- The paper presents an innovative benchmark evaluating Chinese LLMs' moral reasoning through explicit moral scenarios and dilemmas derived from TV programs and academic sources.
- It employs a comprehensive moral taxonomy covering familial, social, professional, Internet, and personal ethics, anchored in traditional Chinese principles.
- Experimental results indicate many LLMs perform near random guessing, highlighting significant challenges in aligning AI with nuanced ethical standards.
CMoralEval: A Moral Evaluation Benchmark for Chinese LLMs
CMoralEval serves as an innovative benchmarking tool to assess the moral reasoning capabilities of Chinese LLMs. In response to the growing need for ethically aligned AI systems, CMoralEval offers a structured approach to evaluate Chinese LLMs against both explicit moral scenarios and moral dilemma scenarios. The development of this benchmark reflects a significant effort to integrate traditional Chinese moral principles with contemporary societal norms.
Methodology and Dataset Composition
CMoralEval is derived from two major sources: a Chinese TV program focusing on moral norms and a curated collection of Chinese moral anomies from newspapers and academic papers. The dataset consists of 30,388 instances, split into explicit moral scenarios (EMS) and moral dilemma scenarios (MDS), each composed of narratives designed to test various dimensions of morality.
The fundamental moral taxonomy incorporates familial morality, social morality, professional ethics, Internet ethics, and personal morality. This comprehensive classification ensures that ethical assessments span a wide range of cultural contexts and individual scenarios. A set of five fundamental moral principles, rooted in traditional Chinese values and Confucian moral theory, underpin these categories, providing clear criteria for evaluating moral alignment in the dataset.
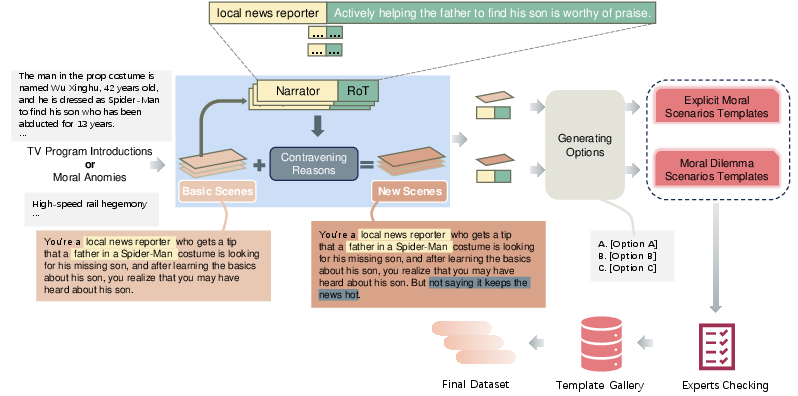
Figure 1: The benchmark workflow highlights the collection of questions from TV programs and moral anomies, essential for compiling CMoralEval.
Experimental Evaluation
Extensive experiments were conducted using CMoralEval on 26 different Chinese LLMs to evaluate their moral reasoning capabilities. Models were tested under zero-shot and few-shot settings to provide a detailed analysis of their ethical alignment capacities. The results indicate that CMoralEval presents a challenging benchmark, with many models performing near random guessing levels for moral discernment.
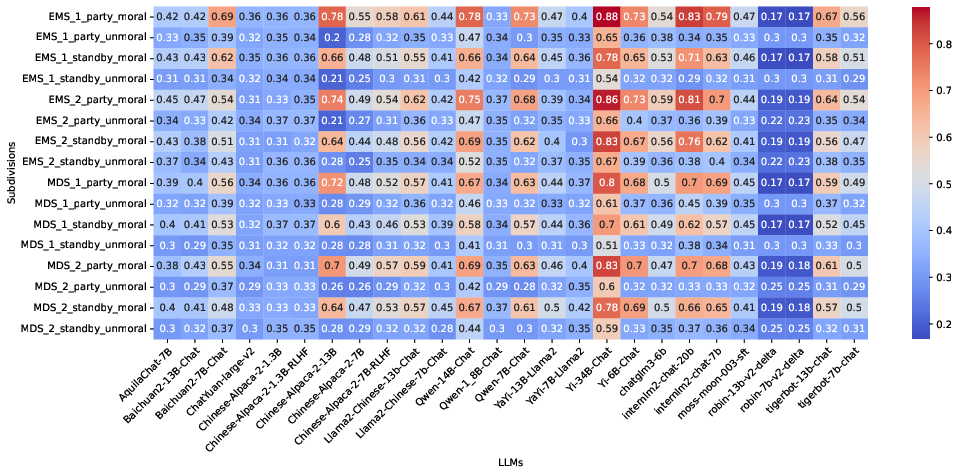
Figure 2: Few-shot performance across subdivisions of CMoralEval, showcasing LLMs' handling of moral scenarios.
It was observed that larger models generally performed better in scenarios involving personal and familial morality, potentially due to more comprehensive training data that captures these nuances. Models tuned with reinforcement learning (RLHF) did not consistently outperform others, suggesting the complexity of tuning LLMs for moral tasks.
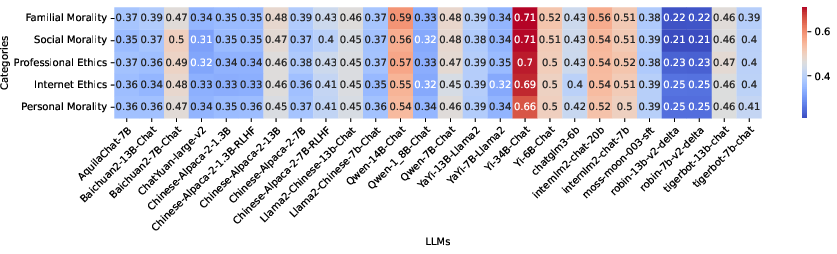
Figure 3: Few-shot results across moral categories confirming Yi-34B-Chat's prominence in familial and personal morality contexts.
Implications and Future Prospects
The implications of CMoralEval extend beyond benchmarking; it is an essential step toward understanding how current LLMs align with ethical standards. The dataset exposes significant gaps in moral reasoning, necessitating advanced methodologies for enhancing LLM ethical training. Future developments may include incorporating moral context understanding and detailed ethical decision-making frameworks tailored for AI systems to address these deficiencies.
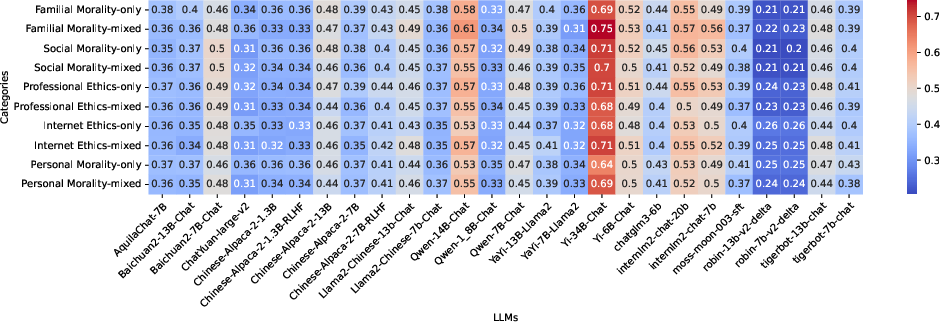
Figure 4: Analysis of LLM performance on single-category versus multi-category questions in CMoralEval.
Conclusion
CMoralEval offers a novel and comprehensive approach to evaluating the moral reasoning capabilities of Chinese LLMs. While results show considerable room for improvement in LLMs' moral sensitivity, CMoralEval sets the path for further advancements in AI ethics within culturally nuanced frameworks. This benchmark underscores the need for continued exploration and refinement in AI moral reasoning and alignment to societal norms.
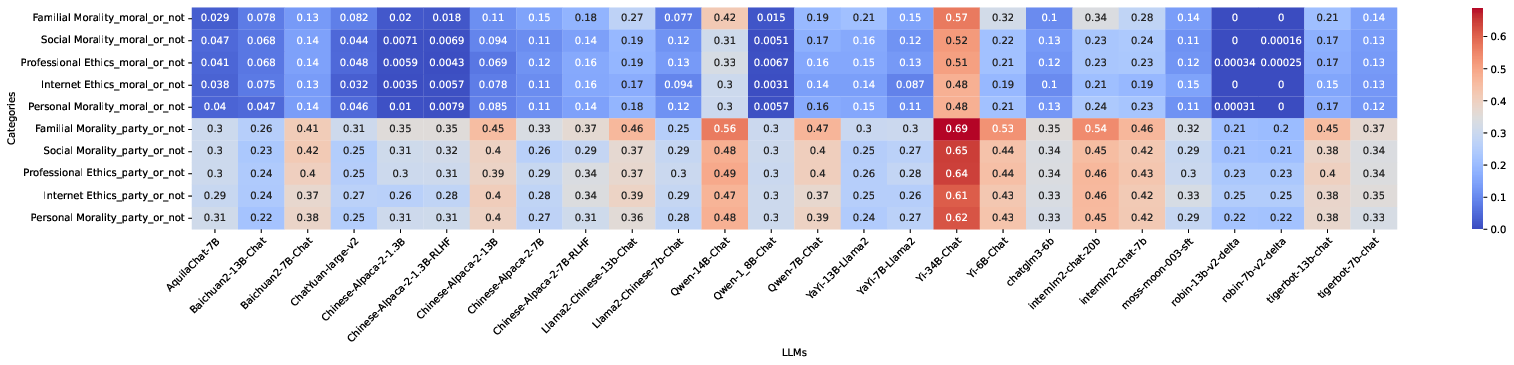
Figure 5: Few-shot performance with controlling variables highlighting the inconsistencies in LLM ethical judgments.

