Learning to Compress Prompt in Natural Language Formats
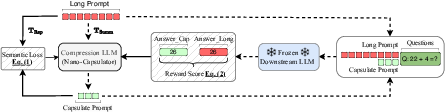
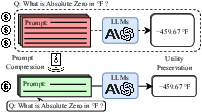
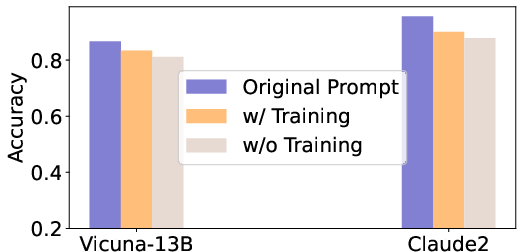
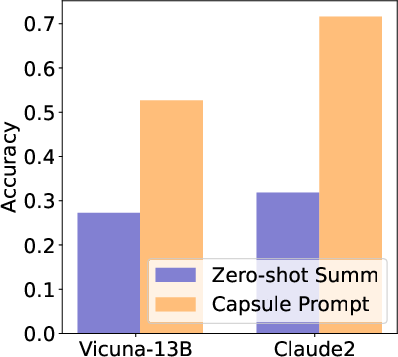
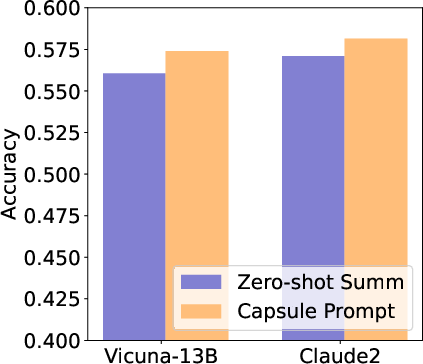
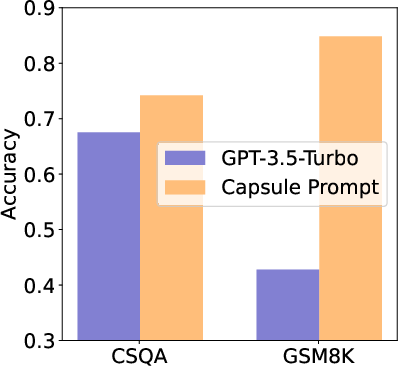
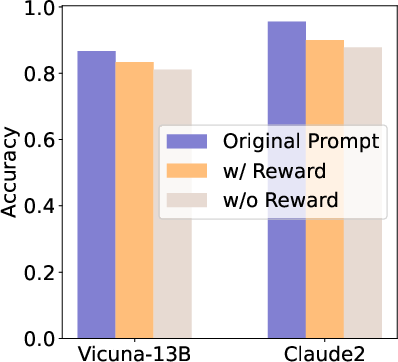
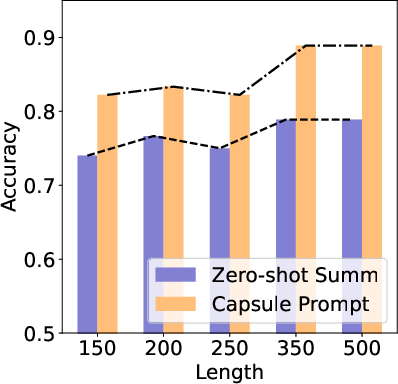
Abstract: LLMs are great at processing multiple natural language processing tasks, but their abilities are constrained by inferior performance with long context, slow inference speed, and the high cost of computing the results. Deploying LLMs with precise and informative context helps users process large-scale datasets more effectively and cost-efficiently. Existing works rely on compressing long prompt contexts into soft prompts. However, soft prompt compression encounters limitations in transferability across different LLMs, especially API-based LLMs. To this end, this work aims to compress lengthy prompts in the form of natural language with LLM transferability. This poses two challenges: (i) Natural Language (NL) prompts are incompatible with back-propagation, and (ii) NL prompts lack flexibility in imposing length constraints. In this work, we propose a Natural Language Prompt Encapsulation (Nano-Capsulator) framework compressing original prompts into NL formatted Capsule Prompt while maintaining the prompt utility and transferability. Specifically, to tackle the first challenge, the Nano-Capsulator is optimized by a reward function that interacts with the proposed semantics preserving loss. To address the second question, the Nano-Capsulator is optimized by a reward function featuring length constraints. Experimental results demonstrate that the Capsule Prompt can reduce 81.4% of the original length, decrease inference latency up to 4.5x, and save 80.1% of budget overheads while providing transferability across diverse LLMs and different datasets.
- Anthropic. 2023. Claude.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Adapting language models to compress contexts. arXiv preprint arXiv:2305.14788.
- Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.
- Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113.
- Boolq: Exploring the surprising difficulty of natural yes/no questions. arXiv preprint arXiv:1905.10044.
- Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Eraser: A benchmark to evaluate rationalized nlp models.
- In-context autoencoder for context compression in a large language model. arXiv preprint arXiv:2307.06945.
- Llmlingua: Compressing prompts for accelerated inference of large language models. arXiv preprint arXiv:2310.05736.
- Llm maybe longlm: Self-extend llm context window without tuning. arXiv preprint arXiv:2401.01325.
- triviaqa: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. arXiv e-prints, page arXiv:1705.03551.
- Looking beyond the surface:a challenge set for reading comprehension over multiple sentences. In Proceedings of North American Chapter of the Association for Computational Linguistics (NAACL).
- Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199–22213.
- Compressing context to enhance inference efficiency of large language models. arXiv preprint arXiv:2310.06201.
- G-eval: Nlg evaluation using gpt-4 with better human alignment, may 2023. arXiv preprint arXiv:2303.16634, 6.
- Learning to compress prompts with gist tokens. arXiv preprint arXiv:2304.08467.
- Context compression for auto-regressive transformers with sentinel tokens. arXiv preprint arXiv:2310.08152.
- Subhro Roy and Dan Roth. 2015. Solving general arithmetic word problems. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics.
- CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158, Minneapolis, Minnesota. Association for Computational Linguistics.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837.
- Prompt compression and contrastive conditioning for controllability and toxicity reduction in language models. arXiv preprint arXiv:2210.03162.
- Harnessing the power of llms in practice: A survey on chatgpt and beyond. arXiv preprint arXiv:2304.13712.
- Opt: Open pre-trained transformer language models.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.