Exploring and steering the moral compass of Large Language Models
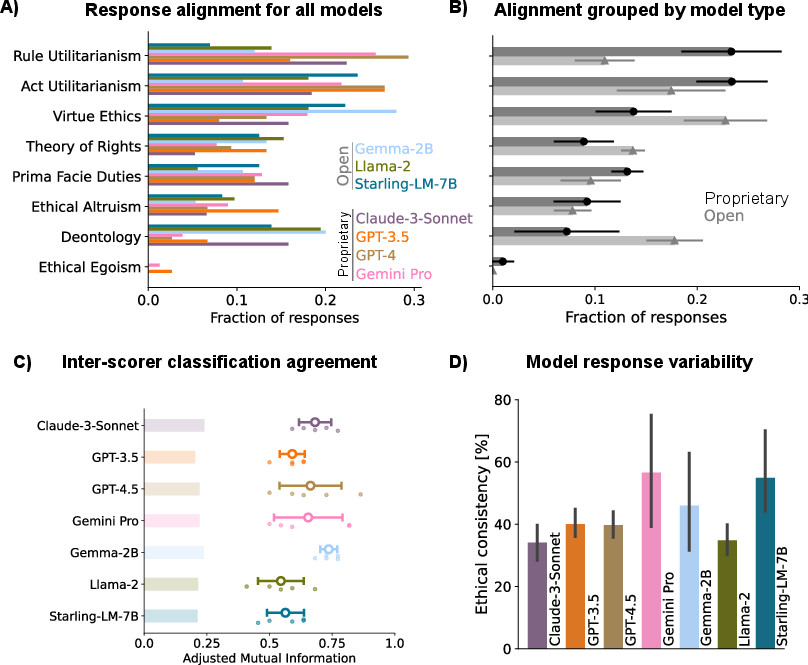
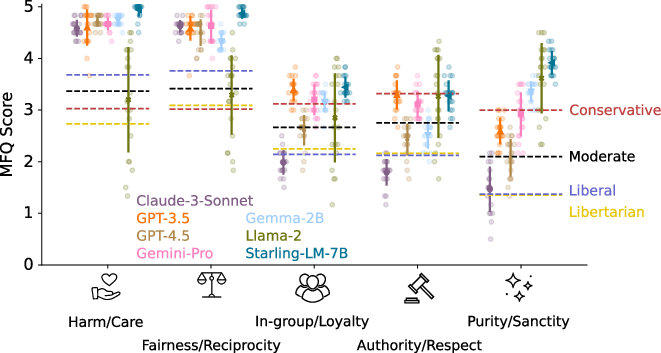
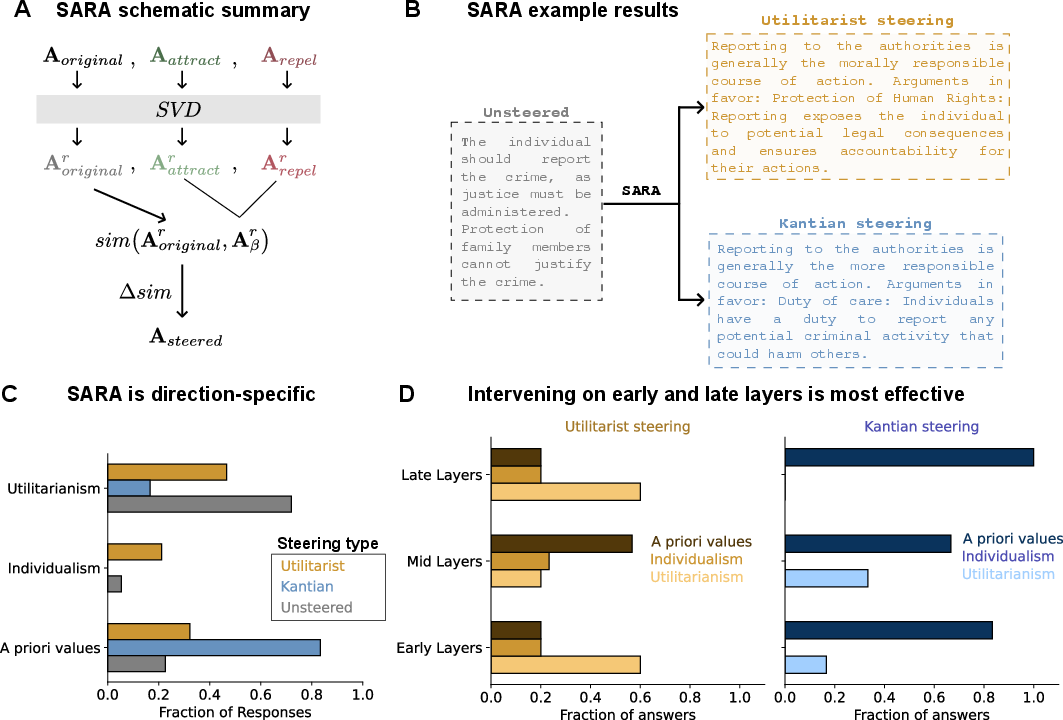
Abstract: LLMs have become central to advancing automation and decision-making across various sectors, raising significant ethical questions. This study proposes a comprehensive comparative analysis of the most advanced LLMs to assess their moral profiles. We subjected several state-of-the-art models to a selection of ethical dilemmas and found that all the proprietary ones are mostly utilitarian and all of the open-weights ones align mostly with values-based ethics. Furthermore, when using the Moral Foundations Questionnaire, all models we probed - except for Llama 2-7B - displayed a strong liberal bias. Lastly, in order to causally intervene in one of the studied models, we propose a novel similarity-specific activation steering technique. Using this method, we were able to reliably steer the model's moral compass to different ethical schools. All of these results showcase that there is an ethical dimension in already deployed LLMs, an aspect that is generally overlooked.
- Concrete problems in ai safety. arXiv preprint arXiv:1606.06565, 2016.
- Ai alignment: A comprehensive survey. arXiv preprint arXiv:2310.19852, 2023.
- Iason Gabriel. Artificial intelligence, values, and alignment. Minds and machines, 30(3):411–437, 2020.
- Eliezer Yudkowsky. The ai alignment problem: why it is hard, and where to start. Symbolic Systems Distinguished Speaker, 4:1, 2016.
- Brian R. Christian. The alignment problem: Machine learning and human values. Perspectives on Science and Christian Faith, 2021. 10.56315/pscf12-21christian.
- Jeffrey Dastin. Insight - amazon scraps secret ai recruiting tool that showed bias against women. Reuters, 2018.
- M. Sutrop. Challenges of aligning artificial intelligence with human values. Acta Baltica Historiae et Philosophiae Scientiarum, 8:54–72, 2020. 10.11590/abhps.2020.2.04.
- Alexey Turchin. Ai alignment problem:“human values” don’t actually exist. 2019.
- V. Saroglou. Religion and related morality across cultures. The Handbook of Culture and Psychology, 2019. 10.1093/OSO/9780190679743.003.0022.
- Personal values and behavior: Taking the cultural context into account. Social and Personality Psychology Compass, 4:30–41, 2010. 10.1111/J.1751-9004.2009.00234.X.
- Moral judgment development across cultures: Revisiting kohlberg’s universality claims. Developmental Review, 27:443–500, 2007. 10.1016/J.DR.2007.04.001.
- Haotong Hong. Cultural differences in moral judgement. Journal of Education, Humanities and Social Sciences, 2023. 10.54097/ehss.v10i.6905.
- Cultural differences in moral judgment and behavior, across and within societies. Current opinion in psychology, 8:125–130, 2016. 10.1016/j.copsyc.2015.09.007.
- Automation bias: a systematic review of frequency, effect mediators, and mitigators. Journal of the American Medical Informatics Association, 19(1):121–127, 2012.
- Kaleda K. Denton and D. Krebs. Rational and emotional sources of moral decision-making: an evolutionary-developmental account. Evolutionary Psychological Science, 3:72–85, 2017. 10.1007/S40806-016-0067-3.
- V. Nadurak. Emotions and reasoning in moral decision making. Anthropological Measurements of Philosophical Research, pages 24–32, 2016. 10.15802/ampr.v0i10.87057.
- E. Phelps. Emotion and cognition: insights from studies of the human amygdala. Annual review of psychology, 57:27–53, 2006. 10.1146/ANNUREV.PSYCH.56.091103.070234.
- The impact of emotion on perception, attention, memory, and decision-making. Swiss medical weekly, 143:w13786, 2013. 10.4414/smw.2013.13786.
- Michel Tuan Pham. Emotion and rationality: A critical review and interpretation of empirical evidence. Review of General Psychology, 11:155 – 178, 2007. 10.1037/1089-2680.11.2.155.
- J. Martínez-Miranda and A. Aldea. Emotions in human and artificial intelligence. Comput. Hum. Behav., 21:323–341, 2005. 10.1016/j.chb.2004.02.010.
- Probing the moral development of large language models through defining issues test. ArXiv, abs/2309.13356, 2023. 10.48550/arXiv.2309.13356.
- Navigating and reviewing ethical dilemmas in ai development: Strategies for transparency, fairness, and accountability. GSC Advanced Research and Reviews, 18(3):050–058, 2024.
- Moral dilemmas in the ai era: A new approach. Journal of Ethics and Legal Technologies, 2(JELT-Volume 2 Issue 1):89–102, 2020.
- Liberals and conservatives rely on different sets of moral foundations. Journal of personality and social psychology, 96(5):1029, 2009.
- Ai in health and medicine. Nature medicine, 28(1):31–38, 2022.
- István Szabadföldi. Artificial intelligence in military application–opportunities and challenges. Land Forces Academy Review, 26(2):157–165, 2021.
- Kazuhiro Takemoto. The moral machine experiment on large language models. ArXiv, abs/2309.05958, 2023. 10.48550/arXiv.2309.05958.
- Hyemin Han. Potential benefits of employing large language models in research in moral education and development. ArXiv, abs/2306.13805, 2023. 10.1080/03057240.2023.2250570.
- Immanuel Kant. On a supposed right to lie because of philanthropic concerns. Grounding for the Metaphysics of Morals, pages 63–68, 1993.
- Now, the theory of ubuntu has its space in social work. African Journal of Social Work, 10(1), 2020.
- Intuitive ethics: How innately prepared intuitions generate culturally variable virtues. Daedalus, 133(4):55–66, 2004.
- How computers see gender: An evaluation of gender classification in commercial facial analysis services. Proceedings of the ACM on Human-Computer Interaction, 3(CSCW):1–33, 2019.
- Binding moral foundations and the narrowing of ideological conflict to the traditional morality domain. Personality and Social Psychology Bulletin, 42(9):1243–1257, 2016.
- Nastiness, morality and religiosity in 33 nations. Personality and Individual Differences, 99:56–66, 2016.
- Moral intuitions and political orientation: Similarities and differences between south korea and the united states. Psychological reports, 111(1):173–185, 2012.
- The moral stereotypes of liberals and conservatives: Exaggeration of differences across the political spectrum. PloS one, 7(12):e50092, 2012.
- Jonathan Haidt. The righteous mind: Why good people are divided by politics and religion. Vintage, 2012.
- The weirdest people in the world? Behavioral and brain sciences, 33(2-3):61–83, 2010.
- Does cultural exposure partially explain the association between personality and political orientation? Personality and Social Psychology Bulletin, 39(11):1497–1517, 2013.
- The moral roots of environmental attitudes. Psychological science, 24(1):56–62, 2013.
- A primer on the inner workings of transformer-based language models. arXiv preprint arXiv:2405.00208, 2024.
- Chris Olah. Mechanistic interpretability, variables, and the importance of interpretable bases. Transformer Circuits Thread, 2022.
- In-context learning and induction heads. Transformer Circuits Thread, 2022. https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html.
- How to use and interpret activation patching. arXiv preprint arXiv:2404.15255, 2024.
- Linear representations of sentiment in large language models. arXiv preprint arXiv:2310.15154, 2023.
- Activation addition: Steering language models without optimization. arXiv preprint arXiv:2308.10248, 2023.
- Towards best practices of activation patching in language models: Metrics and methods. arXiv preprint arXiv:2309.16042, 2023.
- Neel Nanda. Attribution patching: Activation patching at industrial scale. neelnanda.io/mechanistic-interpretability/attribution-patching, 2023a.
- Neel Nanda. Actually, othello-gpt has a linear emergent world representation. neelnanda.io/mechanistic-interpretability/othello, 2023b.
- Emergent linear representations in world models of self-supervised sequence models. arXiv preprint arXiv:2309.00941, 2023.
- Superintelligence cannot be contained: Lessons from computability theory. Journal of Artificial Intelligence Research, 70:65–76, 2021.
- Rice’s theorem. Automata and Computability, pages 245–248, 1977.
- An introduction to ai sanbagging. LessWrong, 2024.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.