- The paper introduces ActivePrune, a two-stage framework combining fast perplexity evaluation and LLM-based sampling to prune data efficiently in active learning.
- It demonstrates substantial efficiency gains by reducing active learning time by up to 74% and cutting computational costs by 97% compared to conventional methods.
- Results across tasks like translation and sentiment analysis reveal improved evaluation metrics, underscoring ActivePrune’s practical impact on scalable data selection.
LLM-Driven Data Pruning Enables Efficient Active Learning
The paper "LLM-Driven Data Pruning Enables Efficient Active Learning" proposes an innovative framework, ActivePrune, to enhance active learning (AL) methodologies by leveraging LLM-driven data pruning techniques. ActivePrune addresses the substantial computational overhead associated with conventional AL acquisition functions when processing large unlabeled data pools.
Introduction
Active learning optimizes data labeling by strategically selecting the most informative samples from an unlabeled dataset, thus improving model performance while minimizing the labeling burden. Despite its potential for significant efficiency gains, AL faces practical constraints due to the high computational demands of acquisition functions used to assess large datasets.
ActivePrune introduces a novel approach to scalably reduce the size of these unlabeled pools without sacrificing the quality of data selection. This is achieved through two key methodologies: fast perplexity evaluation using n-gram LLMs and high-quality sampling driven by LLMs, enabling AL to operate efficiently even on extensive datasets.
ActivePrune Framework
ActivePrune employs a two-stage pruning mechanism to streamline the AL process:
- Perplexity Evaluation:
- Utilizes the KenLM 5-gram model to compute perplexity scores for the entire unlabeled dataset swiftly.
- Low perplexity scores highlight examples less likely to contain noise or surprises, thus suited for initial pruning.
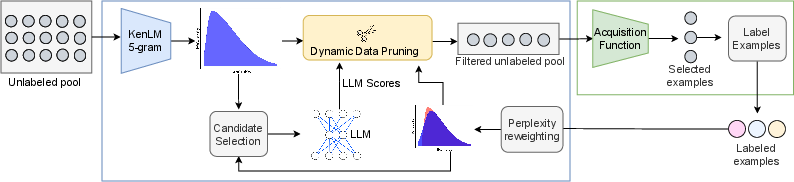
Figure 1: Illustration of the proposed ActivePrune framework for data pruning in Active Learning. Perplexity scores are first computed for the entire unlabeled pool through the KenLM 5-gram model, followed by the computation of data quality scores on a subset of examples through a quantized LLM. Then, the data pruning strategy leverages both these scores to prune the unlabeled pool and send it as the input to the AL acquisition function. After each iteration, a reweighting algorithm adjusts the perplexity distribution based on the selected examples to enhance the diversity for the next iteration.
- LLM Quality-Based Sampling:
- For examples with high perplexity, data quality scores are calculated using a quantized LLM.
- A prompt-based assessment determines the inclusion likelihood of data samples in the training process, ensuring diversity and quality.
ActivePrune resolves computational inefficiencies by focusing only on a subset of data using a quantized LLM, significantly reducing inference costs compared to full LLM utilization.
Implementation and Results
ActivePrune's efficacy is evaluated across diverse tasks, including translation, sentiment analysis, topic classification, and summarization over datasets such as IT Domain, AESLC, IMDB, and AG News. Key findings are:
- Efficiency Gains: ActivePrune reduces active learning time by up to 74%.
- Selection Quality: Achieves higher evaluation metrics (SacreBLEU, ROUGE-L, F1-Score) across AL strategies when compared to other data pruning methods.
- Computational Savings: Demonstrates a 97% reduction in computational costs compared to conventional score-based algorithms.
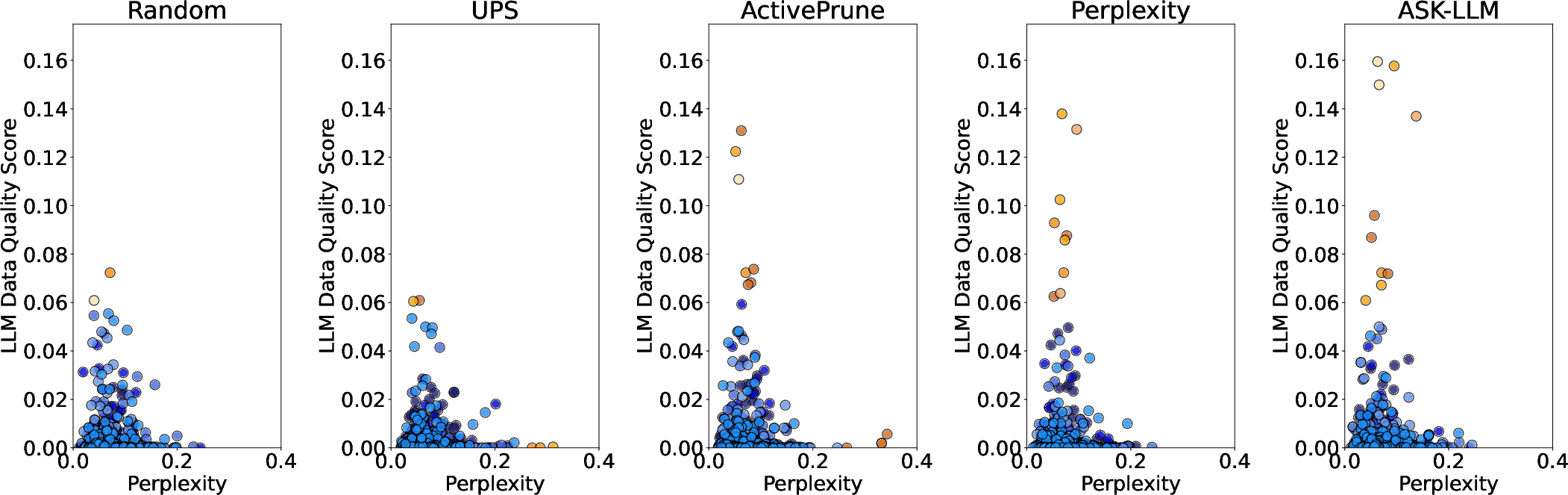
Figure 2: Distribution of Perplexity vs LLM data quality scores across samples selected through different pruning methods for the IMDB dataset. Each subplot represents sentences selected through the Active Learning (AL) procedure across 10 iterations, with each iteration involving the selection of 1\% of the dataset. Examples with orange color indicate examples with a high LLM quality score or a high perplexity score. The color gradient indicates the sequence of iterations, where the darkest shade denotes the first iteration and progressively lighter shades denote subsequent iterations, up to the lightest shade for the tenth iteration. Subplots are organized by sampling strategy.
Conclusion
ActivePrune presents a versatile framework that integrates LLM-driven data pruning techniques into active learning, significantly enhancing computational efficiency and selection quality. This approach fosters broader applicability of AL to large datasets in domain-specific scenarios, optimizing resource utilization and enhancing interactivity during data labeling processes. Future work might explore privacy and fairness implications of dataset pruning, ensuring equitable representation during model training.