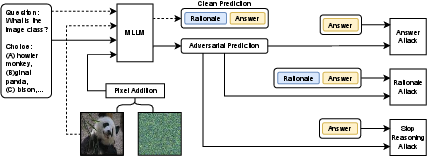
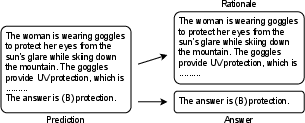
Stop Reasoning! When Multimodal LLM with Chain-of-Thought Reasoning Meets Adversarial Image
Abstract: Multimodal LLMs (MLLMs) with a great ability of text and image understanding have received great attention. To achieve better reasoning with MLLMs, Chain-of-Thought (CoT) reasoning has been widely explored, which further promotes MLLMs' explainability by giving intermediate reasoning steps. Despite the strong power demonstrated by MLLMs in multimodal reasoning, recent studies show that MLLMs still suffer from adversarial images. This raises the following open questions: Does CoT also enhance the adversarial robustness of MLLMs? What do the intermediate reasoning steps of CoT entail under adversarial attacks? To answer these questions, we first generalize existing attacks to CoT-based inferences by attacking the two main components, i.e., rationale and answer. We find that CoT indeed improves MLLMs' adversarial robustness against the existing attack methods by leveraging the multi-step reasoning process, but not substantially. Based on our findings, we further propose a novel attack method, termed as stop-reasoning attack, that attacks the model while bypassing the CoT reasoning process. Experiments on three MLLMs and two visual reasoning datasets verify the effectiveness of our proposed method. We show that stop-reasoning attack can result in misled predictions and outperform baseline attacks by a significant margin.
- Threat of adversarial attacks on deep learning in computer vision: A survey. Ieee Access, 6:14410–14430, 2018.
- Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. In International conference on machine learning, pp. 274–283. PMLR, 2018.
- OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models, August 2023. URL http://arxiv.org/abs/2308.01390. arXiv:2308.01390 [cs].
- Complex query answering on eventuality knowledge graph with implicit logical constraints. arXiv preprint arXiv:2305.19068, 2023.
- Towards evaluating the robustness of neural networks. In 2017 ieee symposium on security and privacy (sp), pp. 39–57. Ieee, 2017.
- On Evaluating Adversarial Robustness, February 2019. URL http://arxiv.org/abs/1902.06705. arXiv:1902.06705 [cs, stat].
- Are aligned neural networks adversarially aligned? arXiv preprint arXiv:2306.15447, 2023.
- Elements of Information Theory. Wiley, 2012. ISBN 9781118585771. URL https://books.google.de/books?id=VWq5GG6ycxMC.
- Large-scale adversarial training for vision-and-language representation learning. Advances in Neural Information Processing Systems, 33:6616–6628, 2020.
- Inducing high energy-latency of large vision-language models with verbose images. arXiv preprint arXiv:2401.11170, 2024.
- Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572, 2014.
- Saliency methods for explaining adversarial attacks. arXiv preprint arXiv:1908.08413, 2019.
- Effective and efficient vote attack on capsule networks. arXiv preprint arXiv:2102.10055, 2021.
- Ot-attack: Enhancing adversarial transferability of vision-language models via optimal transport optimization. arXiv preprint arXiv:2312.04403, 2023.
- Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
- Multi-modal latent space learning for chain-of-thought reasoning in language models. arXiv preprint arXiv:2312.08762, 2023.
- Large Language Models are Zero-Shot Reasoners, January 2023. URL http://arxiv.org/abs/2205.11916. arXiv:2205.11916 [cs].
- Certifying llm safety against adversarial prompting. arXiv preprint arXiv:2309.02705, 2023.
- Interpretable deep learning: Interpretation, interpretability, trustworthiness, and beyond. Knowledge and Information Systems, 64(12):3197–3234, 2022.
- Improved Baselines with Visual Instruction Tuning, October 2023. URL http://arxiv.org/abs/2310.03744. arXiv:2310.03744 [cs].
- Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering, October 2022. URL http://arxiv.org/abs/2209.09513. arXiv:2209.09513 [cs].
- An image is worth 1000 lies: Transferability of adversarial images across prompts on vision-language models. In To appear in ICLR, 2024. URL https://openreview.net/forum?id=nc5GgFAvtk.
- Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083, 2017.
- Towards Deep Learning Models Resistant to Adversarial Attacks, September 2019. URL http://arxiv.org/abs/1706.06083. arXiv:1706.06083 [cs, stat].
- Gpt-4 technical report, 2023.
- Visual adversarial examples jailbreak aligned large language models. In The Second Workshop on New Frontiers in Adversarial Machine Learning, volume 1, 2023.
- Imagenet large scale visual recognition challenge, 2015.
- A-OKVQA: A Benchmark for Visual Question Answering using World Knowledge, June 2022. URL http://arxiv.org/abs/2206.01718. arXiv:2206.01718 [cs].
- Large language models encode clinical knowledge. arXiv preprint arXiv:2212.13138, 2022.
- Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199, 2013.
- Llama 2: Open Foundation and Fine-Tuned Chat Models, July 2023. URL http://arxiv.org/abs/2307.09288. arXiv:2307.09288 [cs].
- Self-consistency improves chain of thought reasoning in language models. In The Eleventh International Conference on Learning Representations, 2022.
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, January 2023. URL http://arxiv.org/abs/2201.11903. arXiv:2201.11903 [cs].
- Analyzing chain-of-thought prompting in large language models via gradient-based feature attributions. arXiv preprint arXiv:2307.13339, 2023.
- Automatic Chain of Thought Prompting in Large Language Models, October 2022. URL http://arxiv.org/abs/2210.03493. arXiv:2210.03493 [cs].
- Multimodal Chain-of-Thought Reasoning in Language Models, February 2023. URL http://arxiv.org/abs/2302.00923. arXiv:2302.00923 [cs].
- On evaluating adversarial robustness of large vision-language models. arXiv preprint arXiv:2305.16934, 2023.
- MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models, April 2023. URL http://arxiv.org/abs/2304.10592. arXiv:2304.10592 [cs].
- Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043, 2023.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

