- The paper demonstrates that GPT-4 models significantly enhance clinical trial protocol authoring by producing human-like, contextually accurate texts.
- It employs meticulous data preprocessing and prompt engineering on drug and study metadata to optimize text generation.
- The study highlights that while GPT-3.5 is more cost-efficient, GPT-4 variants deliver superior language performance essential for clinical research.
Clinical Trials Protocol Authoring using LLMs
Introduction
The paper "Clinical Trials Protocol Authoring using LLMs" (2404.05044) investigates the potential of LLMs, specifically GPT-4 and its variants, to automate the generation of clinical trial protocols. This approach aims to enhance the efficiency and accuracy of protocol development by leveraging generative AI. The methodology includes data preprocessing, prompt engineering, and model evaluation, demonstrating that LLMs can significantly improve the speed and quality of protocol authoring while reducing costs.
Data Sources and Processing
The paper begins by collecting comprehensive drug and paper level metadata from reputable sources like CT.Gov and TrialTrove portals. The metadata included crucial details such as therapeutic applications, clinical and scientific details, and trial information. This data was meticulously processed to ensure clarity and relevance in building robust AI models.
Data Preparation
- Drug Level Metadata: Included information on development status, therapeutic applications, and company profiles, enabling the model to generate contextually accurate protocol sections.
- Study Level Metadata: Enriched the dataset with trial information, sponsorship details, patient demographics, and paper endpoints.
These datasets provided the necessary context for LLMs to understand nuance in protocol sections.
Model Development and Evaluation
The research outlines two primary approaches:
LLM Model Training
Initially, models like T5 Small, T5 Large, and BioBart were trained. However, these models struggled with generating long-form texts due to their design focus on classification tasks rather than text generation, leading to concise outputs that could not fulfill the project's needs.
GPT Models and Prompt Engineering
By shifting focus to OpenAI's GPT models—specifically, GPT-3.5 and GPT-4—the paper effectively utilizes prompt engineering. This approach included providing structured examples, enabling more accurate and contextually rich output for protocol sections. The paper demonstrated that GPT models are particularly suited for generating conversational and long-format text, making them ideal for protocol authoring.
Results
The paper emphasizes the marked improvement in text generation quality, with GPT-4 models showing exceptional capability in producing protocol sections that closely resemble human-authored documents (Figure 1).
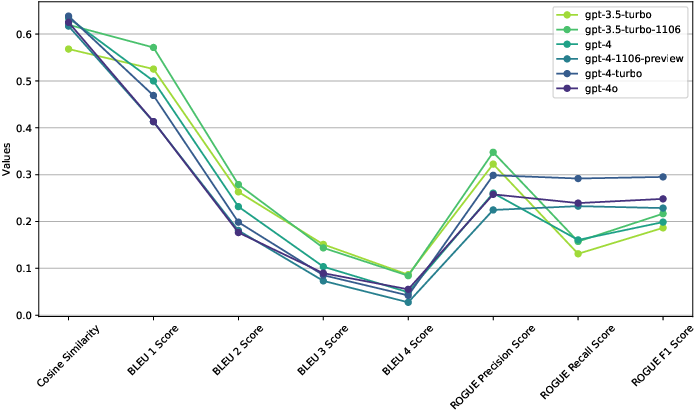
Figure 1: Aggregated (across all number of examples) metrics across all models.
GPT-4 outperformed other models in generating accurate and coherent protocol content, significantly aligning with the required style and format (Figure 2, Figure 3).
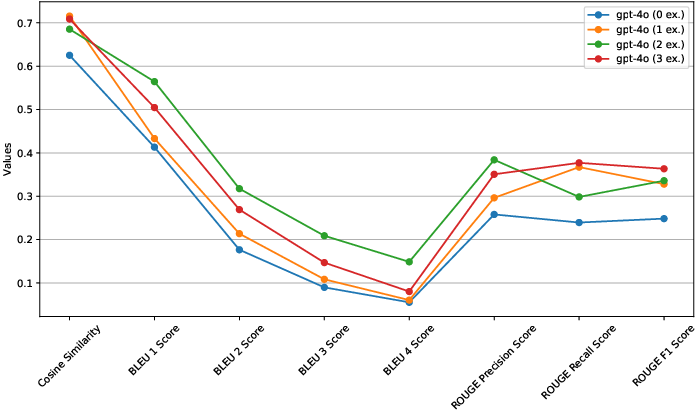
Figure 2: Metric comparison for GPT-4o model with varying number of examples (i.e. 0, 1, 2, 3).
Evaluation Metrics
The paper applied various metrics, including Cosine Similarity, BLEU scores, and ROUGE scores, to evaluate the models' performance:
- Cosine Similarity: Measured semantic closeness between generated and reference texts.
- BLEU Scores: Evaluated n-gram overlap for textual accuracy.
- ROUGE Scores: Assessed the precision and recall for summarization quality.
Advanced models demonstrated high precision, recall, and coherence, notably when provided with examples, optimizing the generation of complex sections.
Cost Analysis
An extensive economic analysis was conducted, taking into account token costs for input and output across models. GPT-3.5 models exhibited the lowest cost, while GPT-4 models showed substantial improvements in contextual understanding against higher operational costs (Figure 3, Table 1).
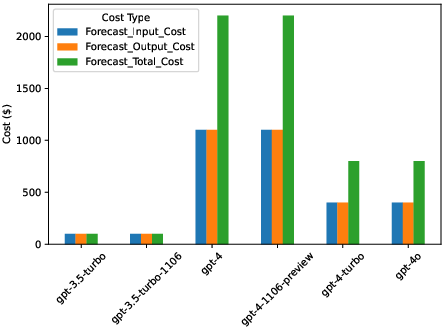
Figure 3: Forecast Cost Analysis for GPT Models with Varying Number of Examples.
| Model |
Sections Generated |
Annual Cost |
| gpt-3.5-turbo |
Entire Protocol |
$15,000 |
| gpt-4 |
Entire Protocol |
$225,000 |
| gpt-4o |
Entire Protocol |
$75,000 |
Table 1 demonstrates the significant cost variance, emphasizing the balance between cost and accuracy offered by models like GPT-4-turbo and GPT-4o.
Discussion
This paper showcases the transformative potential of LLMs in medical research, particularly in protocol authoring, promising time, cost savings, and improved accuracy. The implementation of AI technologies can enhance protocol development, providing tailored sections, reducing manual effort, and minimizing human error.
Challenges and Future Directions
Challenges included generating long-format content and maintaining protocol consistency across different applications. Future research might explore an expanded dataset to include a broader range of medical interventions and trial types, advancing AI's role in clinical research.
Conclusion
The integration of LLMs into clinical trial protocol development marks a significant advancement for the field. By leveraging generative AI models like GPT-4, this approach not only streamlines the authoring process but sets a foundation for future innovations in clinical research, highlighting AI's potential in automating complex tasks and enhancing operational efficiency. The paper provides a compelling case for widening the scope of AI applications in medical research, ushering in a new era of precision and optimization.