- The paper presents Eigen Attention, which achieves significant KV cache compression by projecting attention matrices onto a low-rank subspace using SVD.
- The method integrates with existing compression strategies to reduce memory footprint by 40% and cut attention latency by 60%, enhancing inference efficiency.
- Experimental results on models like OPT, MPT, and Llama confirm that Eigen Attention reduces computational cost without requiring additional fine-tuning.
Eigen Attention: Attention in Low-Rank Space for KV Cache Compression
Introduction
The vast capabilities of LLMs have driven significant advancements in natural language processing. Nevertheless, increasing the context lengths for these models is pivotal in elevating their performance on complex tasks such as document summarization and extensive text analysis. The KV cache, responsible for storing attention keys and values, becomes a memory bottleneck during inference at extended context lengths and larger batch sizes. To mitigate this challenge, the proposed Eigen Attention technique uniquely operates within a low-rank space to alleviate KV cache memory burdens. This paper demonstrates that Eigen Attention synergistically integrates with existing KV cache compression strategies, resulting in a substantial reduction in both memory footprint and computational latency.
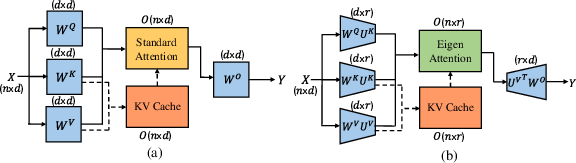
Figure 1: Comparison between (a) Standard Attention and (b) Eigen Attention. Eigen Attention utilizes lower dimensional (r≪d) query, key, and value projection matrices than the standard attention operation, leading to KV cache compression and compute FLOPs benefits.
Methodology
Eigen Attention introduces low-rank approximation, projecting key, query, and value matrices into a low-dimensional subspace. This is achieved by employing Singular Value Decomposition (SVD) on these matrices derived from a calibration dataset, followed by rigorous basis vector selection based on pre-defined error thresholds. Attention operations are conducted in this compressed space, thus minimizing memory overhead without necessitating additional fine-tuning.
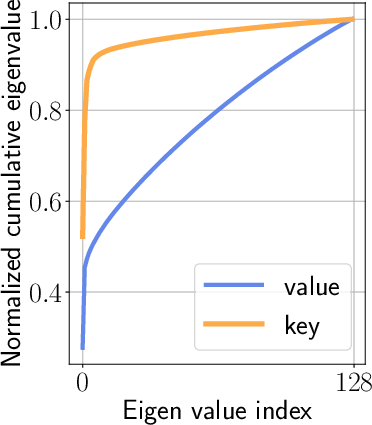
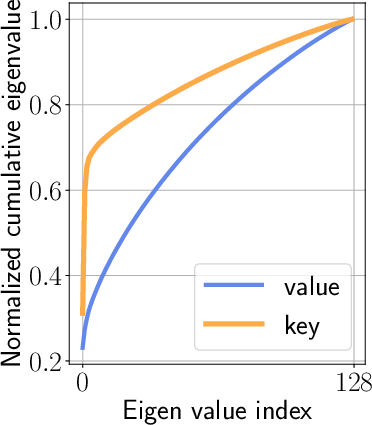
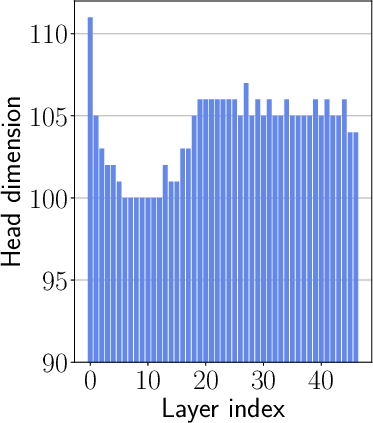
Figure 2: Layer #15 Head #16
Experimentation and Results
The experimentation spans extensive comparisons across models such as OPT, MPT, and Llama, demonstrating impressive KV cache reductions with negligible performance loss. Specifically, Eigen Attention contributes to a 40% reduction in KV cache size and a remarkable 60% decrease in attention operation latency, affirming its computational efficiency.
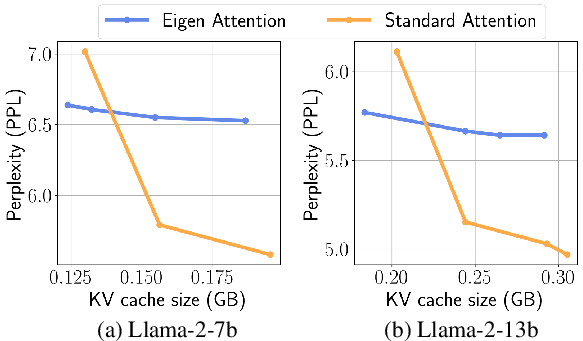
Figure 3: Perplexity on Wikitext with different KV cache sizes in GB (n = 2048) obtained via different quantization precision and group size. For Eigen Attention, we compress the KV cache to 0.6x and then apply quantization.
Future Directions
The potential for further developments around Eigen Attention involves exploring its integration with varied compression methodologies to achieve even greater cache reductions while maintaining model efficacy. Additionally, applying Eigen Attention within comprehensive efficient LLM serving frameworks could bolster inference throughput and model accessibility across diverse applications.
Conclusion
Eigen Attention represents a pivotal enhancement to KV cache management in LLMs, showcasing significant reductions in both memory usage and inference latency. Its orthogonal nature allows seamless integration with existing compression techniques, fortifying its applicability across a wide range of NLP tasks and models. As future endeavors explore maximizing compression efficacy, Eigen Attention stands as a formidable tool propelling the capabilities of high-performance LLMs.