- The paper introduces DBGorilla, a benchmark for assessing function calling that translates natural language queries into structured database operations.
- It compares eight LLMs using Exact Match, AST alignment, and preference rankings across simple to complex query tasks.
- Ablation studies reveal that while the tool definition is robust, LLMs struggle with text property filters, highlighting areas for improvement.
Querying Databases with Function Calling
This paper (2502.00032) introduces DBGorilla, a benchmark for evaluating LLMs in querying databases using Function Calling. It presents a tool definition that unifies data access with search queries and result transformations, evaluating the effectiveness of this approach across multiple LLMs. The study also includes ablation studies to assess the impact of various experimental factors on performance.
DBGorilla Benchmark
The DBGorilla benchmark adapts the Gorilla LLM framework to create synthetic search database schemas and queries. It consists of five use cases, each with three related collections and four properties per collection. This benchmark tests the ability of LLMs to translate natural language commands into query APIs, covering search queries, property filters, aggregations, and grouping operations.
Experimental Setup
The experimental setup involves comparing eight LLMs from five model families, including Claude 3.5 Sonnet, GPT-4o, GPT-4o mini, Gemini 1.5 Pro, Gemini 2.0 Flash experimental, Command R+, Command R7B, and Llama 3.1 8B Instruct. The primary evaluation metric is Exact Match, which assesses if the predicted query from the LLM is identical to the ground truth query. The study also reports Abstract Syntax Tree (AST) alignment scores and LLM-as-Judge preference rankings.
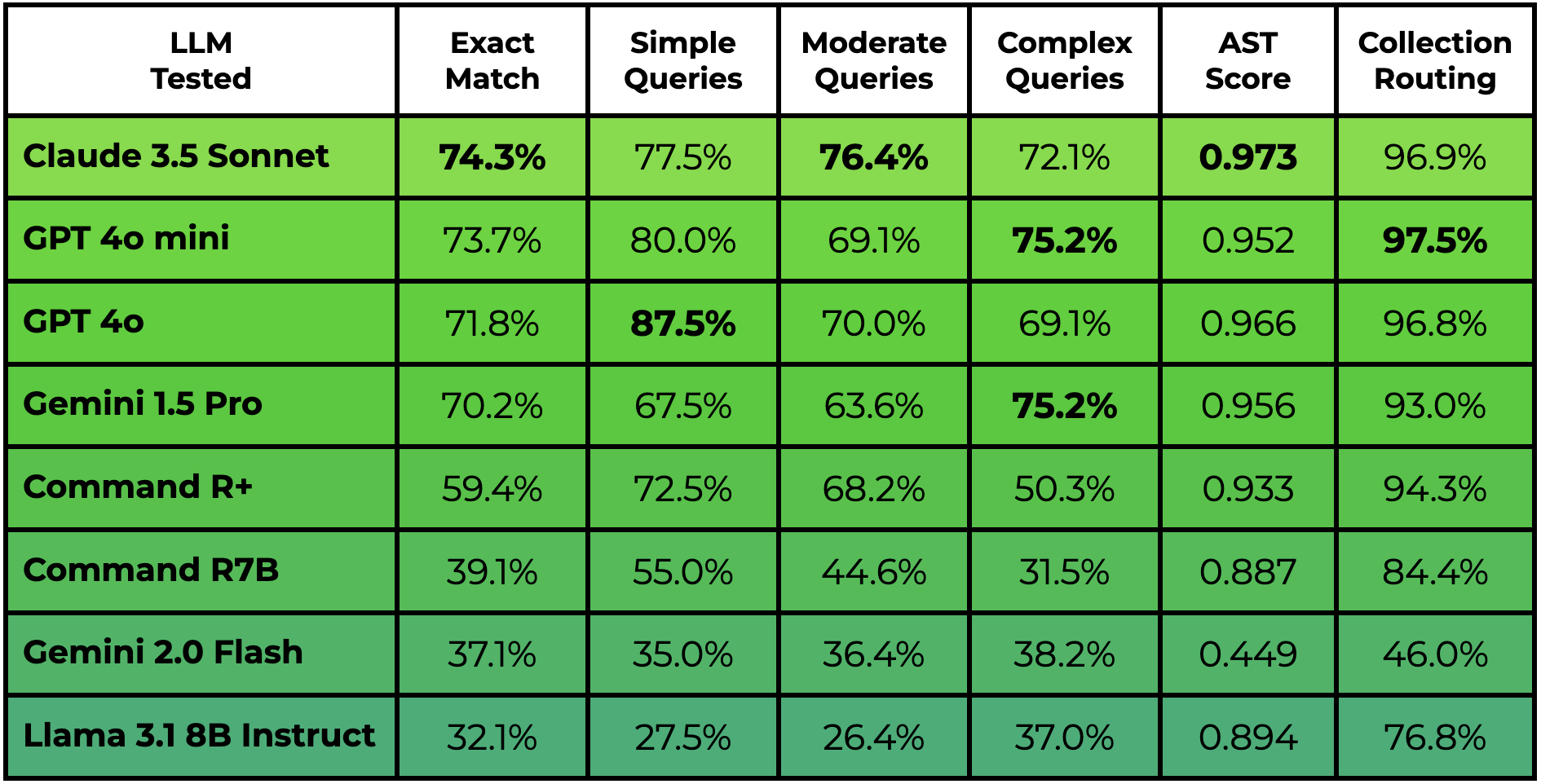
Figure 1: DBGorilla Leaderboard results (last updated January 1st, 2025). The Exact Match and AST Score columns report the respective averages across all tested queries. Query scores are further separated into categories of "Simple", "Moderate", and "Complex" according to how many arguments are used in the ground truth function call with 1, 2, and 3 or more, respectively. Collection routing reports the percentage the predicted query is routed to the correct database collection.
Results and Analysis
Claude 3.5 Sonnet achieves the highest performance with an Exact Match score of 74.3%, followed by GPT-4o mini at 73.7%, GPT-4o at 71.8%, and Gemini 1.5 Pro at 70.2%. The results are broken down by API component, revealing that LLMs are highly effective at utilizing operators on boolean-valued properties but struggle with text property filters. The study also visualizes performance across synthetic use cases, showing robust results with higher-performing models like GPT-4o, but significant performance variance with lower-performing models.
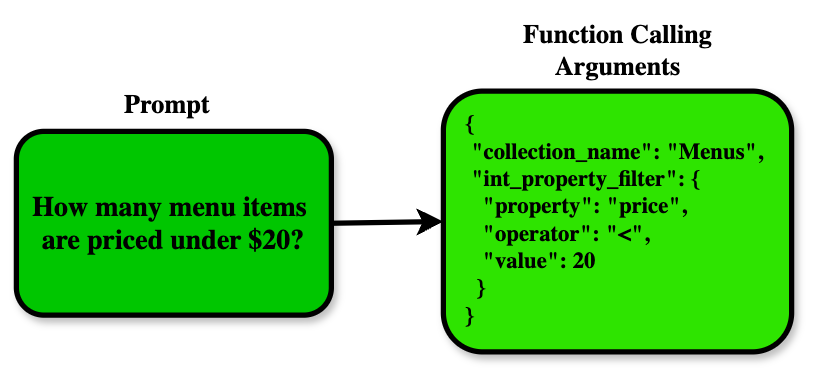
Figure 2: An illustration of a natural language command, How many menu items are priced under 20?, translated to Function Calling arguments for database querying.
Ablation Studies
The paper includes ablation studies exploring the impact of parallel tool calling, adding a rationale as an argument of the tool call, using a separate tool per database collection, and tool calling with structured outputs. The results show minimal performance variance across these ablation experiments with GPT-4o, indicating that the tool definition is robust across different configurations.
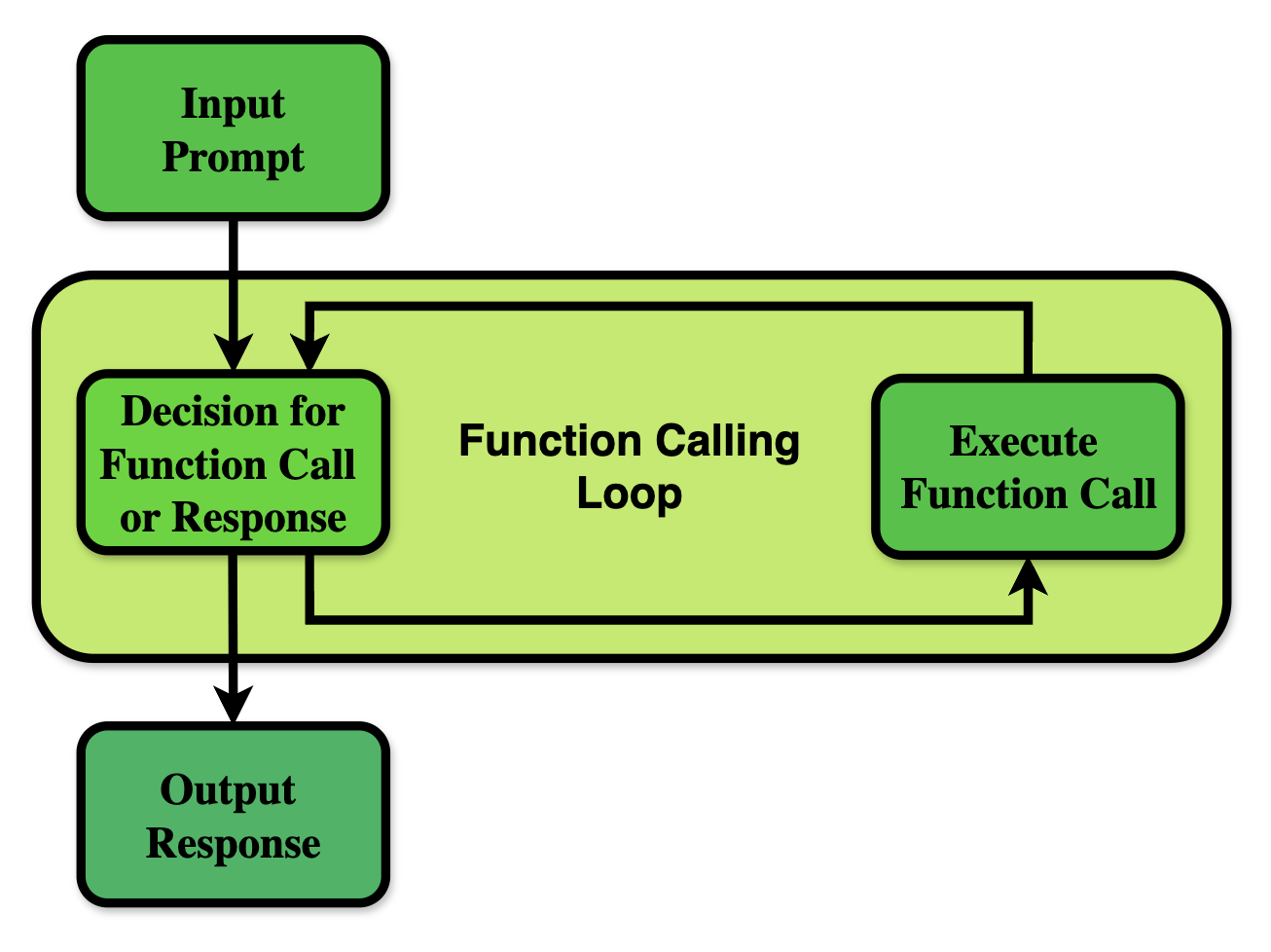
Figure 3: An illustration of the Function Calling loop. Beginning with the user's input prompt, the LLM then enters a loop where it can either choose to call one or multiple functions, or return a response to the user. If a function is called, the function is executed, the response is sent back to the LLM, and the Function Calling loop continues.
Implications and Future Directions
The findings suggest that Function Calling is an effective interface for enabling LLMs to query databases. The DBGorilla benchmark provides a valuable resource for future research in this area, with potential expansions to include more complex schemas, diverse property distributions, and explicit relationships between collections. Future work could also explore the integration of other tools, such as web search and data visualization, to create more sophisticated Compound AI Systems. Techniques such as Reflexion prompting [15] and DSPy Assertions could be used to refine queries based on validation or user feedback.
Conclusion
This paper demonstrates the effectiveness of Function Calling for enabling natural language database access. The DBGorilla benchmark and the comprehensive evaluation of multiple LLMs provide valuable insights into the capabilities and limitations of current models in translating natural language to structured database operations. The research contributes to the development of more intuitive and efficient interfaces for querying databases with LLMs.