- The paper provides a comprehensive survey of deep learning approaches for processing visually rich document content.
- The paper categorizes frameworks into mono-task and multi-task models, leveraging multimodal cues from text, images, and layout.
- The paper identifies future research directions, emphasizing zero-shot learning, improved multimodal fusion, and robust evaluations.
Deep Learning based Visually Rich Document Content Understanding: A Survey
The field of visually rich document understanding (VRDU) has undergone significant developments due to the rapid advancements in deep learning. This survey comprehensively reviews the existing VRDU frameworks, categorizing them based on strategies such as encoding methods, model architectures, pretraining techniques, and the integration of multimodal information. The paper further identifies emerging trends and challenges, offering insights into future research directions and practical applications.
Introduction to Visually Rich Document Understanding
Visually rich documents (VRDs) are ubiquitous in various domains like academia, finance, and medicine, characterized by their multimodal information, including text, images, and structured layouts. Traditional methods for extracting information from VRDs rely heavily on manual effort and expert knowledge, which is costly and inefficient. However, with advancements in deep learning, new models leverage multimodal information from vision, text, and layout to create comprehensive document representations capable of significantly enhancing information extraction accuracy and efficiency in VRDs.
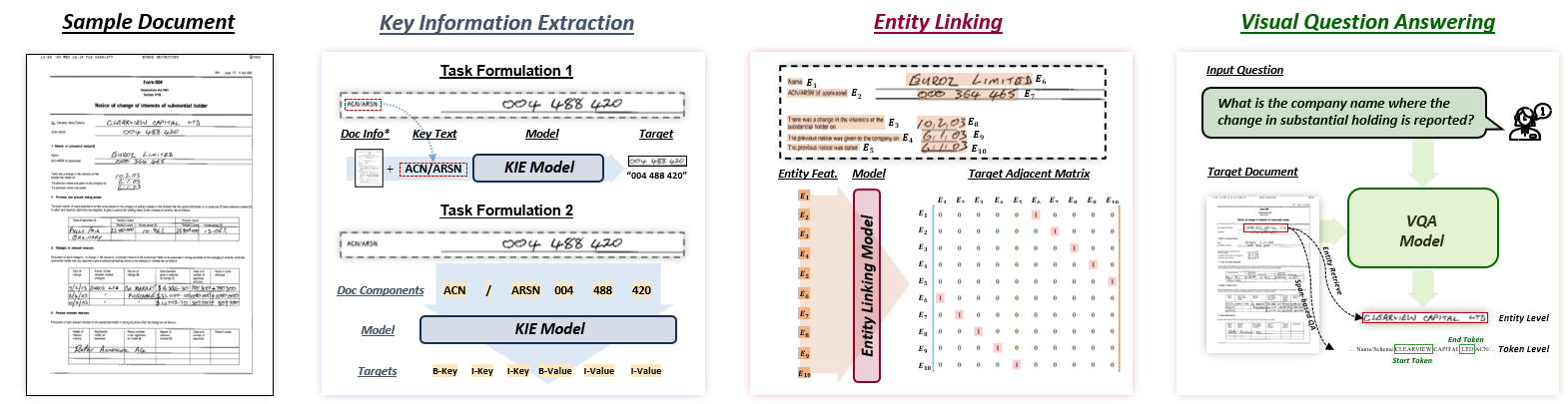
Figure 1: Visually rich document content understanding task clarifications.
Frameworks for VRDU
The paper categorizes VRDU frameworks into mono-task and multi-task models, each designed for specific applications or multiple downstream tasks, respectively. Mono-task models focus on individual tasks like Key Information Extraction (KIE), Entity Linking (EL), or Visual Question Answering (VQA). In contrast, multi-task frameworks are capable of handling several VRDU tasks, supporting the complex interplay of textual, visual, and layout information.
Mono-Task Models
Mono-task models leverage specialized design strategies for efficient performance on dedicated tasks:
- Key Information Extraction (KIE): Methods include feature-driven models using multimodal cues or joint-learning frameworks integrating auxiliary tasks for enhanced representation learning. Relation-aware models further employ graph-based techniques to capture spatial and logical relationships within documents.
- Entity Linking (EL): This involves identifying logical relationships like parent-child or key-value pairs between document entities. Techniques such as graph neural networks (GNNs) and attention-based methods are employed to capture these relations effectively.
- Visual Question Answering (VQA): Involves generating answers to natural language questions based on document images. Single-page document VQA typically uses pretrained LLMs, while multi-page scenarios demand more advanced solutions due to input length limitations.
Multi-Task Models
Multi-task models enhance document understanding by leveraging pretraining strategies and architectures that support multiple downstream tasks.
Feature Representation and Fusion
The survey emphasizes the importance of feature representation and fusion in VRDU models:
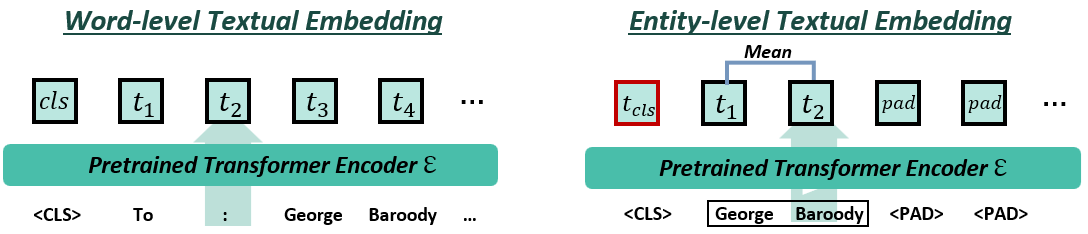
- Textual Representation: Utilizes embeddings like BERT and layout-aware models to capture contextual relationships.
- Visual Representation: Extracts visual features using CNNs or Vision Transformers, contributing to comprehensive document understanding beyond textual information.
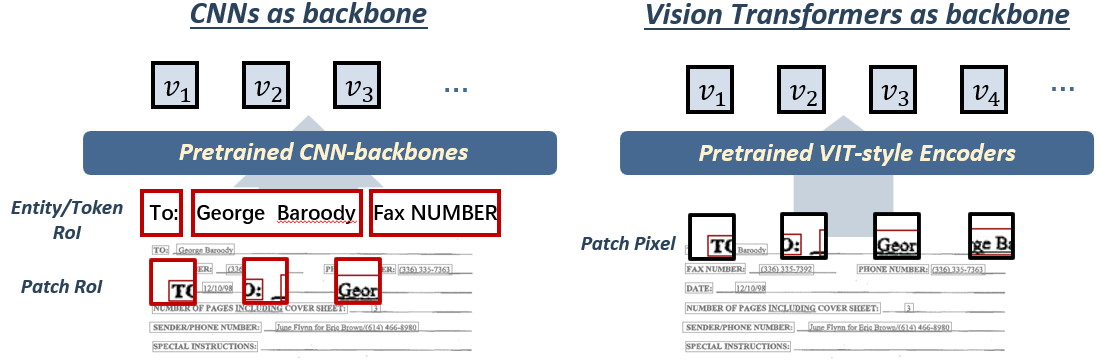
Figure 3: Commonly adopted visual information encoding approaches.
- Layout Representation: Encodes spatial relationships using positional encodings, linear projections, or spatial-aware attention mechanisms, crucial for capturing document structure.

Figure 4: Commonly adopted layout information encoding approaches.
- Multi-Modal Fusion: Methods include additive and concatenative integration or advanced techniques like cross-modality attention, ensuring effective interaction among modalities.

Figure 5: Commonly adopted multi-modality fusion methods.
Conclusion
The paper concludes by identifying trends and future research directions, such as exploring zero-shot and few-shot learning opportunities, improving cross-modality interaction, and addressing challenges like real-world application adaptability and robust model evaluations. By surveying VRDU advancements, the paper provides a comprehensive understanding beneficial for academic and industrial sectors, setting a foundation for further research and development in AI-driven document understanding.