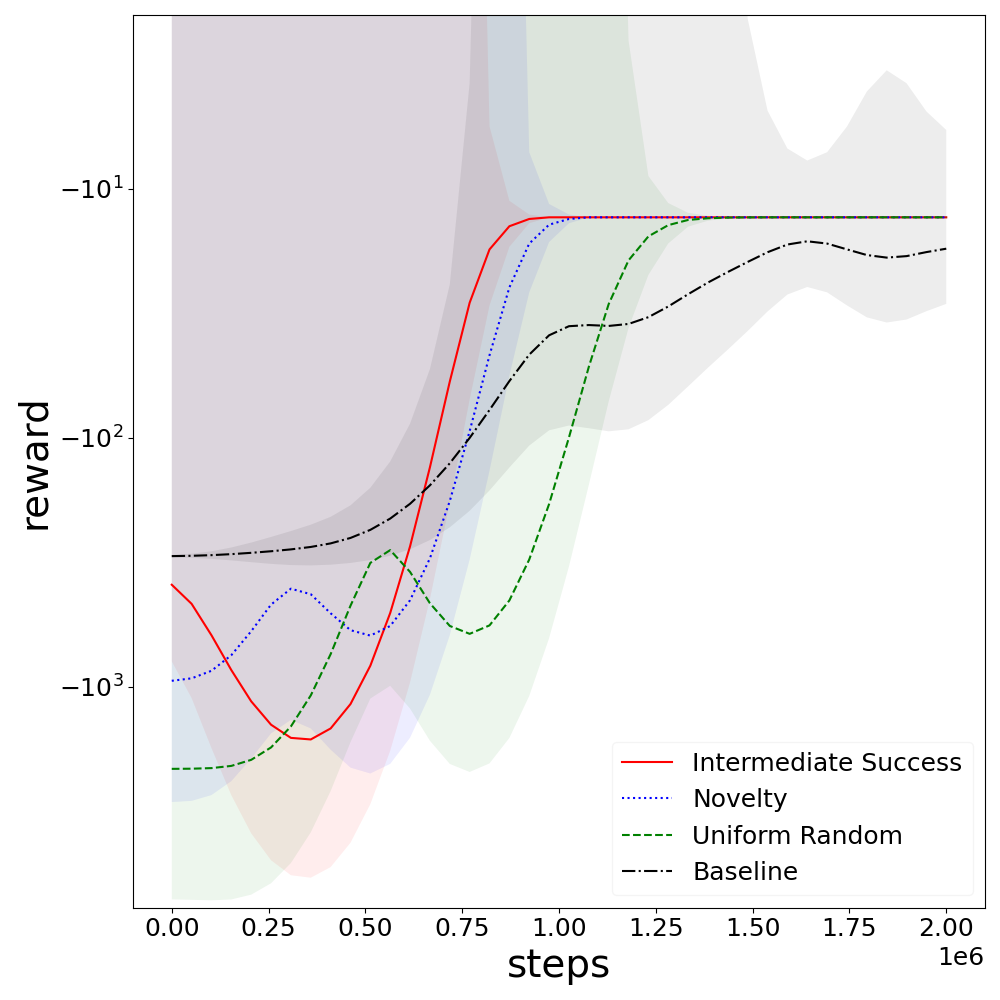
Figure 2: Reward profile in Cliff Walker shows faster convergence but less avoidance of negative rewards during early training.
For Frozen Lake, reward-free methods achieve stable performance at rates comparable with reward-informed RL, although optimality lags behind due to the environment's stochasticity and deceptive goals.
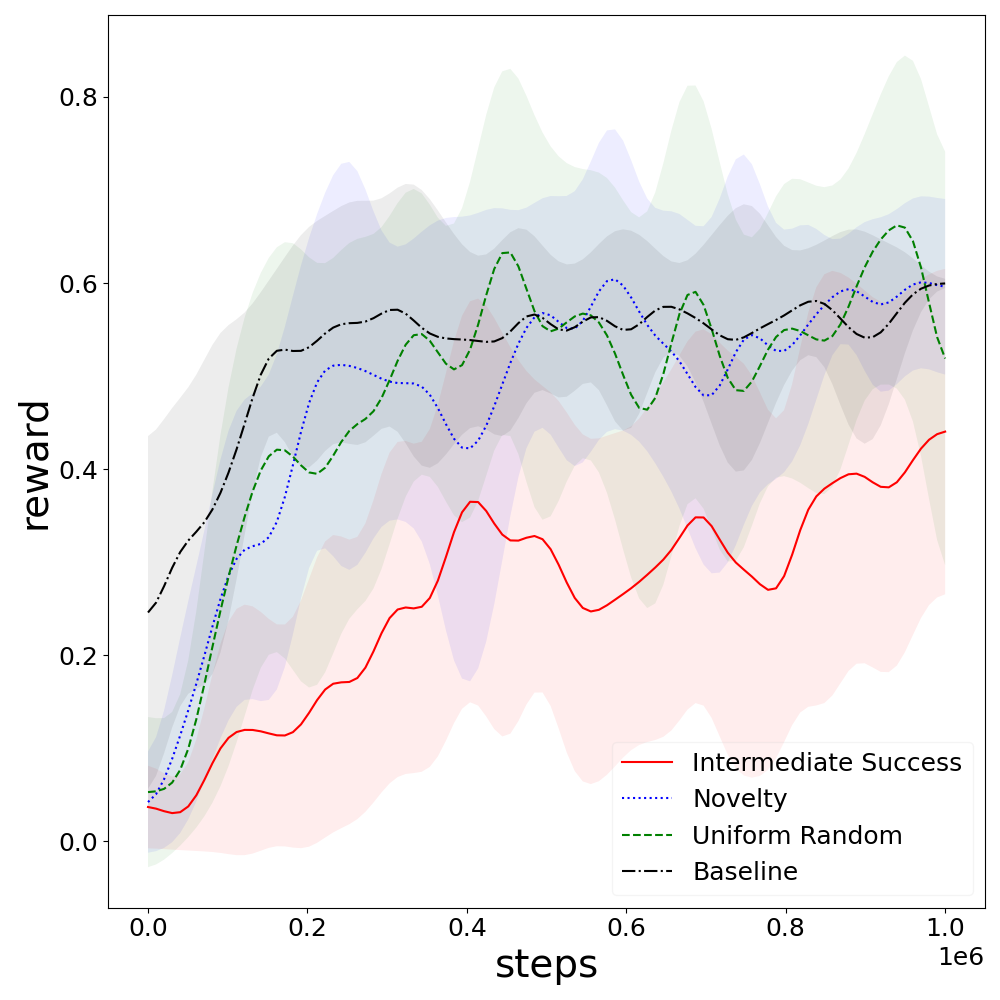
Figure 3: Relative learning rates for different goal selection methods in Frozen Lake.
Intermediate difficulty selection underperforms in Frozen Lake due to goal selection bias caused by stochastic transitions aligning target success rates with suboptimal goals.
In Pathological Mountain Car, the goal-conditioned agent achieves the hard goal more often and faster than the RL baseline, although persistent ability to reach this goal is not retained without targeted selection.
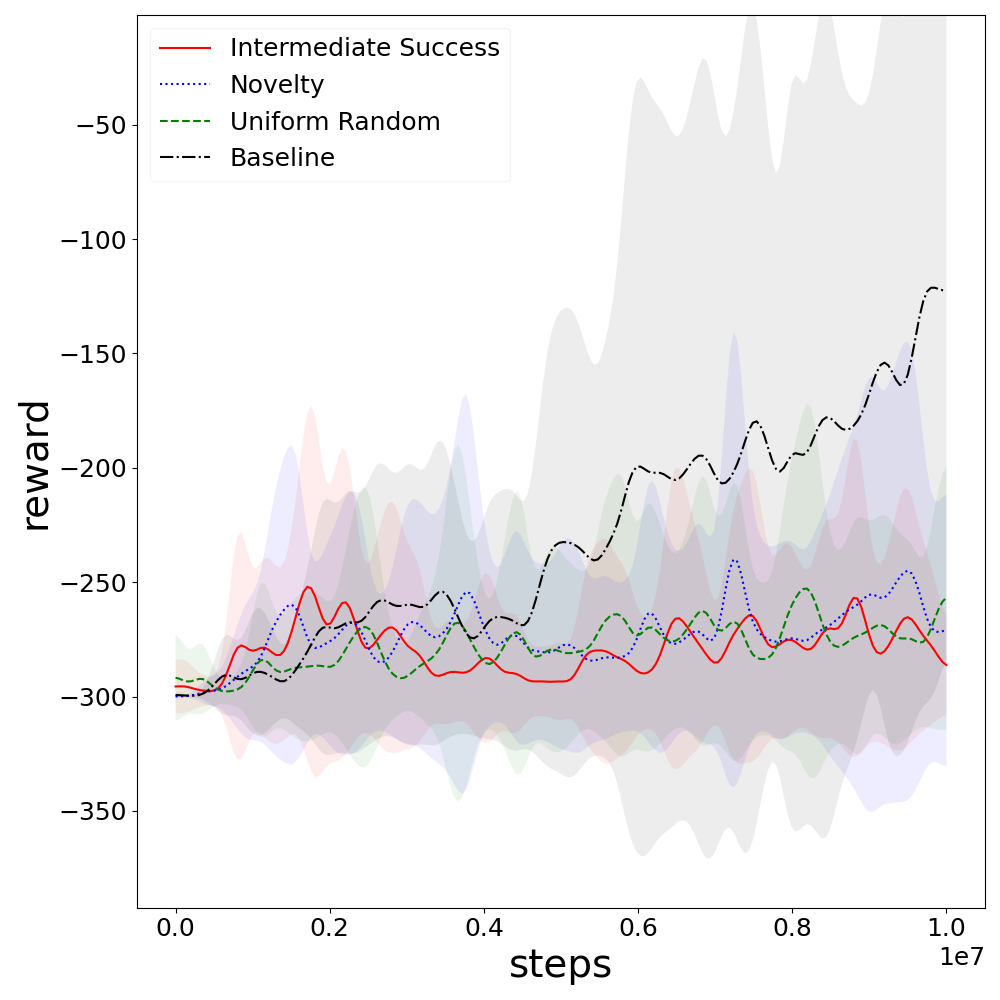
Figure 4: Early attainment of high-reward goals in Pathological Mountain Car with goal conditioning.
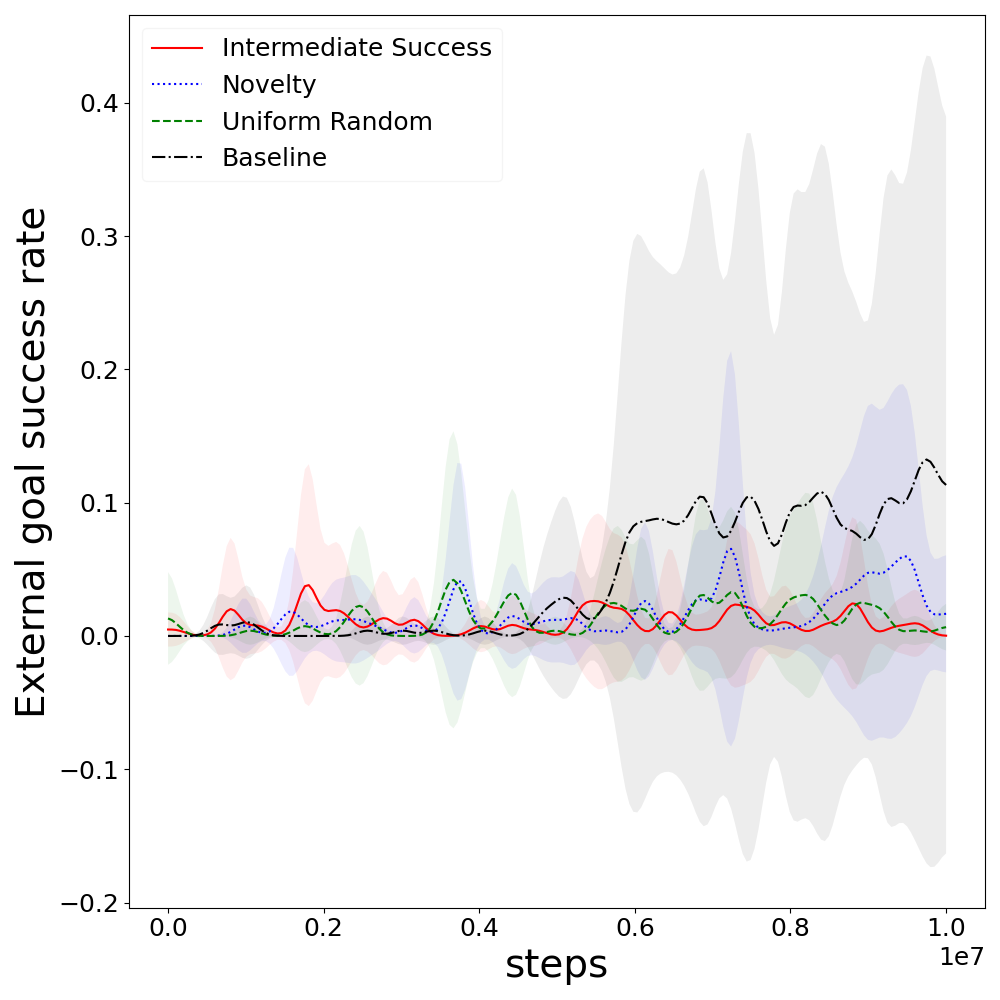
Figure 5: Goal-conditioned agent achieves hard goal faster but fails to maintain proficiency due to lack of targeted focus.
Goal Success Dynamics
Across all environments, aggregate goal success rates demonstrate stabilization after initial fluctuations, even as individual goal performance exhibits instability—especially in high-dimensional or stochastic settings.
In Cliff Walker, average goal success rate rapidly approaches the theoretical maximum given unrecoverable states.
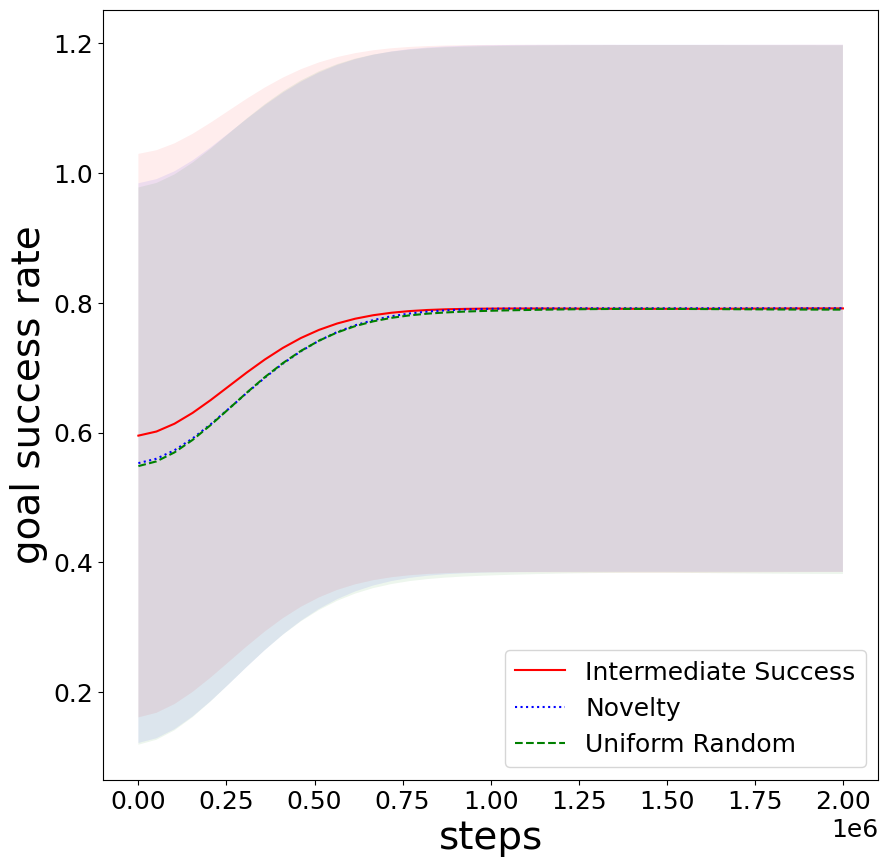
Figure 6: Stabilization of average goal success rates in Cliff Walker.
Individual goals show synchronized learning, with minor lag for externally rewarded tasks.
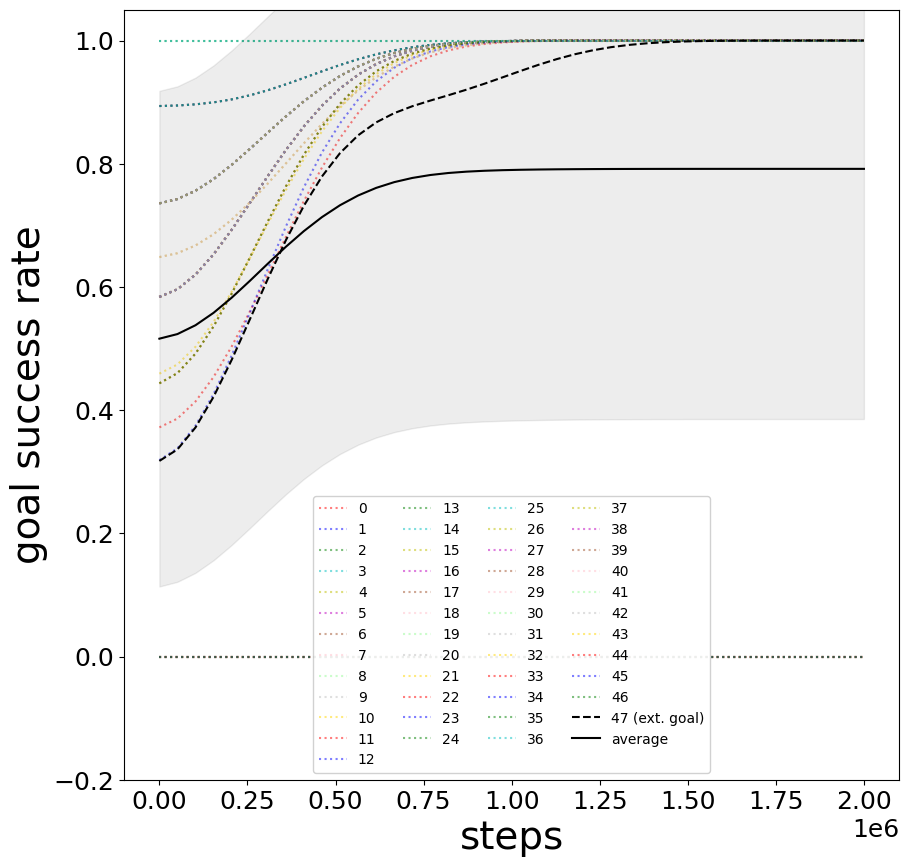
Figure 7: Rapid convergence of goal success across most targets in Cliff Walker.
Frozen Lake experimental traces illustrate high volatility for individual goals; however, ensemble average success stabilizes satisfactorily.
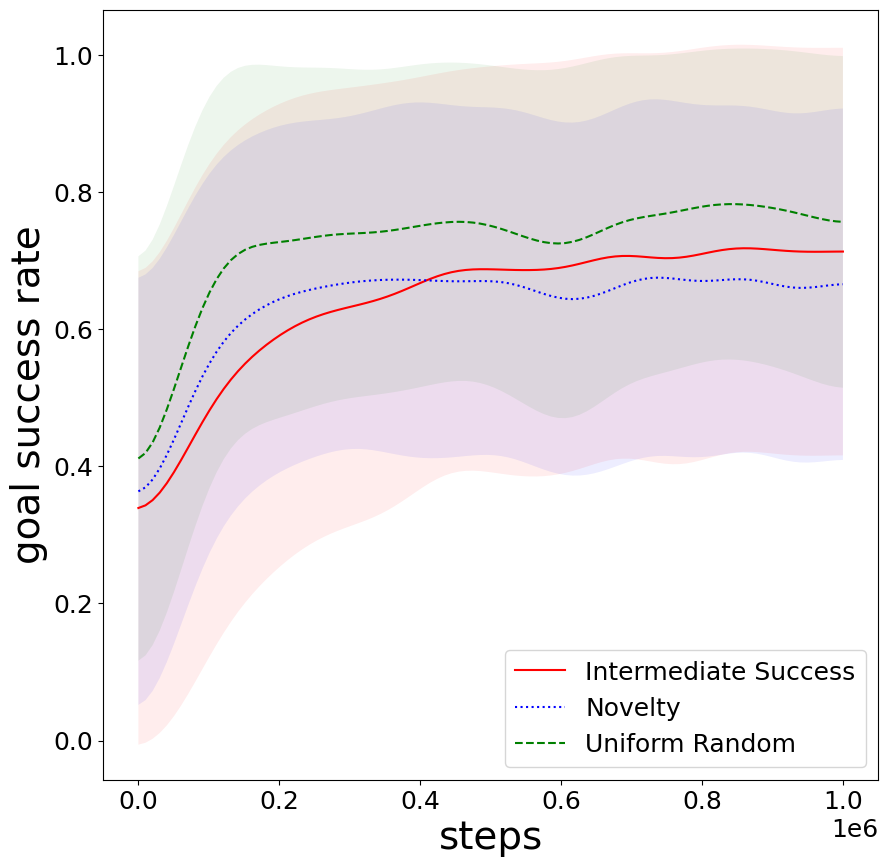
Figure 8: Average goal success stabilization in stochastic Frozen Lake environment.
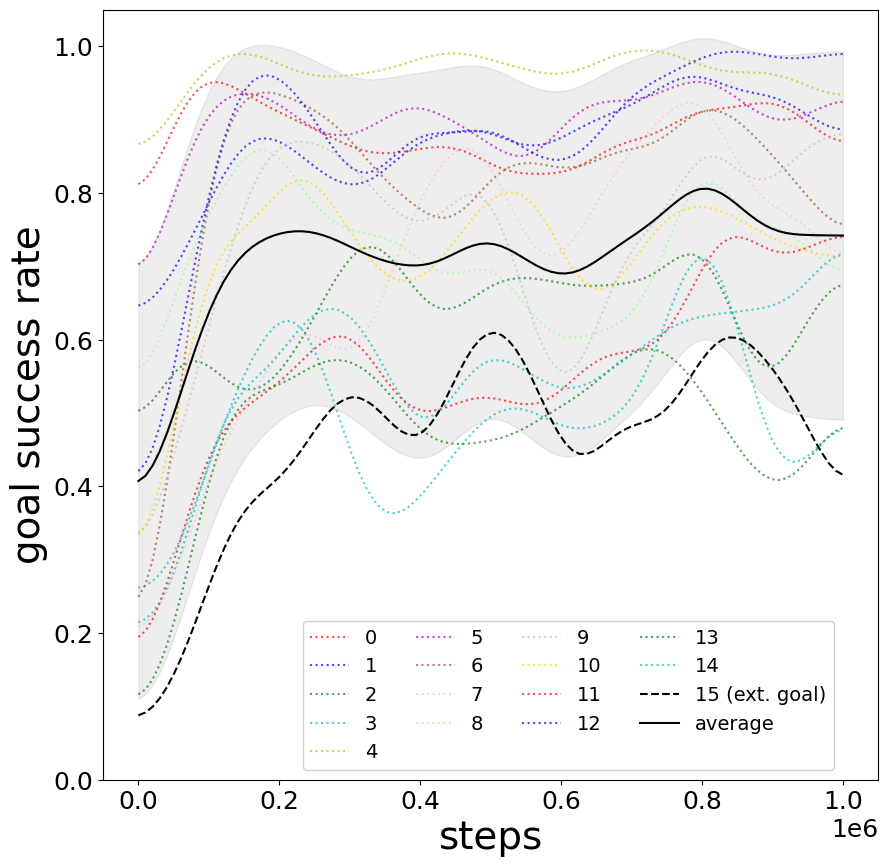
Figure 9: Fluctuation of individual goal performance over time in Frozen Lake.
Pathological Mountain Car illustrates slow but consistent improvement in average goal success over prolonged training, while the ability to reliably reach individual goals—particularly hard ones—remains non-monotonic.
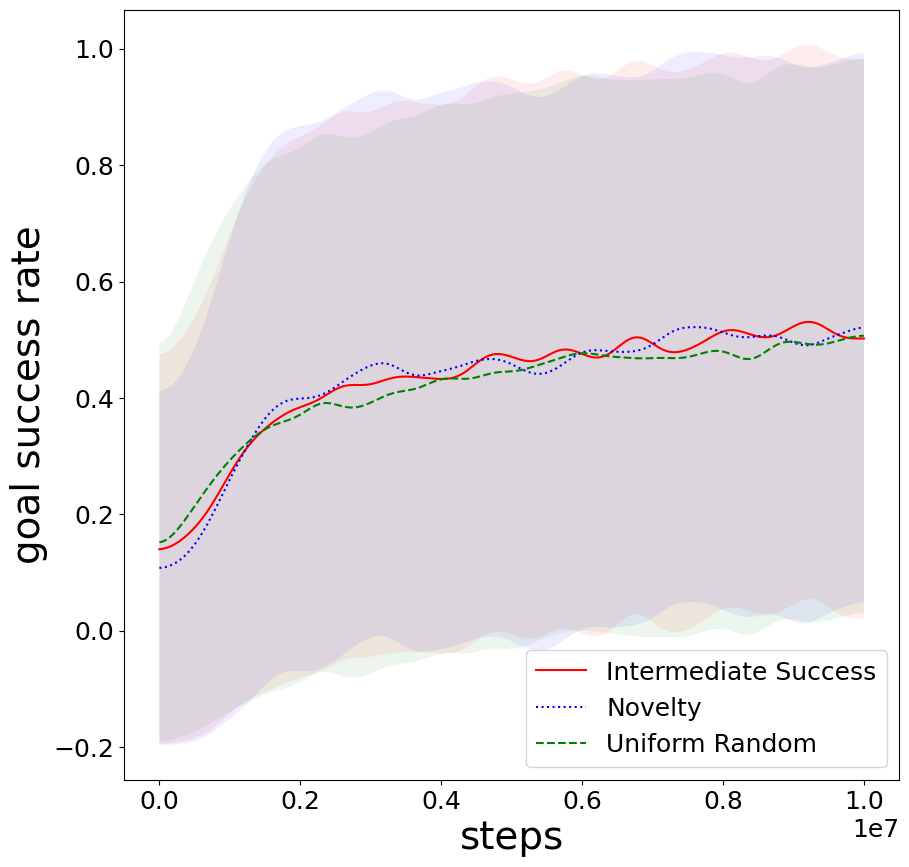
Figure 10: Slow incremental improvement for average goal success in Pathological Mountain Car.
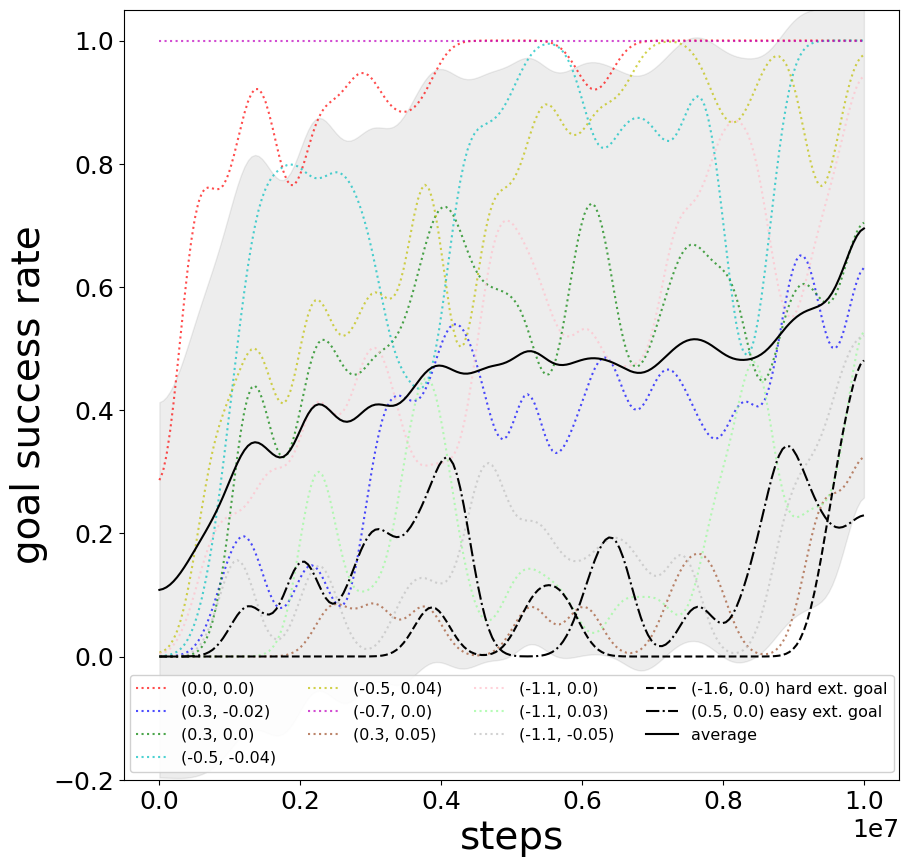
Figure 11: Persistent instability in individual goal performance during training on Pathological Mountain Car.
Theoretical and Practical Implications
The study demonstrates that generic goal-conditioning—without exposure to external rewards—enables agents to acquire a repertoire of skills across diverse environments at competitive training speeds. This has significant implications for real-world applications where reward engineering is infeasible or the task specification is post-training.
The environment-agnostic design supports transferability and universality, facilitating pre-training agents capable of adapting to arbitrary downstream goals. However, the method currently suffers from limitations in individual goal retention, episodic forgetting, and susceptibility to deceptive or unreachable goals—challenges aggravated in stochastic or high-dimensional environments.
Future Directions
Potential future work may address:
- Incorporation of model-based learning to decouple transition dynamics from policy optimization.
- Enhanced goal selection targeting using online metrics or adaptive curriculum learning.
- Broader goal representations, including ranges, embeddings, and multi-modal targets for partially observable settings.
- Replay buffer prioritization and experience selection to counteract instability and forgetting.
- Quantitative ablation studies on individual architectural and algorithmic choices.
Conclusion
The presented approach confirms that goal-conditioning and autonomous curriculum generation enable effective, reward-free RL across varied environments. While attaining aggregate stability and competitive proficiency, future research must further mitigate individual goal volatility and exploit scalable goal representations to maximize autonomous skill acquisition. This environment-agnostic framework sets a foundation for rapidly deployable, task-agnostic agents capable of generalization and retrospective skill assignment.