- The paper presents a novel ensemble approach leveraging multimodal LLMs to predict fMRI responses to natural movie stimuli.
- The methodology integrates features from pre-trained models like V-JEPA2, Whisper, and Llama 3.2 through temporal projection to align with brain activity.
- The findings demonstrate that ensemble predictions boost generalization on out-of-distribution data, achieving a Pearson correlation of 0.2085.
Predicting Brain Responses To Natural Movies With Multimodal LLMs
Introduction
The paper "Predicting Brain Responses To Natural Movies With Multimodal LLMs" addresses the challenge of modeling brain activity in response to complex, multimodal stimuli using modern AI techniques. In particular, it presents a solution developed for the Algonauts 2025 Challenge aimed at enhancing our understanding of the human brain's response to naturalistic environments, such as those experienced while watching movies. The team from MedARC developed a sophisticated model that integrates features from leading multimodal models to predict neural activity captured via fMRI with considerable accuracy.
Methodology
The approach leverages state-of-the-art pre-trained models to extract multimodal features from video, audio, and textual stimuli, which are then used to predict brain responses. Key components of the methodology include:
- Multimodal Feature Extraction: Leveraging advanced models such as V-JEPA2 (video), Whisper (audio), Llama 3.2 (text), InternVL3, and Qwen2.5-Omni (vision-text-audio), rich feature representations are captured. These models provide a comprehensive set of features representing different dimensions of the stimuli (Figure 1).
(Figure 1)
Figure 1: Encoding model architecture depicting the integration of multimodal feature extraction from various pre-trained models for fMRI prediction.
- Temporal Alignment and Projection: Features extracted are linearly projected into a latent space and aligned temporally with fMRI time series data, allowing the model to map these representations onto brain activity regions.
- Ensemble Model Training: By training multiple variants of the model under varied settings and combining them into ensemble predictions, the approach improves generalization to novel stimuli, showing marked improvement over individual model performance.
Key Results
The model developed achieved a Pearson correlation of 0.2085 on a test set of out-of-distribution (OOD) movies, securing fourth place in the competition. An ensemble approach was integral in maximizing the model's predictive capability. Notably, the integration of diverse feature sets from different models significantly enhanced performance compared to using individual feature sets alone.
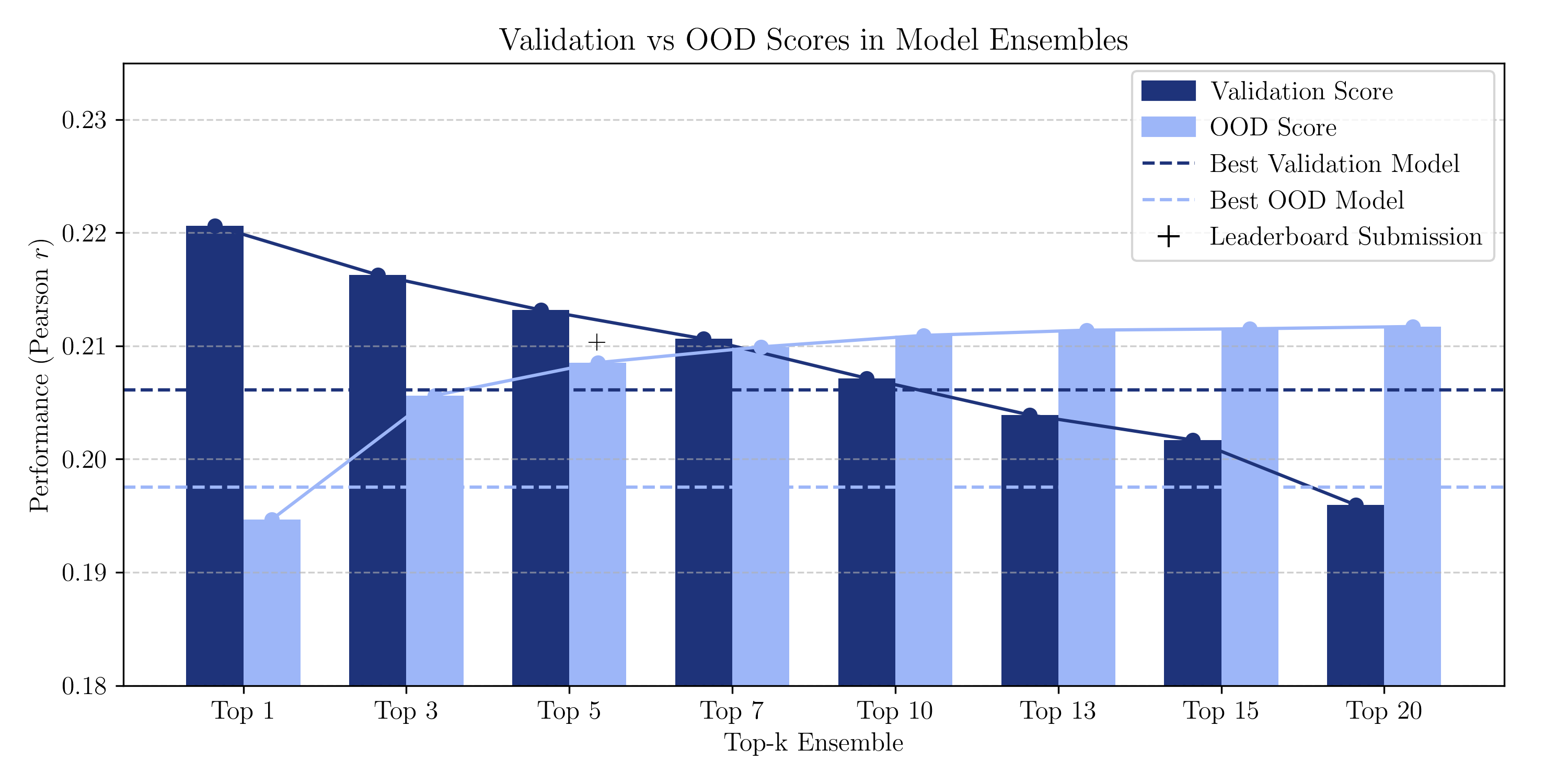
Figure 2: Comparison of ensemble performance across validation and out-of-distribution data, demonstrating the advantage of ensemble approaches over best single models.
The extensive ablation studies conducted reveal important insights into the model's performance:
- Convolution Kernel Size and Type: A kernel width of 45 TRs was found optimal for feature alignment, far exceeding typical hemodynamic response durations, suggesting benefits from extended temporal context (Table \ref{tab:kernel_size}).
- Embedding Dimension: While a dimension of 192 was optimal, satisfactory results were achievable with fewer dimensions, indicating the model's robustness in capturing essential stimulus-driven activities.
- Multi-Subject Training: Utilizing aligned fMRI responses from multiple subjects enhanced predictive performance, demonstrating shared neural encoding across individuals (Table \ref{tab:multi_sub}).
Ensemble Strategy and Generalization
The ensemble strategy involved selecting top-k models based on validation performance to predict OOD data. Scaling the ensemble size improved generalization, with a post-challenge analysis suggesting that larger ensembles could have improved competition standing.
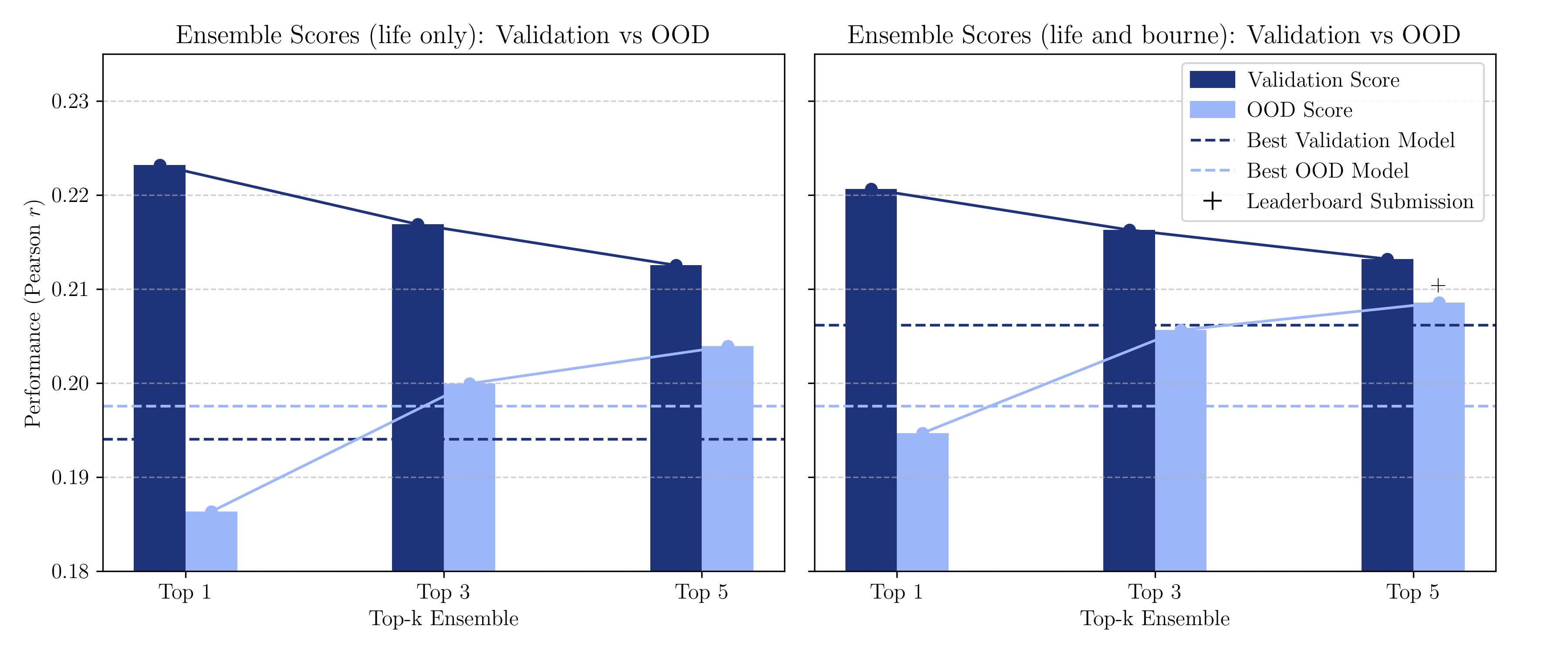
Figure 3: Impact of validation set selection on ensemble performance, illustrating divergent OOD generalization baselines for differing validation strategies.
Implications and Future Directions
The work demonstrates the efficacy of integrating multimodal LLMs for modeling complex, real-world stimuli and highlights the potential of ensemble learning to improve the robustness of neural prediction models. Future directions may explore feature optimization strategies tailored to specific movie characteristics without test data access, enhancing model adaptability further. The differential impact of validation sets on model generalization also suggests avenues for further investigation into optimal ensemble construction strategies.
Conclusion
This paper illustrates a sophisticated application of AI in cognitive neuroscience, showcasing how integrative models can predict neural responses to rich, dynamic stimuli with emergent accuracy. The findings pave the way for more nuanced and effective neuroscience models, blending machine learning advancements with neuroimaging insights to decode complex brain activity.

