- The paper introduces a spring-block model that captures feature learning dynamics in DNNs by mapping training parameters into mechanical analogs of elasticity and friction.
- It employs a noise-nonlinearity phase diagram to distinguish regimes of lazy versus active training, highlighting conditions that boost performance in shallow or deep layers.
- The study demonstrates that balanced load curves, achieved by modulating noise and nonlinearity, correlate with superior generalization performance in deep learning.
A Spring-Block Theory of Feature Learning in Deep Neural Networks
Introduction
The paper "Spring-block theory of feature learning in deep neural networks" aims to address the conceptual gap between microscopic neuronal dynamics and macroscopic feature learning in deep learning (DL). It introduces a mechanical analogy using a spring-block model to explain the dynamics of feature learning in deep neural networks (DNNs), characterized by the interaction of nonlinearity, noise, and other training parameters.
Key Concepts and Models
Feature Learning in DNNs
Feature learning in DNNs involves the progressive transformation of input data into a low-dimensional space to facilitate accurate predictions by the final layers. The paper identifies conditions under which feature learning occurs more effectively—either in shallow or deep layers—through a noise-nonlinearity phase diagram.

Figure 1: Phase diagrams of DNN load curves (red) for nonlinearity vs. (a) data noise, (b) learning rate, (c) dropout, and (d) batch size.
This diagram reveals the existence of distinct regimes that either promote or inhibit feature learning across layers. It also demonstrates the universality of the phenomenon across different stochasticity sources like dropout and learning rate adjustments.
Spring-Block Model
To explain the observed dynamics, the paper proposes a macroscopic model where DNNs are analogized to spring-block systems. Each layer's feature learning process corresponds to the elongation represented by a spring, governed by elastic forces and asymmetric friction that models nonlinear dynamics.
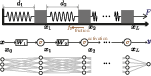
Figure 2: An illustration of the analogy between a spring--block chain and a deep neural network.
The analogy extends to include the noise as a factor that modifies the frictional dynamics, influencing how load (data separation) is balanced or imbalanced across the DNN.
Analytical Framework and Results
Load Curve Analysis
The load curve, defined as the layer-wise distribution of data separation improvements, offers insights into how well layers learn features. The paper demonstrates that the introduction of nonlinearity through friction results in varied equilibrium states of training—ranging from lazy (concave curves) to active training (convex curves).
When stochasticity is introduced, the effective friction is modulated, leading to a noise-induced rebalancing of the load curve. This counterintuitive result shows that, under high noise, shallow layers can be more effective at feature learning than deeper layers.
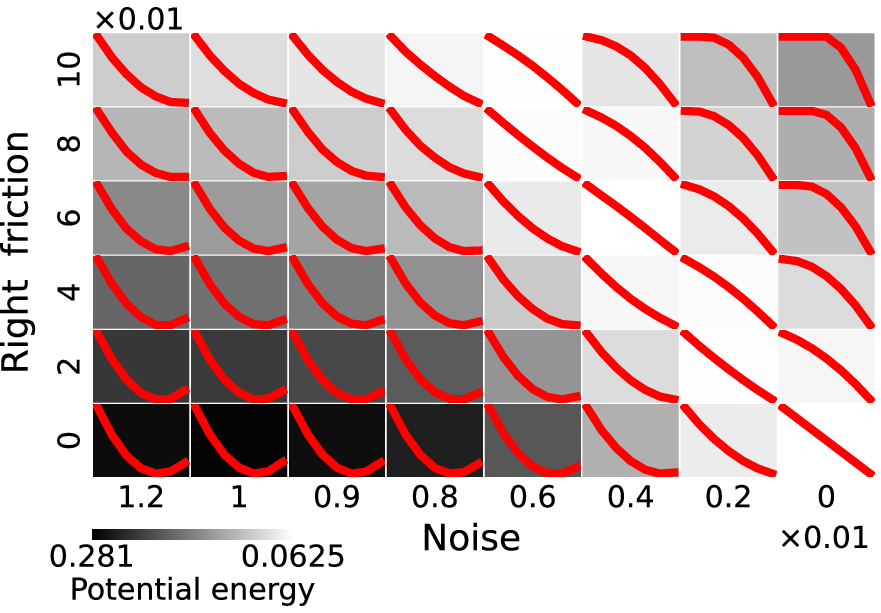
Figure 3: Phase diagram of the spring--block system for nonlinearity vs. noise level.
Implications for Generalization
A key finding is that linear load curves correlate with superior generalization performance. This relationship is traced back to the energy states of the spring-block model, where equiseparation minimizes potential energy. Consequently, the paper suggests that achieving a balanced load (linear curve) during training might be an indicator of optimal generalization capabilities.
Real-World Applications
The insights from this theoretical framework have practical implications: guiding hyperparameter tuning, adjusting training strategies (e.g., dropout rates), and understanding why certain DNN architectures generalize better. For instance, the balance between nonlinearity and noise highlighted in training regimens could inform strategies for robust model development.
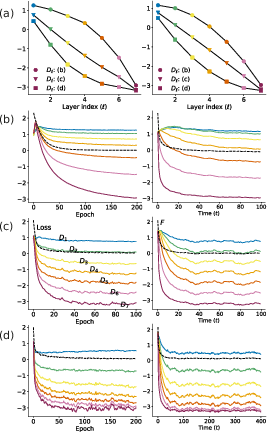
Figure 4: The load curves at convergence for DNN (left) and spring--block model (right), illustrating characteristic behaviors under different training conditions.
Conclusion
The spring-block model provides a valuable top-down perspective that complements traditional bottom-up approaches in understanding DNN training dynamics. By conceptualizing feature learning as a mechanical process, the paper offers a novel viewpoint to evaluate the balance between expressivity and generalization in neural networks. The model's predictive power regarding load distribution and generalization underscores its potential utility in improving DNN training protocols.
The research opens avenues for exploring similar phenomenological models in understanding other complex systems in machine learning and beyond, emphasizing the relevance of interdisciplinary insights in advancing AI theories.

