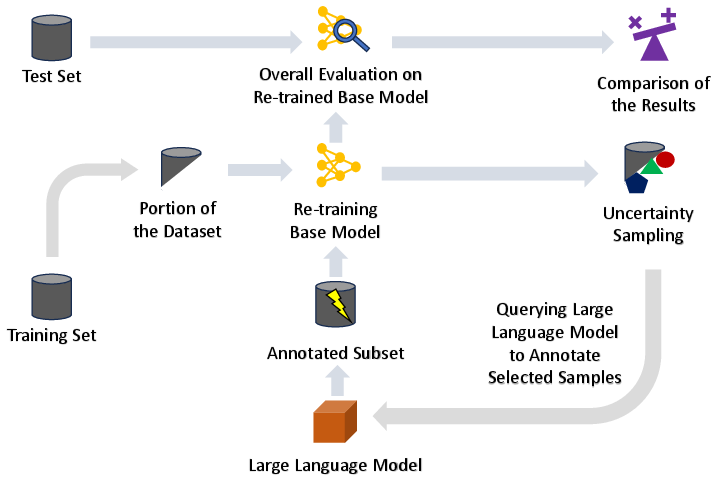
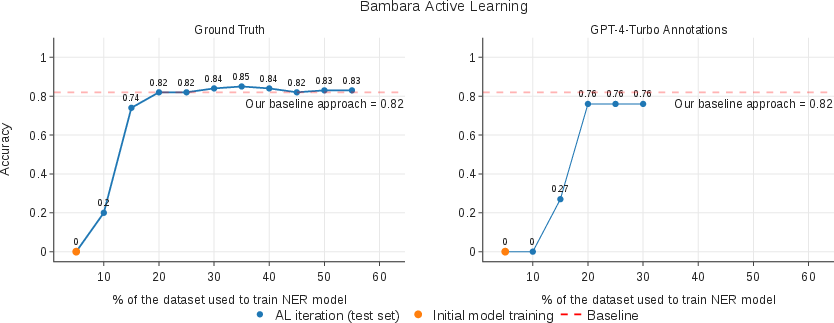
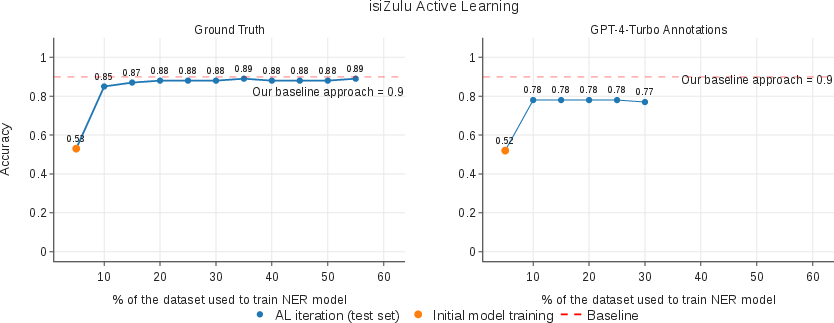
LLMs in the Loop: Leveraging Large Language Model Annotations for Active Learning in Low-Resource Languages
Abstract: Low-resource languages face significant barriers in AI development due to limited linguistic resources and expertise for data labeling, rendering them rare and costly. The scarcity of data and the absence of preexisting tools exacerbate these challenges, especially since these languages may not be adequately represented in various NLP datasets. To address this gap, we propose leveraging the potential of LLMs in the active learning loop for data annotation. Initially, we conduct evaluations to assess inter-annotator agreement and consistency, facilitating the selection of a suitable LLM annotator. The chosen annotator is then integrated into a training loop for a classifier using an active learning paradigm, minimizing the amount of queried data required. Empirical evaluations, notably employing GPT-4-Turbo, demonstrate near-state-of-the-art performance with significantly reduced data requirements, as indicated by estimated potential cost savings of at least 42.45 times compared to human annotation. Our proposed solution shows promising potential to substantially reduce both the monetary and computational costs associated with automation in low-resource settings. By bridging the gap between low-resource languages and AI, this approach fosters broader inclusion and shows the potential to enable automation across diverse linguistic landscapes.
- “MasakhaNER 2.0: Africa-centric Transfer Learning for Named Entity Recognition” In Conference on Empirical Methods in Natural Language Processing, 2022 URL: https://api.semanticscholar.org/CorpusID:253098583
- “Adapting Pre-trained Language Models to African Languages via Multilingual Adaptive Fine-Tuning” In Proceedings of the 29th International Conference on Computational Linguistics Gyeongju, Republic of Korea: International Committee on Computational Linguistics, 2022, pp. 4336–4349 URL: https://aclanthology.org/2022.coling-1.382
- Anthropic “Introducing the next generation of Claude” Accessed: March 13, 2024, 2024 URL: https://www.anthropic.com/news/claude-3-family
- “A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity”, 2023 arXiv:2302.04023 [cs.CL]
- “On the Opportunities and Risks of Foundation Models”, 2022 arXiv:2108.07258 [cs.LG]
- “Language models are few-shot learners” In Advances in neural information processing systems 33, 2020, pp. 1877–1901
- “Can large language models be an alternative to human evaluations?” In arXiv preprint arXiv:2305.01937, 2023
- “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”, 2019 arXiv:1810.04805 [cs.CL]
- “Fast and Accurate Annotation of Short Texts with Wikipedia Pages” In IEEE Software 29, 2010, pp. 70–75 DOI: 10.1109/MS.2011.122
- Joseph Fleiss “Measuring Nominal Scale Agreement Among Many Raters” In Psychological Bulletin 76, 1971, pp. 378– DOI: 10.1037/h0031619
- Fabrizio Gilardi, Meysam Alizadeh and Maël Kubli “ChatGPT outperforms crowd workers for text-annotation tasks” In Proceedings of the National Academy of Sciences 120.30 National Acad Sciences, 2023, pp. e2305016120
- “Time Travel in LLMs: Tracing Data Contamination in Large Language Models”, 2024 arXiv:2308.08493 [cs.CL]
- “Annollm: Making large language models to be better crowdsourced annotators” In arXiv preprint arXiv:2303.16854, 2023
- “Mistral 7B”, 2023 arXiv:2310.06825 [cs.CL]
- “Active learning reduces annotation time for clinical concept extraction” In International journal of medical informatics 106, 2017, pp. 25–31 DOI: 10.1016/j.ijmedinf.2017.08.001
- “Large language models are zero-shot reasoners” In Advances in neural information processing systems 35, 2022, pp. 22199–22213
- “Visualization-Based Active Learning for Video Annotation” In IEEE Transactions on Multimedia 18, 2016, pp. 2196–2205 DOI: 10.1109/TMM.2016.2614227
- “A Comprehensive Overview of Large Language Models” In ArXiv abs/2307.06435, 2023 DOI: 10.48550/arXiv.2307.06435
- Aurélie Névéol, R. Dogan and Zhiyong Lu “Semi-automatic semantic annotation of PubMed queries: A study on quality, efficiency, satisfaction” In Journal of biomedical informatics 44 2, 2011, pp. 310–8 DOI: 10.1016/j.jbi.2010.11.001
- “GPT-4 Technical Report”, 2023 arXiv:2303.08774 [cs.CL]
- Nicholas Pangakis, Samuel Wolken and Neil Fasching “Automated annotation with generative ai requires validation” In arXiv preprint arXiv:2306.00176, 2023
- Afshin Rahimi, Yuan Li and Trevor Cohn “Massively Multilingual Transfer for NER” In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics Florence, Italy: Association for Computational Linguistics, 2019, pp. 151–164 URL: https://www.aclweb.org/anthology/P19-1015
- “Challenging big-bench tasks and whether chain-of-thought can solve them” In arXiv preprint arXiv:2210.09261, 2022
- “Gemini: A Family of Highly Capable Multimodal Models”, 2023 arXiv:2312.11805 [cs.CL]
- Erik F. Tjong Kim Sang and Fien De Meulder “Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition” In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, 2003, pp. 142–147 URL: https://aclanthology.org/W03-0419
- “Llama 2: Open Foundation and Fine-Tuned Chat Models”, 2023 arXiv:2307.09288 [cs.CL]
- “Gpt-ner: Named entity recognition via large language models” In arXiv preprint arXiv:2304.10428, 2023
- “Zero-shot information extraction via chatting with chatgpt” In arXiv preprint arXiv:2302.10205, 2023
- “React: Synergizing reasoning and acting in language models” In arXiv preprint arXiv:2210.03629, 2022
- “Selecting Better Samples from Pre-trained LLMs: A Case Study on Question Generation”, 2022 arXiv:2209.11000 [cs.CL]
- “Llmaaa: Making large language models as active annotators” In arXiv preprint arXiv:2310.19596, 2023
- “Adapting language models for zero-shot learning by meta-tuning on dataset and prompt collections” In arXiv preprint arXiv:2104.04670, 2021
- “Starling-7B: Improving LLM Helpfulness & Harmlessness with RLAIF”, 2023
- “Can large language models transform computational social science?” In Computational Linguistics MIT Press One Broadway, 12th Floor, Cambridge, Massachusetts 02142, USA …, 2024, pp. 1–55
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.