A Data-Centric Approach To Generate Faithful and High Quality Patient Summaries with Large Language Models
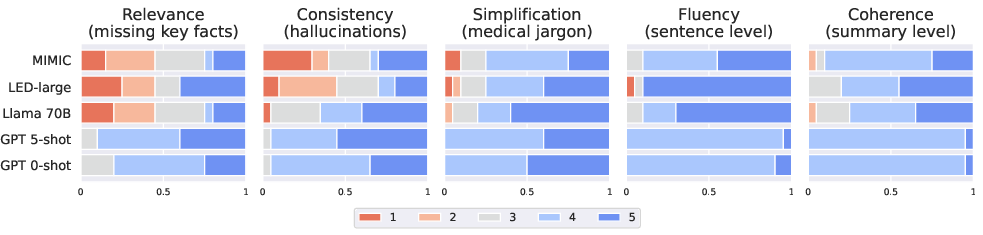
Abstract: Patients often face difficulties in understanding their hospitalizations, while healthcare workers have limited resources to provide explanations. In this work, we investigate the potential of LLMs to generate patient summaries based on doctors' notes and study the effect of training data on the faithfulness and quality of the generated summaries. To this end, we release (i) a rigorous labeling protocol for errors in medical texts and (ii) a publicly available dataset of annotated hallucinations in 100 doctor-written and 100 generated summaries. We show that fine-tuning on hallucination-free data effectively reduces hallucinations from 2.60 to 1.55 per summary for Llama 2, while preserving relevant information. We observe a similar effect on GPT-4 (0.70 to 0.40), when the few-shot examples are hallucination-free. We also conduct a qualitative evaluation using hallucination-free and improved training data. We find that common quantitative metrics do not correlate well with faithfulness and quality. Finally, we test GPT-4 for automatic hallucination detection, which clearly outperforms common baselines.
- What’s in a Summary? Laying the Groundwork for Advances in Hospital-Course Summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4794–4811, Online, June 2021. Association for Computational Linguistics. 10.18653/v1/2021.naacl-main.382. URL https://aclanthology.org/2021.naacl-main.382.
- Learning to Revise References for Faithful Summarization, October 2022. URL http://arxiv.org/abs/2204.10290. arXiv:2204.10290 [cs].
- A Meta-Evaluation of Faithfulness Metrics for Long-Form Hospital-Course Summarization, March 2023. URL http://arxiv.org/abs/2303.03948. arXiv:2303.03948 [cs].
- Focus Attention: Promoting Faithfulness and Diversity in Summarization. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 6078–6095, Online, August 2021. Association for Computational Linguistics. 10.18653/v1/2021.acl-long.474. URL https://aclanthology.org/2021.acl-long.474.
- Large language models in simplifying radiological reports: systematic review. preprint, Radiology and Imaging, January 2024. URL http://medrxiv.org/lookup/doi/10.1101/2024.01.05.24300884.
- Evaluation of drug information for cardiology patients. British Journal of Clinical Pharmacology, 31(5):525–531, 1991. ISSN 1365-2125. 10.1111/j.1365-2125.1991.tb05574.x. URL https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1365-2125.1991.tb05574.x. _eprint: https://onlinelibrary.wiley.com/doi/pdf/10.1111/j.1365-2125.1991.tb05574.x.
- Interventions to Improve Communication at Hospital Discharge and Rates of Readmission: A Systematic Review and Meta-analysis. JAMA Network Open, 4(8):e2119346, August 2021. ISSN 2574-3805. 10.1001/jamanetworkopen.2021.19346. URL https://jamanetwork.com/journals/jamanetworkopen/fullarticle/2783547.
- Longformer: The Long-Document Transformer, December 2020. URL http://arxiv.org/abs/2004.05150. arXiv:2004.05150 [cs].
- Lukas Biewald. Experiment tracking with weights and biases. Software available from wandb. com, 2:233, 2020.
- Generation of Patient After-Visit Summaries to Support Physicians. In Proceedings of the 29th International Conference on Computational Linguistics, pages 6234–6247, Gyeongju, Republic of Korea, October 2022. International Committee on Computational Linguistics. URL https://aclanthology.org/2022.coling-1.544.
- Shuyang Cao and Lu Wang. CLIFF: Contrastive Learning for Improving Faithfulness and Factuality in Abstractive Summarization. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6633–6649, Online and Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. 10.18653/v1/2021.emnlp-main.532. URL https://aclanthology.org/2021.emnlp-main.532.
- Faithful to the original: fact-aware neural abstractive summarization. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, AAAI’18/IAAI’18/EAAI’18, pages 4784–4791, New Orleans, Louisiana, USA, February 2018. AAAI Press. ISBN 978-1-57735-800-8.
- Effect of personalised, mobile-accessible discharge instructions for patients leaving the emergency department: A randomised controlled trial. Emergency Medicine Australasia, 32(6):967–973, 2020. ISSN 1742-6723. 10.1111/1742-6723.13516. URL https://onlinelibrary.wiley.com/doi/abs/10.1111/1742-6723.13516. _eprint: https://onlinelibrary.wiley.com/doi/pdf/10.1111/1742-6723.13516.
- SummEval: Re-evaluating Summarization Evaluation, February 2021. URL http://arxiv.org/abs/2007.12626. arXiv:2007.12626 [cs].
- Challenges optimizing the after visit summary. International journal of medical informatics, 120:14–19, December 2018. ISSN 1386-5056. 10.1016/j.ijmedinf.2018.09.009. URL https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6326571/.
- Qlarify: Bridging Scholarly Abstracts and Papers with Recursively Expandable Summaries, October 2023. URL http://arxiv.org/abs/2310.07581. arXiv:2310.07581 [cs].
- Using Health Literacy and Learning Style Preferences to Optimize the Delivery of Health Information. Journal of Health Communication, 17(sup3):122–140, October 2012. ISSN 1081-0730, 1087-0415. 10.1080/10810730.2012.712610. URL http://www.tandfonline.com/doi/abs/10.1080/10810730.2012.712610.
- PhysioBank, PhysioToolkit, and PhysioNet: Components of a New Research Resource for Complex Physiologic Signals. Circulation, 101(23), June 2000. ISSN 0009-7322, 1524-4539. 10.1161/01.CIR.101.23.e215. URL https://www.ahajournals.org/doi/10.1161/01.CIR.101.23.e215.
- Evaluating the Use of ChatGPT to Accurately Simplify Patient-centered Information about Breast Cancer Prevention and Screening. Radiology: Imaging Cancer, 6(2):e230086, March 2024. 10.1148/rycan.230086. URL https://pubs.rsna.org/doi/abs/10.1148/rycan.230086. Publisher: Radiological Society of North America.
- Karen S. Hayes. Randomized Trial of Geragogy-Based Medication Instruction in the Emergency Department. Nursing Research, 47(4):211, August 1998. ISSN 0029-6562. URL https://journals.lww.com/nursingresearchonline/fulltext/1998/07000/randomized_trial_of_geragogy_based_medication.6.aspx.
- MedTator: a serverless annotation tool for corpus development. Bioinformatics, 38(6):1776–1778, March 2022. ISSN 1367-4803. 10.1093/bioinformatics/btab880. URL https://doi.org/10.1093/bioinformatics/btab880.
- Teaching Machines to Read and Comprehend. In Advances in Neural Information Processing Systems, volume 28. Curran Associates, Inc., 2015. URL https://proceedings.neurips.cc/paper_files/paper/2015/hash/afdec7005cc9f14302cd0474fd0f3c96-Abstract.html.
- Quality of Discharge Practices and Patient Understanding at an Academic Medical Center. JAMA Internal Medicine, August 2013. ISSN 2168-6106. 10.1001/jamainternmed.2013.9318. URL http://archinte.jamanetwork.com/article.aspx?doi=10.1001/jamainternmed.2013.9318.
- LoRA: Low-Rank Adaptation of Large Language Models, October 2021. URL http://arxiv.org/abs/2106.09685. arXiv:2106.09685 [cs].
- The Factual Inconsistency Problem in Abstractive Text Summarization: A Survey, April 2023. URL http://arxiv.org/abs/2104.14839. arXiv:2104.14839 [cs].
- MIMIC-IV-Note: Deidentified free-text clinical notes, January 2023. URL https://physionet.org/content/mimic-iv-note/2.2/.
- Patients’ Understanding of Their Hospitalizations and Association With Satisfaction. JAMA Internal Medicine, 174(10):1698–1700, October 2014. ISSN 2168-6106. 10.1001/jamainternmed.2014.3765. URL https://doi.org/10.1001/jamainternmed.2014.3765.
- Multi-domain clinical natural language processing with MedCAT: The Medical Concept Annotation Toolkit. Artificial Intelligence in Medicine, 117:102083, July 2021. ISSN 0933-3657. 10.1016/j.artmed.2021.102083. URL https://www.sciencedirect.com/science/article/pii/S0933365721000762.
- Klaus Krippendorff. Content Analysis: An Introduction to Its Methodology. SAGE Publications, May 2018. ISBN 978-1-5063-9567-8. Google-Books-ID: nE1aDwAAQBAJ.
- Evaluating the Factual Consistency of Abstractive Text Summarization. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9332–9346, Online, November 2020. Association for Computational Linguistics. 10.18653/v1/2020.emnlp-main.750. URL https://aclanthology.org/2020.emnlp-main.750.
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors, Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, Online, July 2020. Association for Computational Linguistics. 10.18653/v1/2020.acl-main.703. URL https://aclanthology.org/2020.acl-main.703.
- Chin-Yew Lin. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain, July 2004. Association for Computational Linguistics. URL https://aclanthology.org/W04-1013.
- Effect of a patient-directed discharge letter on patient understanding of their hospitalisation. Internal Medicine Journal, 44(9):851–857, 2014. ISSN 1445-5994. 10.1111/imj.12482. URL https://onlinelibrary.wiley.com/doi/abs/10.1111/imj.12482. _eprint: https://onlinelibrary.wiley.com/doi/pdf/10.1111/imj.12482.
- Self-Alignment Pretraining for Biomedical Entity Representations. In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou, editors, Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4228–4238, Online, June 2021. Association for Computational Linguistics. 10.18653/v1/2021.naacl-main.334. URL https://aclanthology.org/2021.naacl-main.334.
- Laurens van der Maaten and Geoffrey Hinton. Visualizing Data using t-SNE. Journal of Machine Learning Research, 9(86):2579–2605, 2008. ISSN 1533-7928. URL http://jmlr.org/papers/v9/vandermaaten08a.html.
- On Faithfulness and Factuality in Abstractive Summarization. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors, Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1906–1919, Online, July 2020. Association for Computational Linguistics. 10.18653/v1/2020.acl-main.173. URL https://aclanthology.org/2020.acl-main.173.
- Fine-grained Hallucination Detection and Editing for Language Models, January 2024. URL http://arxiv.org/abs/2401.06855. arXiv:2401.06855 [cs].
- Human Evaluation and Correlation with Automatic Metrics in Consultation Note Generation. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors, Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5739–5754, Dublin, Ireland, May 2022. Association for Computational Linguistics. 10.18653/v1/2022.acl-long.394. URL https://aclanthology.org/2022.acl-long.394.
- Readability of patient discharge instructions with and without the use of electronically available disease-specific templates. Journal of the American Medical Informatics Association, 22(4):857–863, July 2015. ISSN 1527-974X, 1067-5027. 10.1093/jamia/ocv005. URL https://academic.oup.com/jamia/article/22/4/857/1746200.
- Entity-level Factual Consistency of Abstractive Text Summarization. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 2727–2733, Online, April 2021. Association for Computational Linguistics. 10.18653/v1/2021.eacl-main.235. URL https://aclanthology.org/2021.eacl-main.235.
- GPT-4 Technical Report, December 2023. URL http://arxiv.org/abs/2303.08774. arXiv:2303.08774 [cs].
- Patient-Reported Use of the After Visit Summary in a Primary Care Internal Medicine Practice. Journal of Patient Experience, 7(5):703–707, October 2020. ISSN 2374-3735. 10.1177/2374373519879286. URL https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7705830/.
- Carswella Phillips. Relationships between workload perception, burnout, and intent to leave among medical–surgical nurses. JBI Evidence Implementation, 18(2):265, June 2020. ISSN 2691-3321. 10.1097/XEB.0000000000000220. URL https://journals.lww.com/ijebh/abstract/2020/06000/relationships_between_workload_perception,.11.aspx.
- SemEval-2013 Task 9 : Extraction of Drug-Drug Interactions from Biomedical Texts (DDIExtraction 2013). In Suresh Manandhar and Deniz Yuret, editors, Second Joint Conference on Lexical and Computational Semantics (*SEM), Volume 2: Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013), pages 341–350, Atlanta, Georgia, USA, June 2013. Association for Computational Linguistics. URL https://aclanthology.org/S13-2056.
- WikiChat: Stopping the Hallucination of Large Language Model Chatbots by Few-Shot Grounding on Wikipedia, October 2023. URL http://arxiv.org/abs/2305.14292. arXiv:2305.14292 [cs].
- A Gold Standard Methodology for Evaluating Accuracy in Data-To-Text Systems. In Brian Davis, Yvette Graham, John Kelleher, and Yaji Sripada, editors, Proceedings of the 13th International Conference on Natural Language Generation, pages 158–168, Dublin, Ireland, December 2020. Association for Computational Linguistics. URL https://aclanthology.org/2020.inlg-1.22.
- Generation Challenges: Results of the Accuracy Evaluation Shared Task, August 2021. URL http://arxiv.org/abs/2108.05644. arXiv:2108.05644 [cs].
- Evaluating factual accuracy in complex data-to-text. Computer Speech & Language, 80:101482, May 2023. ISSN 0885-2308. 10.1016/j.csl.2023.101482. URL https://www.sciencedirect.com/science/article/pii/S0885230823000013.
- Fine-tuning Language Models for Factuality, November 2023. URL http://arxiv.org/abs/2311.08401. arXiv:2311.08401 [cs].
- Llama 2: Open Foundation and Fine-Tuned Chat Models, July 2023. URL http://arxiv.org/abs/2307.09288. arXiv:2307.09288 [cs].
- RadAdapt: Radiology Report Summarization via Lightweight Domain Adaptation of Large Language Models, May 2023a. URL http://arxiv.org/abs/2305.01146. arXiv:2305.01146 [cs].
- Clinical Text Summarization: Adapting Large Language Models Can Outperform Human Experts, October 2023b. URL http://arxiv.org/abs/2309.07430. arXiv:2309.07430 [cs].
- Impact of physician workload on burnout in the emergency department. Psychology, Health & Medicine, 24(4):414–428, April 2019. ISSN 1354-8506. 10.1080/13548506.2018.1539236. URL https://doi.org/10.1080/13548506.2018.1539236. Publisher: Taylor & Francis _eprint: https://doi.org/10.1080/13548506.2018.1539236.
- Unsupervised Clinical Language Translation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’19, pages 3121–3131, New York, NY, USA, July 2019. Association for Computing Machinery. ISBN 978-1-4503-6201-6. 10.1145/3292500.3330710. URL https://dl.acm.org/doi/10.1145/3292500.3330710.
- HuggingFace’s Transformers: State-of-the-art Natural Language Processing, July 2020. URL http://arxiv.org/abs/1910.03771. arXiv:1910.03771 [cs].
- FactReranker: Fact-guided Reranker for Faithful Radiology Report Summarization, March 2023. URL http://arxiv.org/abs/2303.08335. arXiv:2303.08335 [cs].
- Optimizing Statistical Machine Translation for Text Simplification. Transactions of the Association for Computational Linguistics, 4:401–415, 2016. 10.1162/tacl_a_00107. URL https://aclanthology.org/Q16-1029. Place: Cambridge, MA Publisher: MIT Press.
- BERTScore: Evaluating Text Generation with BERT, February 2020a. URL http://arxiv.org/abs/1904.09675. arXiv:1904.09675 [cs].
- Optimizing the Factual Correctness of a Summary: A Study of Summarizing Radiology Reports. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors, Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5108–5120, Online, July 2020b. Association for Computational Linguistics. 10.18653/v1/2020.acl-main.458. URL https://aclanthology.org/2020.acl-main.458.
- Detecting Hallucinated Content in Conditional Neural Sequence Generation. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 1393–1404, Online, August 2021. Association for Computational Linguistics. 10.18653/v1/2021.findings-acl.120. URL https://aclanthology.org/2021.findings-acl.120.
- LIMA: Less Is More for Alignment. In Thirty-seventh Conference on Neural Information Processing Systems, November 2023. URL https://openreview.net/forum?id=KBMOKmX2he.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.