- The paper introduces a unified benchmark that rigorously evaluates spatial reasoning and navigation in 3D-LLMs using diverse multi-modal tasks.
- The methodology leverages an automated instruction-tuning pipeline, generating over 0.23 million samples across 10 varied tasks.
- Experimental results reveal up to a 20% accuracy improvement in classification and navigation, validating the benchmark’s efficiency.
3DBench: A Comprehensive and Scalable Benchmark for 3D-LLMs and Instruction-Tuning
Introduction and Motivation
Multi-modal LLMs (MLLMs) incorporating 3D point cloud understanding are rapidly advancing, yet their evaluation is hampered by fragmented benchmarks and deficient datasets focused largely on classification and captioning. The lack of comprehensive assessment in spatial understanding and reasoning limits progress and obfuscates the true capabilities of 3D-LLMs. Addressing these deficiencies, "3DBench: A Scalable 3D Benchmark and Instruction-Tuning Dataset" (2404.14678) proposes a unified, extensible benchmark and a substantial instruction-tuning dataset, designed to rigorously quantify the spatial, logical, and expressive capabilities of modern and future 3D-LLMs.
3DBench Benchmark: Scope and Novelty
3DBench differentiates itself through multifaceted coverage of the 3D-LLM evaluation landscape. The benchmark comprises ten diverse multi-modal tasks at both object and scene levels, including both perception and planning. These tasks span traditional (classification, detection, captioning) and novel axes (room detection, multi-instance reasoning, spatial navigation), categorically distributed across three competency levels to mirror human cognitive hierarchies in the 3D domain.
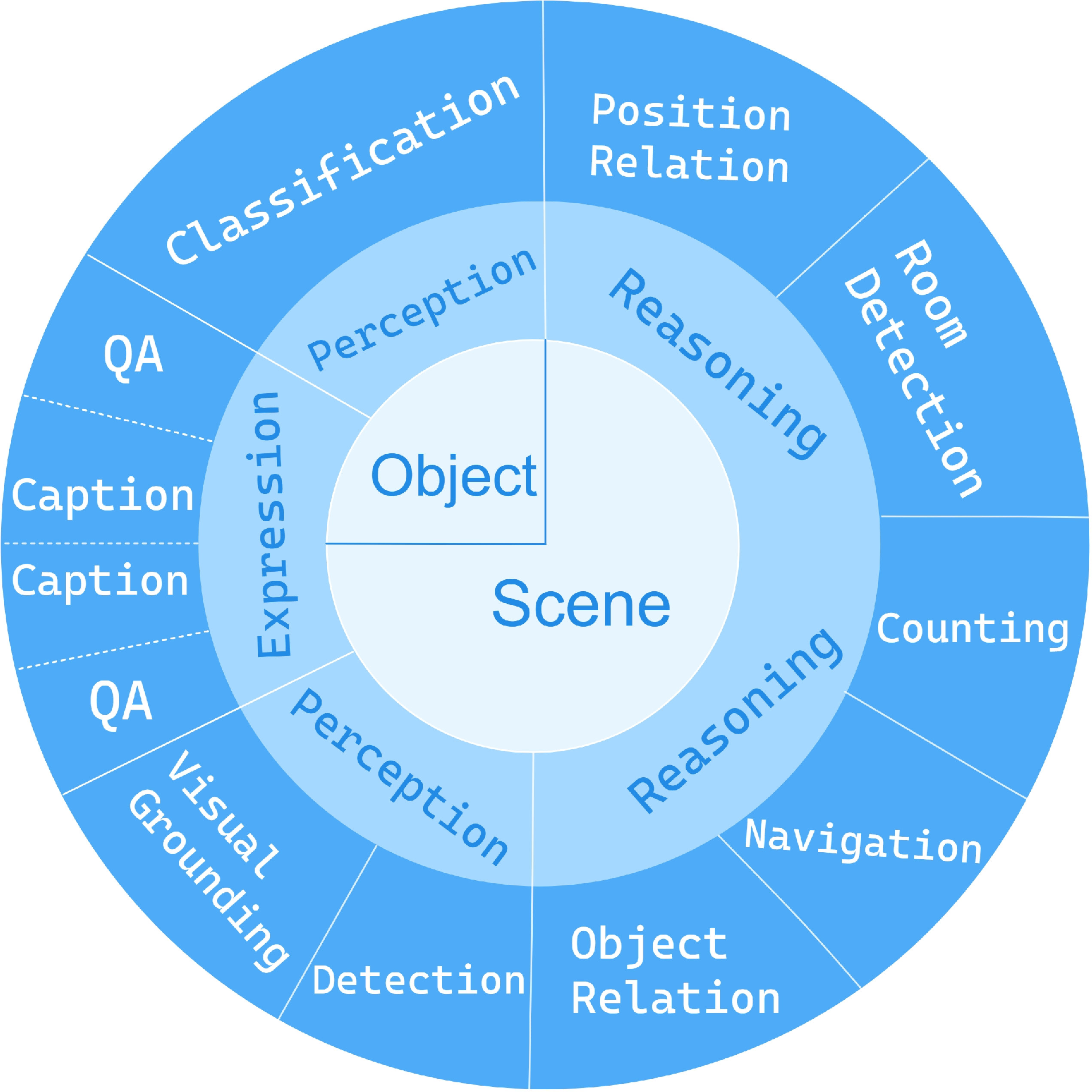
Figure 1: 3DBench task taxonomy, mapping ten core tasks into three cognitive and competency levels for holistic benchmarking.
The benchmark introduces a novel evaluation protocol using three metric families:
- GPT-based scoring, leveraging LLMs (e.g., ChatGPT) as evaluators for textual outputs (captions, QAs), incorporating ground-truth scene and object information to minimize hallucinations and scoring bias.
- Localization metrics, introducing the
in box and more flexible around box metrics for detection and visual grounding, as well as an innovative path loss metric for navigation, measuring the accumulated trajectory distance from predictions to ground truth.
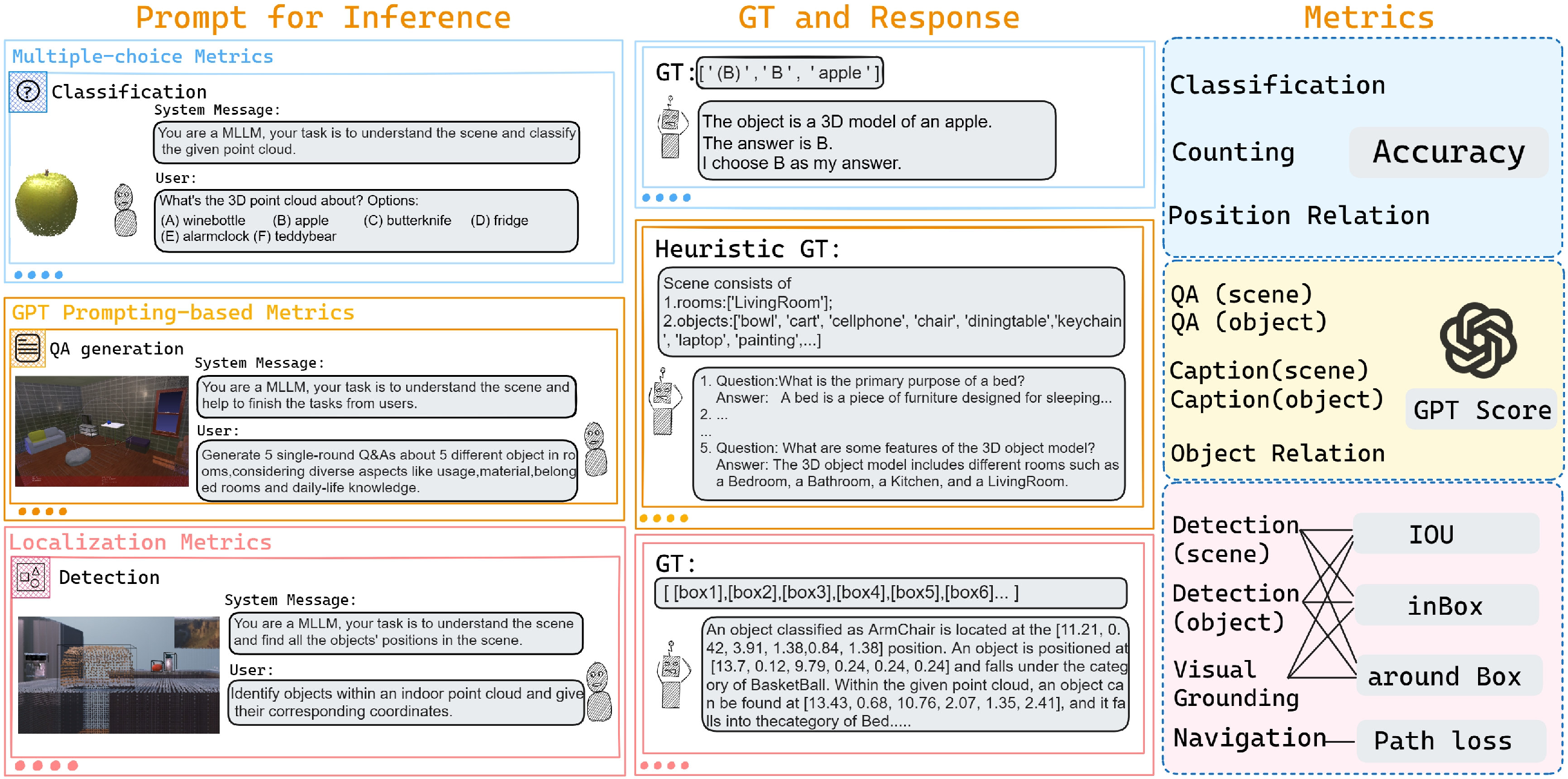
Figure 2: Overview of the 3DBench benchmark: ten multi-modal tasks, comprehensive metrics (accuracy, IOU, GPT score, path loss), and hierarchical evaluation criteria.
This rigorous protocol enables systematic analysis of 3D-LLMs across both recognition and spatial-reasoning capabilities—the latter largely ignored in predecessors focused on single-object or 2D analogs.
Automatic Large-Scale Instruction-Tuning Dataset Construction
The construction pipeline automates the collection of instruction-tuning data by leveraging the Procthor and AI2-THOR frameworks for procedural generation and point cloud capture of both everyday objects (over 34,000) and randomized indoor scenes (over 30,000). Metadata extraction, instance segmentation, and depth/color-based 3D reconstruction enable full coverage of scene and object configurations.
Subsequently, ground-truth is used to prompt LLMs (GPT-3.5/4) for generating diverse task-specific dialogues and QA pairs. This yields a dataset of over 0.23 million instruction-tuning samples, covering all ten tasks with high granularity. Dialogue templates are varied for each task to enhance response diversity and training utility.
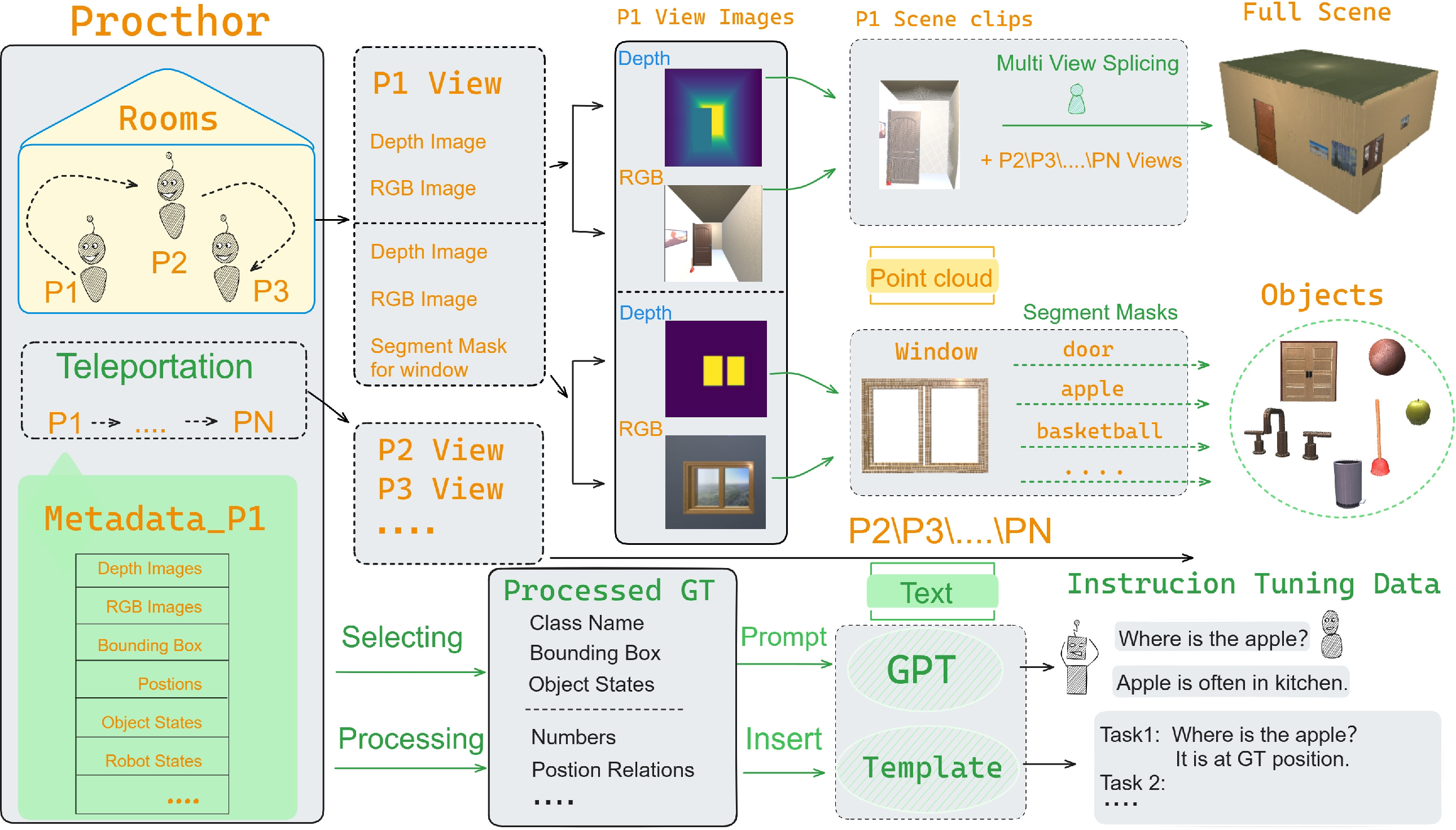
Figure 3: Dataset generation pipeline for 3DBench: from scene object data capture to instruction-tuned dialogue assembly, bypassing manual bottlenecks and leakage from existing datasets.
Experimental Evaluation and Key Results
The authors conduct an extensive experimental campaign to corroborate the representativeness and utility of 3DBench. Five experimental setups are constructed, including cross-benchmark validation (with LAMM as baseline), dataset scale variation, re-training and zero-shot evaluation, and model family comparison.
Zero-shot Evaluation: State-of-the-art 3D-LLMs (LAMM, PointLLM, Point-LLM) are evaluated on all ten 3DBench tasks.
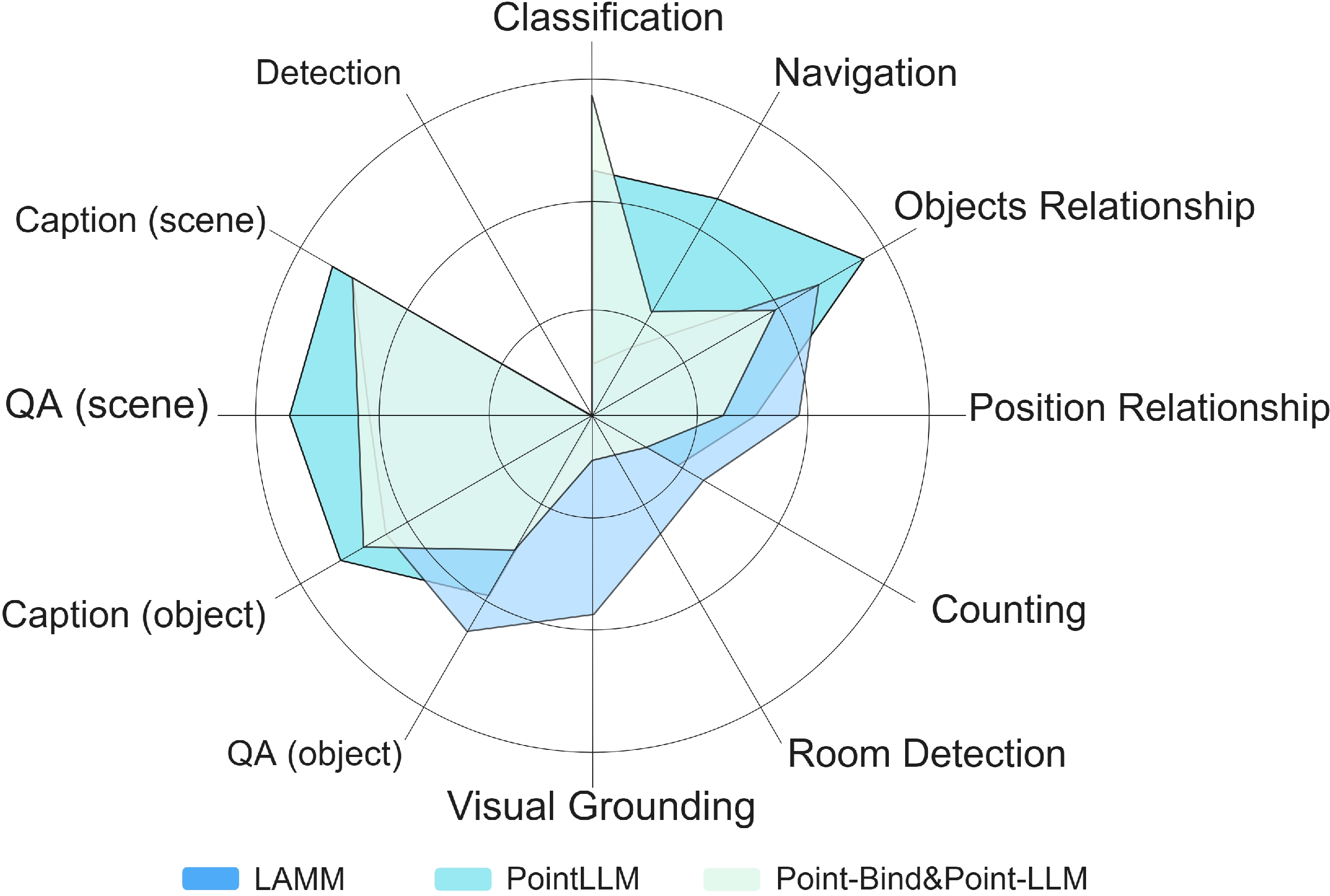
Figure 4: Zero-shot performance of top-tier 3D-LLMs across all 3DBench tasks, highlighting substantial headroom in complex spatial reasoning and navigation benchmarks.
Cross-Set Validation: Models trained on 3DBench outperform those trained on ShapeNet/3RScan in zero-shot settings, particularly in detection, localization, and VQA, confirming the added value and challenge density of 3DBench data.
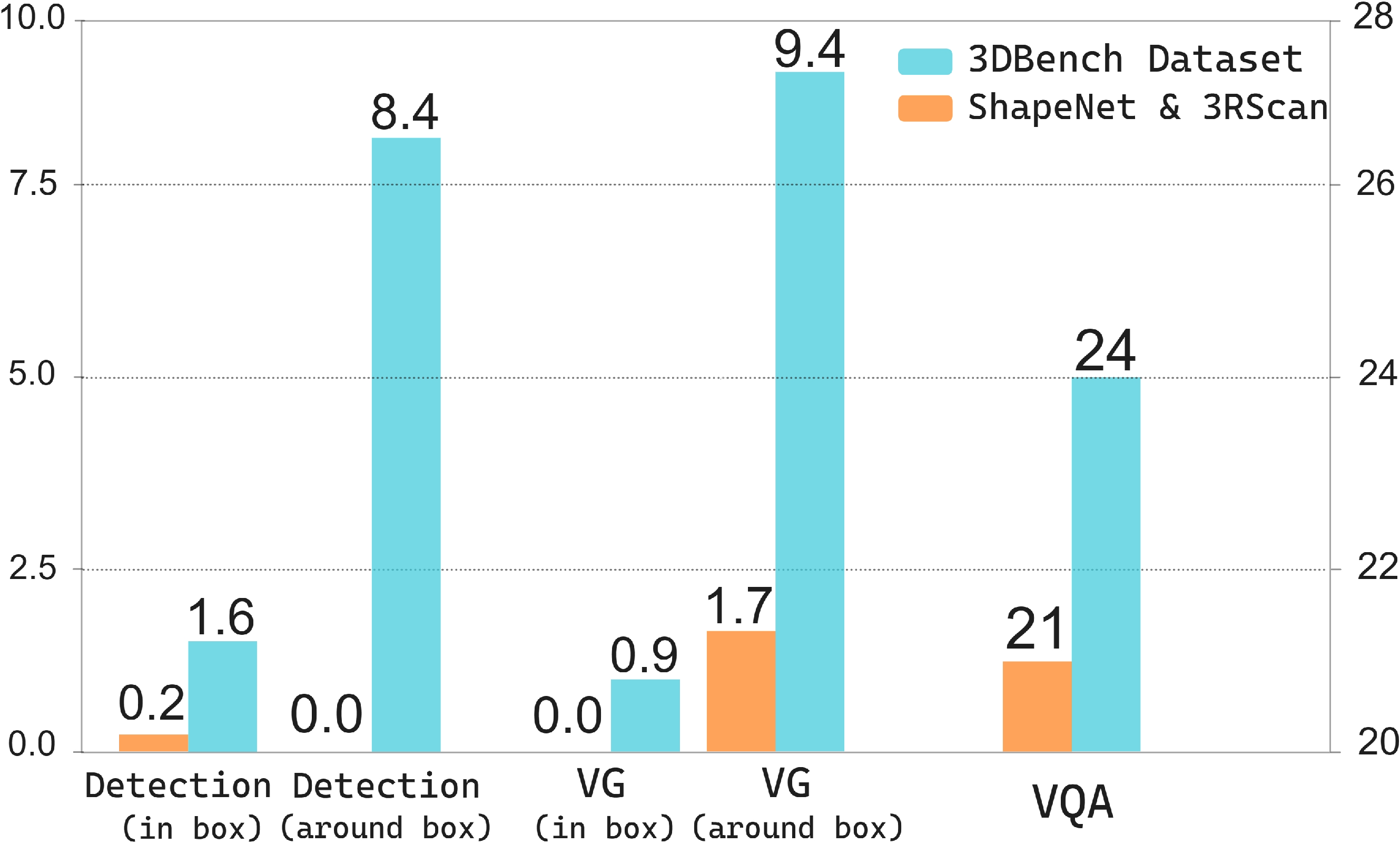
Figure 5: Comparative cross-set validation for LAMM on public vs. 3DBench datasets—clear advantage for 3DBench across spatial tasks.
Training Set Scaling: Performance improves with larger training sets up to ~20k samples, after which it plateaus, especially for simple encoders. This evidences data-driven saturation limits of current model architectures.
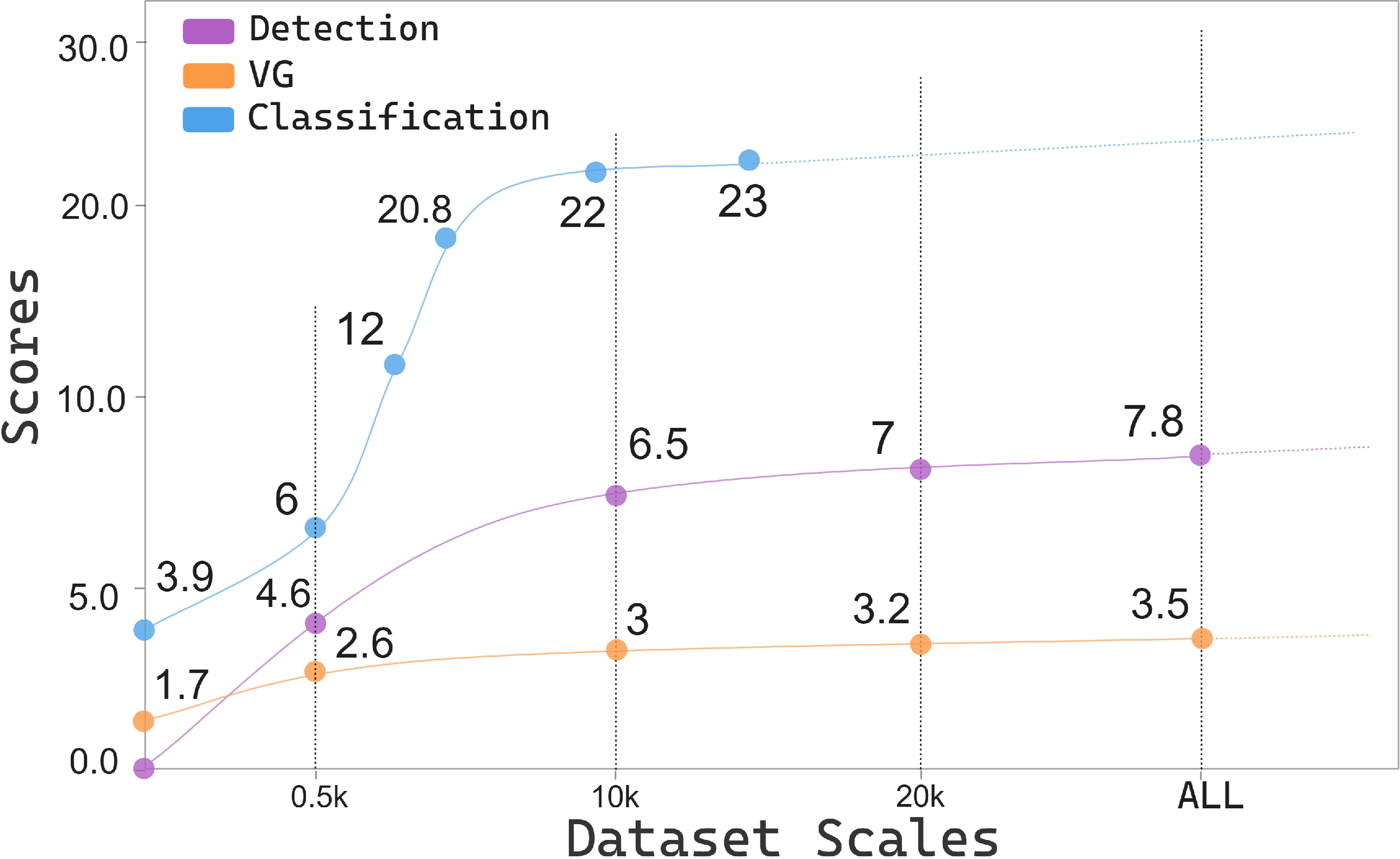
Figure 6: Scaling law for 3D-LLM performance relative to training sample count—diminishing returns beyond critical mass emphasize modeling bottlenecks.
Re-training on 3DBench yields up to 20% accuracy improvement in classification and counting, along with significant gains in navigation (from 6.2% to 24.4%). However, tasks dependent on nuanced text generation and fine-grained relational understanding (e.g., position relationship) show mixed or even slightly decreased performance, attributed in part to disparities between LLM (GPT-3.5/4) generations and evaluation regimes.
Analytical Observations and Model Limitations
Several critical observations emerge:
- Feature Bottlenecks: Incorporating color in point cloud encoders (as in PointLLM, Point-LLM) yields measurable upticks in zero-shot classifier accuracy, while scene-level perception and room detection remain challenging, attributed to inefficient feature aggregation for large-scale scenes.
- Spatial Reasoning Constraints: All models show weak spatial relationship understanding in the absence of substantial scene-level training data, but performance aligns closer to ground truth with dataset expansion and novel evaluation metrics.
- Template Effects: Overly deterministic or brief answer templates can yield impoverished outputs/failure cases in non-generative tasks, stressing the necessity for response diversity and rich template design in pre-training data.
Implications and Future Directions
Practically, 3DBench—and its associated instruction-tuning pipeline—serves as a robust diagnostic for MLLM deficiencies in 3D perception, spatial reasoning, and planning tasks. The results underline that merely scaling data is not sufficient; architectural and methodological innovation in feature extraction, spatial representation, and possibly dedicated modules for navigation and multi-object reasoning are necessary to progress toward genuinely general-purpose 3D-LLMs.
Theoretically, the findings emphasize the limitations of current transformer-based fusion for high-dimensional 3D data, especially when paired with complex multi-modal and logical reasoning pipelines. The growing gap in scene-level spatial understanding versus object-level recognition indicates rich research potential in novel data representations (e.g., graph-based, set-based, or spatial-topological explicit encoders) and hybrid approaches uniting vision and geometric reasoning.
Conclusion
"3DBench: A Scalable 3D Benchmark and Instruction-Tuning Dataset" introduces a crucial infrastructure component for the 3D-LLM community, combining broad task coverage, rigorous evaluation, and an automated, extensible instruction-tuning dataset. Its utility in exposing model weaknesses—particularly in spatial reasoning and planning—establishes a foundation for the next generation of 3D multi-modal models and evaluation standards. Adoption of 3DBench is poised to enhance both empirical rigor and theoretical insight in the design of future large-scale 3D-LLMs.