- The paper finds that LLMs, when using zero-shot chain-of-thought, mimic human biases and struggle with invalid syllogisms.
- The study shows that in-context learning enhances performance via schema diversity, yet fails to fully overcome content bias.
- Supervised fine-tuning significantly improves reasoning accuracy by emphasizing deductive logic over lexical content.
A Systematic Analysis of LLMs as Soft Reasoners in Syllogistic Inferences
Introduction
The paper "A Systematic Analysis of LLMs as Soft Reasoners: The Case of Syllogistic Inferences" (2406.11341) critically examines the reasoning capabilities of LLMs within the context of syllogistic reasoning—a classical domain of deductive reasoning in logic and psychology. Despite LLMs' rapid advancements in natural language processing, their inherent biases, particularly content-related and multi-step reasoning difficulties, continue to challenge their reliability as reasoning agents. This research dissects how chain-of-thought reasoning, in-context learning (ICL), and supervised fine-tuning (SFT) can influence and potentially overcome these biases, with the ultimate aim of determining whether LLMs possess latent reasoning abilities.
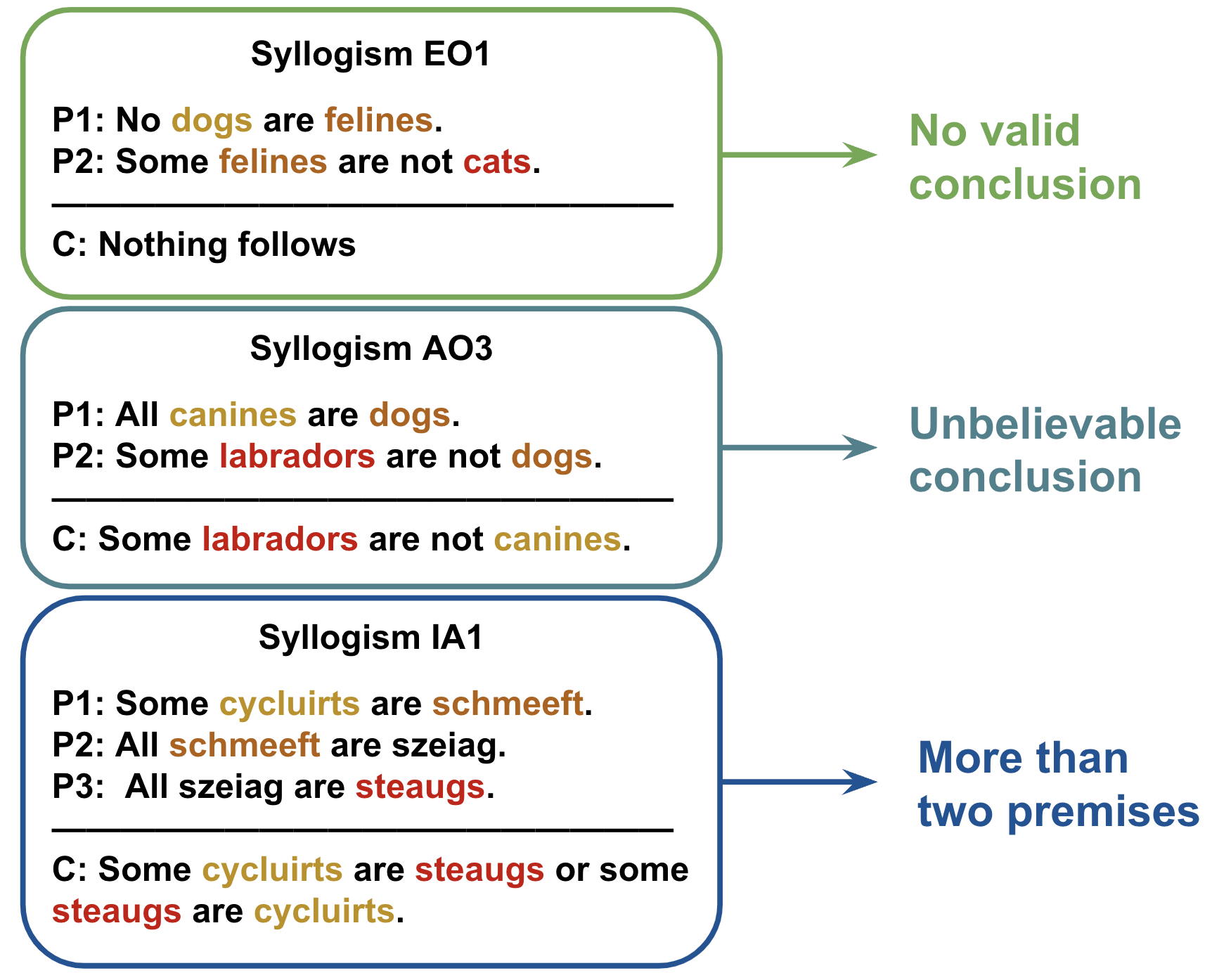
Figure 1: LLMs have difficulty with invalid inferences (Top); suffer from content effects (Middle); and struggle with longer chains of premises (Bottom).
Methodological Framework
The study employs a systematic experimental design involving LLMs such as Pythia and LLaMA models, with specific emphasis on validating syllogistic reasoning competencies. The methodology is structured around three core learning strategies:
- Zero-Shot Chain-of-Thought (ZS-CoT) Prompting: Examines models' performance without prior task examples, leveraging prompts to encourage deductive reasoning processes.
- In-Context Learning (ICL): Analyzes the impact of demonstrating diverse syllogistic examples in either in-context schema-aligned (ICLin) or schema-diverse (ICLout) settings.
- Supervised Fine-Tuning (SFT): Evaluates models fine-tuned on syllogistic tasks with pseudo-word data, focusing on consistency and transferability of learned reasoning skills.
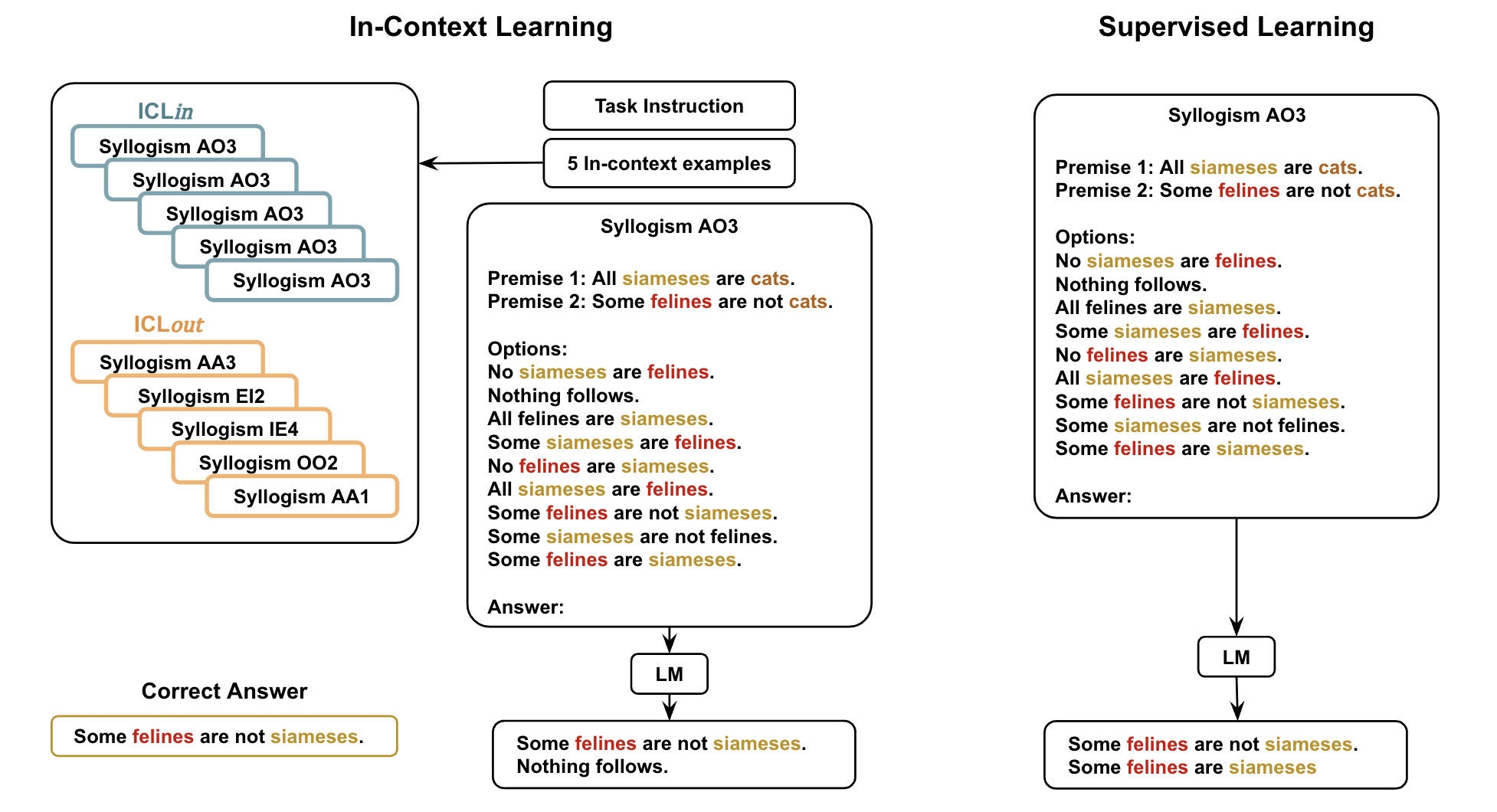
Figure 2: Multiple-choice Task The model is given the premises and nine possible conclusions, and has to generate the correct one(s). ICLin and ICLout show schema-based examples and diverse examples respectively.
Results and Analysis
The paper reveals significant disparities in reasoning performance among different training strategies. Key findings include:
Heuristic Analysis
The study examines heuristic models from cognitive science literature, such as the Atmosphere Theory, to interpret LLM behavior. The findings suggest that, in pre-trained settings, LLMs often default to mood-based heuristic reasoning, thereby explaining their hesitance to affirm "nothing follows." Supervised Fine-Tuning presents a promising route to overcome these heuristic biases.
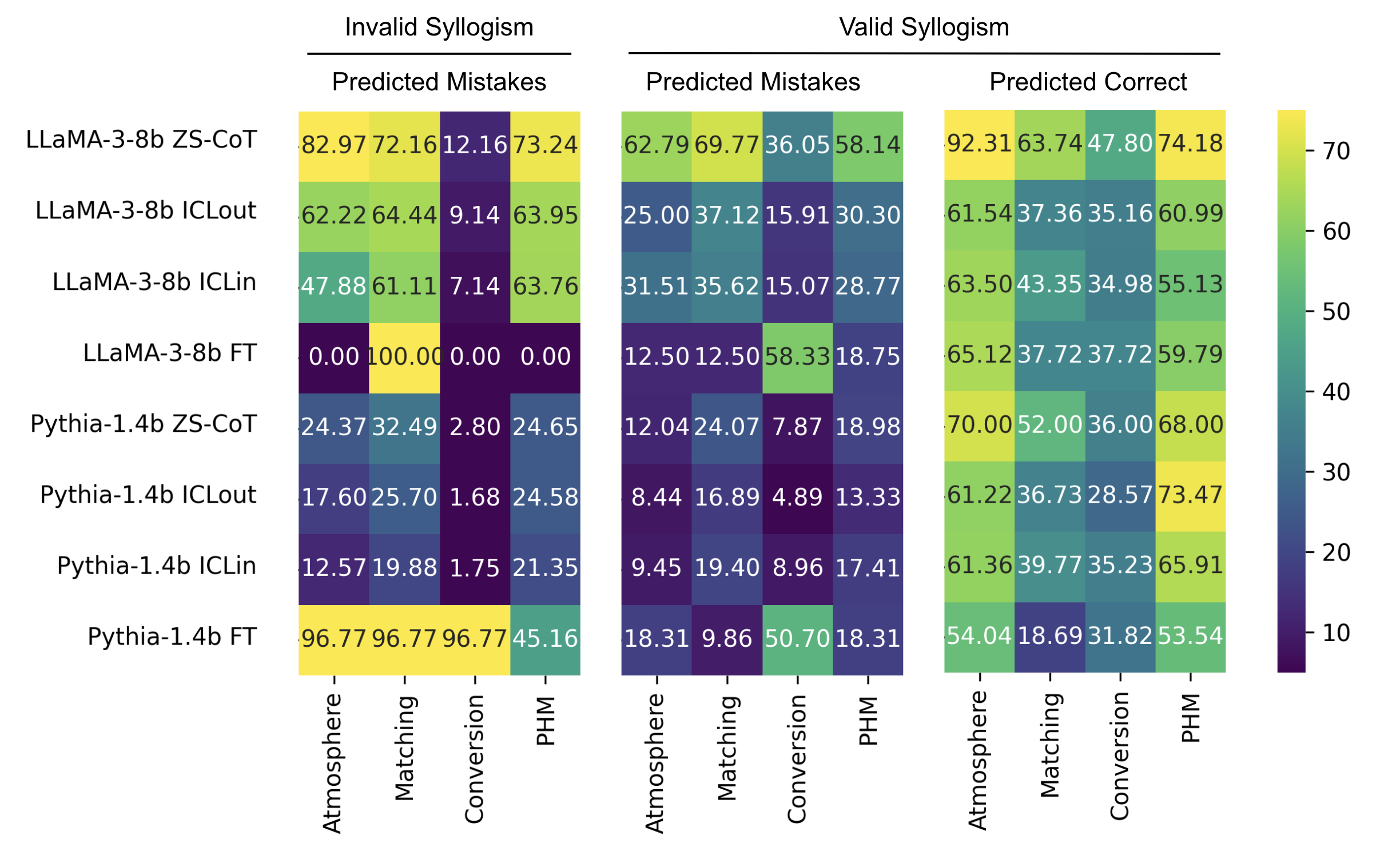
Figure 4: Heuristics predictions. Proportion of mistakes and correct conclusions generated by models that are predicted by heuristic theories.
Conclusion
This research delineates the nuances of LLMs' reasoning capabilities within syllogistic frameworks, identifying content bias and reasoning consistency as pivotal challenges. It underscores supervised fine-tuning as a potential pathway to enhance LLM reasoning fidelity by prioritizing form over content. Future studies are encouraged to expand the scope across more model families and incorporate adversarial testing to refine syllogistic reasoning metrics further. The implications of this work entail significant advancements not only in NLP but also in the broader design of AI systems with enhanced reasoning faculties.
