- The paper demonstrates that the advanced Transformer model significantly improves fraud detection with precision, recall, and F1-scores of nearly 0.998.
- It outlines a detailed methodology including data resampling, correlation analysis, and dimensionality reduction to mitigate class imbalance and enhance training.
- Results indicate that the Transformer model outperforms traditional approaches such as SVM, KNN, and logistic regression in identifying rare fraudulent transactions.
Introduction
The paper "Credit Card Fraud Detection Using Advanced Transformer Model" discusses the application of Transformer architectures for the detection of credit card fraud, a critical issue exacerbated by the rise in digital transactions. The focus lies on addressing the challenge posed by the rarity of fraudulent transactions amidst a massive volume of data and exploring the efficacy of Transformer-based models in recognizing fraudulent patterns. This essay explores the methodologies adopted by the authors, evaluates the results achieved, and reflects on the broader implications of this study within the field of financial fraud detection.
Methodology
The authors employ a dataset comprising 284,804 European transactions, wherein only 0.172% represent fraud. A key methodological component involves preprocessing this data to counterbalance its inherent imbalance and improve model training efficacy. The study applies resampling techniques to generate a balanced distribution of transaction classes, effectively enhancing model reliability.
Data Processing
A multiple-step data processing approach ensures robust input data. The process begins with the creation of an evenly distributed dataset (Figure 1), ameliorated by random sampling and integration, followed by a shuffle for randomness assurance.
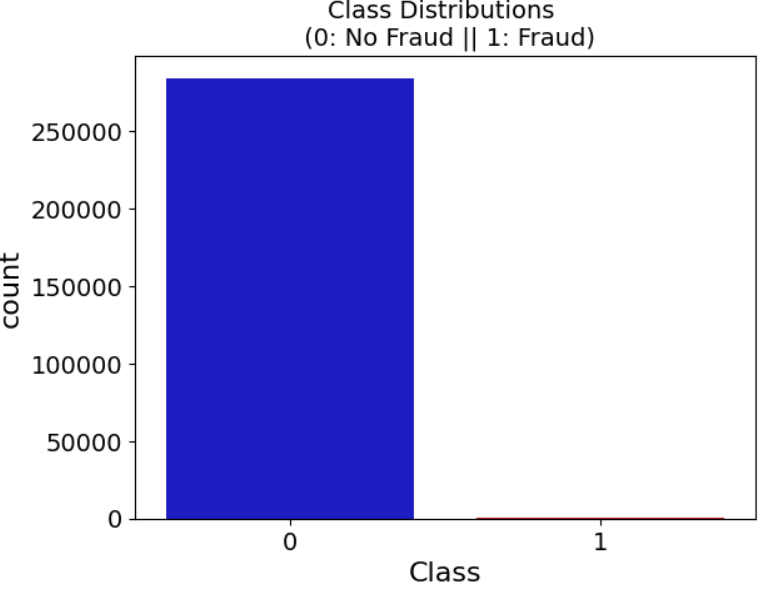
Figure 1: Transaction Class Distribution showing data imbalance.
A comprehensive feature correlation analysis between the original imbalanced and newly subsampled data highlights substantial performance improvements, as presented in Figures 3 and 4.
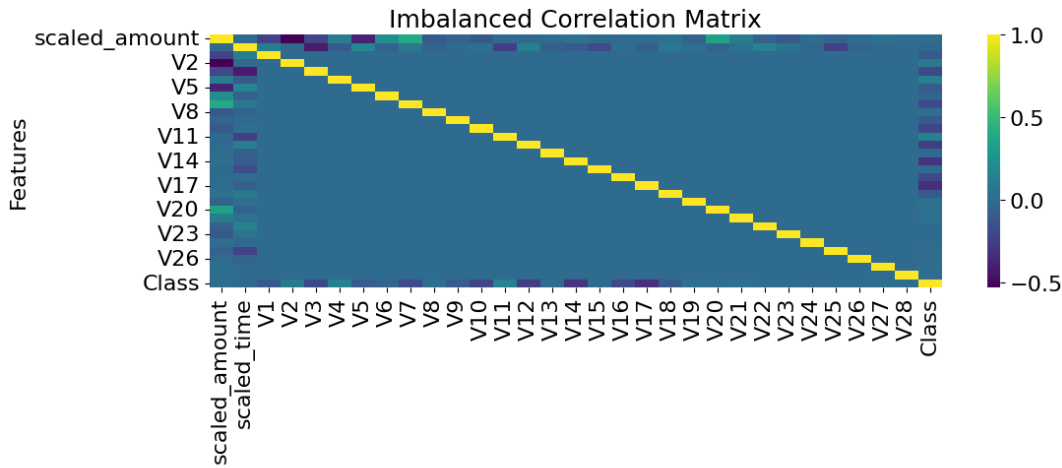
Figure 2: Imbalanced Correlation matrix.
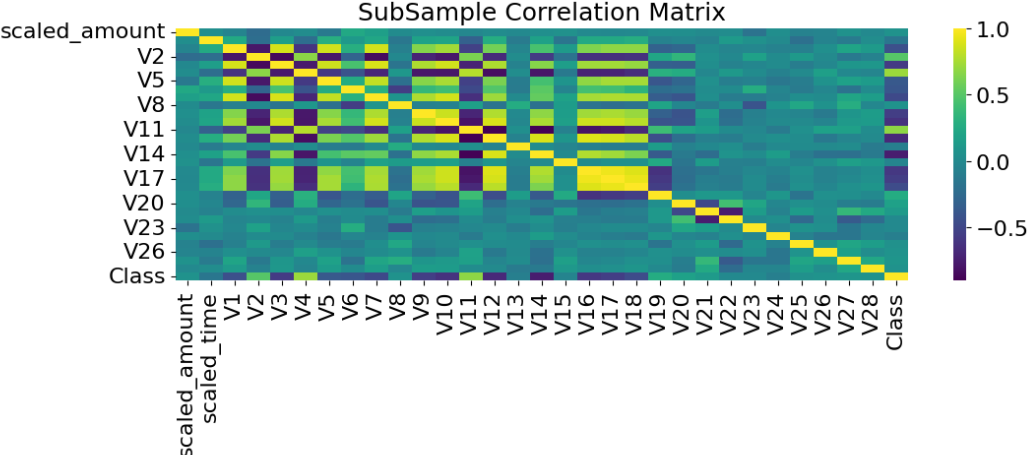
Figure 3: Subsample correlation matrix.
Dimensionality Reduction
To facilitate data visualization, the study employs T-SNE, PCA, and Truncated SVD (Figures 5-7). T-SNE proves highly efficacious, especially for revealing complex data structure that PCA and SVD may not capture, thus offering more nuanced clustering insights.
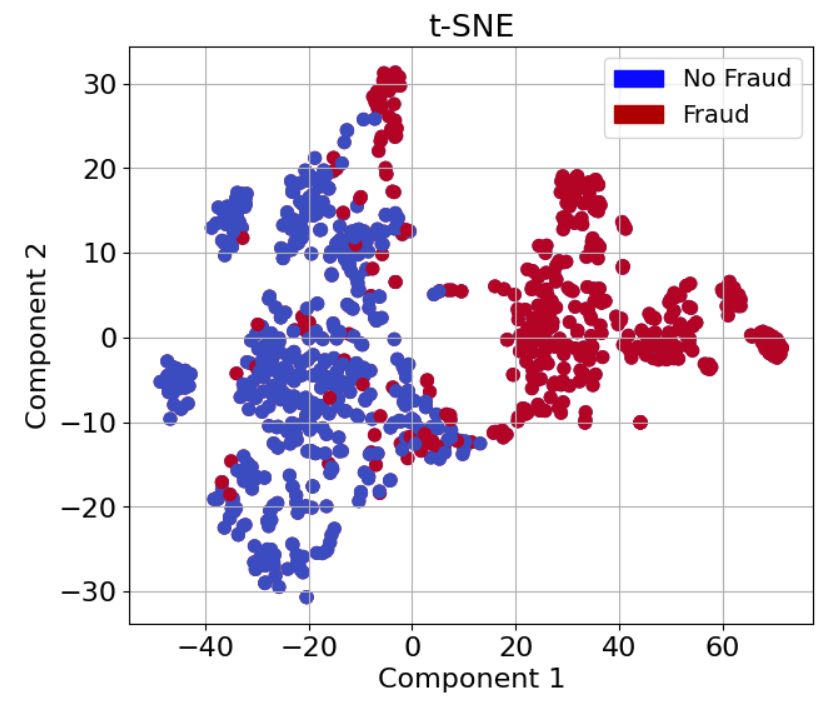
Figure 4 T-SNE showing data clustering effectiveness.
The centerpiece of the methodology is the advanced Transformer model employed for fraud detection, leveraging a combination of Self-Attention Mechanisms and Feed-Forward Neural Networks (Figure 5).
Self-Attention Mechanism
The Self-Attention Mechanism computes attention weights for varied positions within the sequence, retaining positional dependencies effectively. The multi-head variant enhances this through distinct projections and parallel processing, enabling the model to capture nuanced context across the input data.
Z=AV
Encoder Structure
The Encoder layer adopts a combination of self-attention and subsequent normalization, along with feedforward passes and residual connections, to optimize classification outcomes. These steps collectively underlie the Transformer's high competence in processing and identifying complex fraudulent versus non-fraudulent transactions with precision.
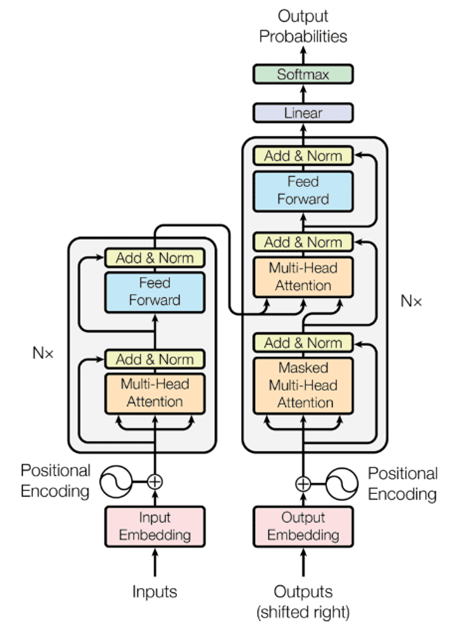
Figure 5: Transformer Structure employed in the study.
Evaluation
The authors deploy Precision, Recall, and F1-score as primary performance metrics to evaluate the efficiency of their model, establishing a benchmark for comparison against traditional approaches such as SVM, KNN, and logistic regression.
Results
Findings indicate that the Transformer model surpasses conventional models, reflecting a precision, recall, and F1-score nearing 0.998. Such performance metrics validate the model's adeptness in fraud detection, illustrating both higher precision in fraud identification and maintaining low false-positive rates.
| Model |
Precision |
Recall |
F1-score |
| KNN |
0.93 |
0.92 |
0.92 |
| SVM |
0.93 |
0.93 |
0.93 |
| Decision Tree |
0.91 |
0.90 |
0.89 |
| Logistic Regression |
0.96 |
0.96 |
0.96 |
| Neural Network |
0.975 |
0.999 |
0.988 |
| Transformer |
0.998 |
0.998 |
0.998 |
Conclusion
The study delineates the robust application of Transformer architectures in the sensitive domain of fraud detection, marking a significant step forward in utilizing NLP-oriented models for financial transaction analysis. The research substantiates that Transformers, beyond their linguistic fortes, exhibit formidable potential in classification tasks within niche sectors like fraud detection. Future research may likely focus on further refining these models and amplifying their efficiency to encompass even larger and more complex datasets, thereby enhancing the security measures against financial fraud globally.