- The paper introduces Granite-20B-FunctionCalling, an LLM that enhances function calling abilities through a multi-task learning approach on granular tasks.
- It unifies training data in JSON format and tackles six specialized sub-tasks, achieving notable improvements in F1, LCS, and exact match scores.
- The model demonstrates strong generalizability and competitive benchmark performance, ranking fourth on the BFCL and excelling in function name detection.
Granite-20B-FunctionCalling: Multi-Task Learning for Enhanced Function Calling
This paper introduces Granite-20B-FunctionCalling, a new LLM designed to improve function calling abilities through multi-task learning on granular tasks (2407.00121). The model is instruction-tuned using a diverse set of datasets and tasks related to function calling, with a focus on granular sub-tasks such as function name detection, parameter-value pair detection, and function sequencing. The paper presents a comprehensive evaluation of Granite-20B-FunctionCalling against other open and proprietary models, demonstrating its strong performance and generalizability in out-of-domain settings.
Methodology and Training Data
The core contribution of this work is the multi-task training approach, which reuses data in different formats with distinct instructions for various function-calling related tasks. The authors identified six underlying sub-tasks for function calling, dividing them into two categories: High-Level Function Calling Tasks (Nested Function Calling, Function Chaining, Parallel Functions) and Low-Level Function Calling Tasks (Next-Best Function, Function Name Detection, Parameter-Value Pair Detection). A seventh task, Response Generation, was included to ensure the model could produce natural language responses.
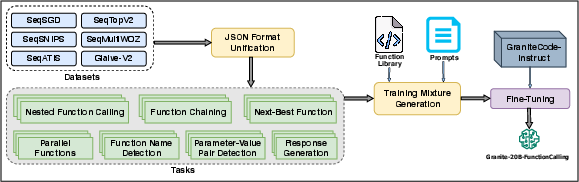
Figure 1: Step-by-step building process of Granite-20B-FunctionCalling.
The training data was unified into a consistent JSON format to represent APIs, tools, and functions. This unification process ensures that the model can effectively parse and utilize information from various sources. The model output representation of function calls follows a standardized JSON format:
1
2
3
|
{
"name": "<FUNCTION-NAME>", "arguments": {"<PARAMETER-1>": "VALUE-1", "<PARAMETER-2>": ...}
} |
Instruction Tuning and Training Details
Granite-20B-FunctionCalling is an instruct-tuned version of Granite-20B-Code-Instruct. The training data mixture consisted of 142K examples spanning all the defined tasks and datasets. The model was trained using QLoRA fine-tuning with a rank of 8, an alpha of 32, and a dropout of 0.1. The training used a learning rate of 5e-5 and the ApexFusedAdam optimizer with a linear learning rate scheduler. The training was conducted on a single node with 8 A100_80GB GPUs for a total of 3 epochs.
Experimental Results
The paper presents an extensive evaluation of Granite-20B-FunctionCalling, comparing it against other state-of-the-art function calling models on various datasets and a public leaderboard. The evaluation focuses on assessing the model's generalizability by using out-of-domain datasets.
Berkeley Function Calling Leaderboard (BFCL)
Granite-20B-FunctionCalling is ranked fourth in overall accuracy among the top 15 models on the BFCL, achieving the highest rank among models with open licenses. It achieves an AST Summary score of 84.11, an Execution Summary score of 86.50, and a Relevance score of 87.08. While tied with the Gorilla model, Granite-20B-FunctionCalling exhibits better generalization across different datasets.
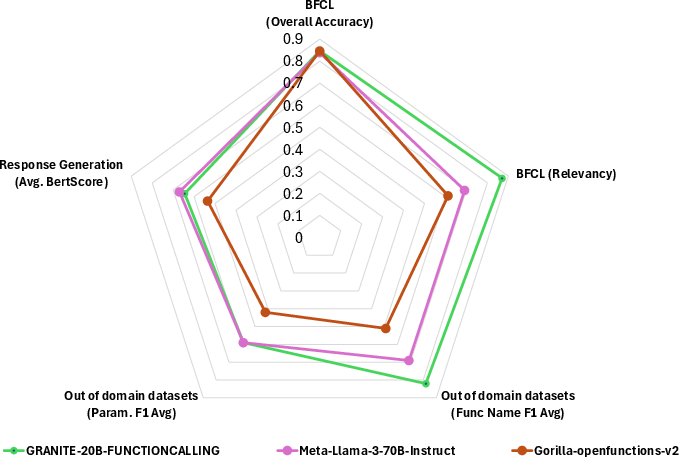
Figure 2: Evaluation of Granite-20B-FunctionCalling against the best open function calling models (according to BFCL).
Function Calling Academic Benchmarks
On ToolLLM datasets (G1, G2, and G3) and RestGPT, Granite-20B-FunctionCalling achieves the best performance in detecting function names, with an 8% improvement in F1 score compared to the next best model. The model also outperforms others in sequencing metrics, with a 7% improvement on LCS and an 11% improvement on Exact Match scores. On the API-Bank, ToolBench, and ToolAlpaca datasets, Granite-20B-FunctionCalling achieves an average F1 score of 0.87 for function name prediction.
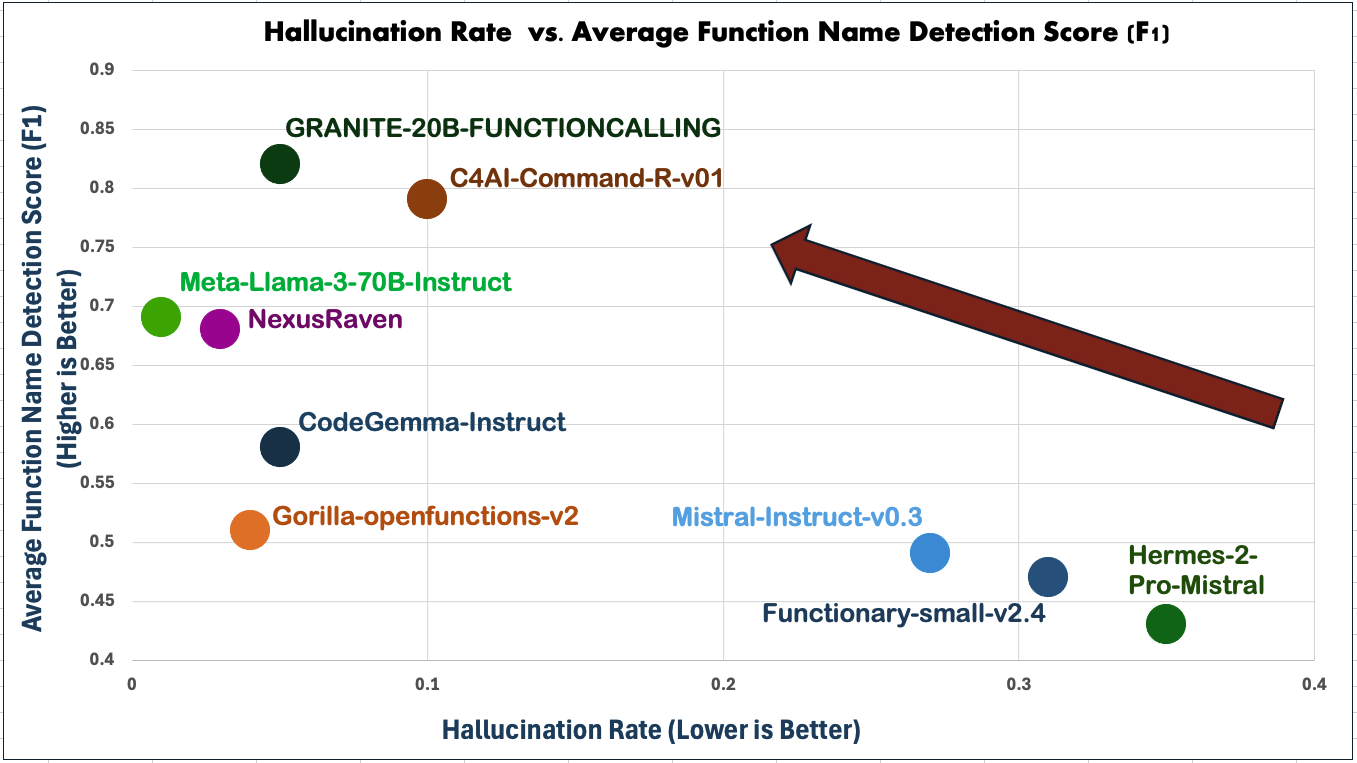
Figure 3: Performance vs. Hallucination rates for Out-of-Domain Function Calling.
Response Generation
In response generation, Granite-20B-FunctionCalling achieves strong results on the API-Bank dataset, with performance closely following Meta-Llama-3-70B-Instruct. The model achieves a BertScore of 0.68 and a Rouge-L score of 0.47, demonstrating its ability to generate natural language responses effectively.
Conclusion
The paper successfully introduces Granite-20B-FunctionCalling, a function calling model with strong performance and generalizability. The multi-task learning approach, combined with a focus on granular tasks, enables the model to achieve state-of-the-art results among open-source models on various benchmarks. The comprehensive evaluation demonstrates the effectiveness of the proposed approach and highlights the potential of Granite-20B-FunctionCalling for real-world applications. Future work could explore incorporating full function specifications without truncation to enhance performance further.