Adversarial Robustness for Visual Grounding of Multimodal Large Language Models
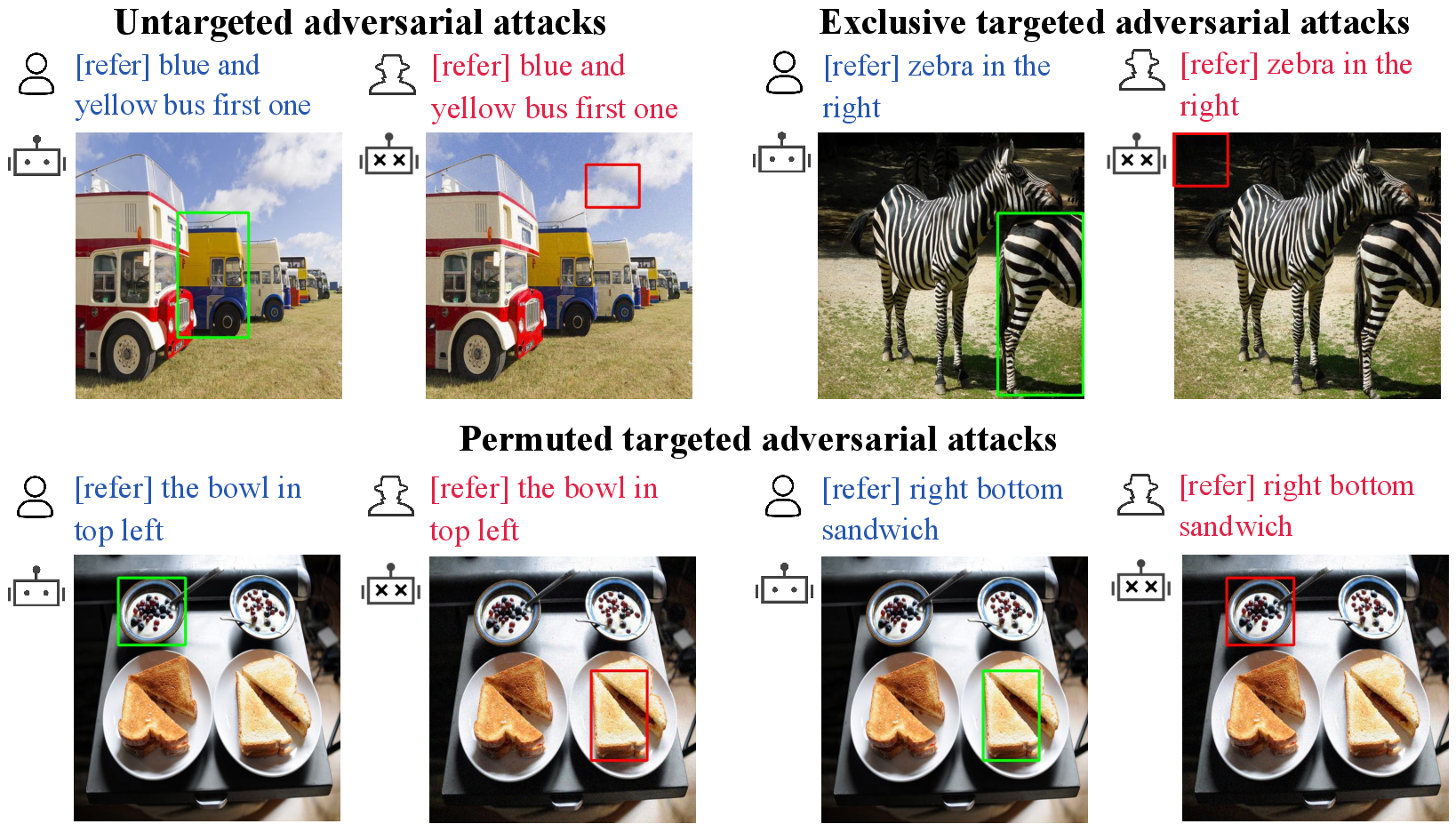
Abstract: Multi-modal LLMs (MLLMs) have recently achieved enhanced performance across various vision-language tasks including visual grounding capabilities. However, the adversarial robustness of visual grounding remains unexplored in MLLMs. To fill this gap, we use referring expression comprehension (REC) as an example task in visual grounding and propose three adversarial attack paradigms as follows. Firstly, untargeted adversarial attacks induce MLLMs to generate incorrect bounding boxes for each object. Besides, exclusive targeted adversarial attacks cause all generated outputs to the same target bounding box. In addition, permuted targeted adversarial attacks aim to permute all bounding boxes among different objects within a single image. Extensive experiments demonstrate that the proposed methods can successfully attack visual grounding capabilities of MLLMs. Our methods not only provide a new perspective for designing novel attacks but also serve as a strong baseline for improving the adversarial robustness for visual grounding of MLLMs.
- Flamingo: a visual language model for few-shot learning. In NeurIPS, 2022.
- (ab) using images and sounds for indirect instruction injection in multi-modal llms. arXiv preprint arXiv:2307.10490, 2023.
- Targeted attack for deep hashing based retrieval. In ECCV, 2020a.
- Hardly perceptible trojan attack against neural networks with bit flips. In ECCV, 2022a.
- Targeted attack against deep neural networks via flipping limited weight bits. In ICLR, 2022b.
- Badclip: Trigger-aware prompt learning for backdoor attacks on clip. arXiv preprint arXiv:2311.16194, 2023a.
- Versatile weight attack via flipping limited bits. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023b.
- Improving query efficiency of black-box adversarial attack. In ECCV, 2020b.
- Improving adversarial robustness via channel-wise activation suppressing. In ICLR, 2021.
- On evaluating adversarial robustness. arXiv preprint arXiv:1902.06705, 2019.
- Are aligned neural networks adversarially aligned? arXiv preprint arXiv:2306.15447, 2023.
- Visualgpt: Data-efficient adaptation of pretrained language models for image captioning. In CVPR, 2022.
- Minigpt-v2: large language model as a unified interface for vision-language multi-task learning. arXiv preprint arXiv:2310.09478, 2023a.
- Shikra: Unleashing multimodal llm’s referential dialogue magic. arXiv preprint arXiv:2306.15195, 2023b.
- Boosting adversarial attacks with momentum. In CVPR, 2018.
- How robust is google’s bard to adversarial image attacks? arXiv preprint arXiv:2309.11751, 2023.
- Imperceptible and robust backdoor attack in 3d point cloud. IEEE Transactions on Information Forensics and Security, 19:1267–1282, 2023a.
- Backdoor defense via adaptively splitting poisoned dataset. In CVPR, 2023b.
- Inducing high energy-latency of large vision-language models with verbose images. In ICLR, 2024a.
- Energy-latency manipulation of multi-modal large language models via verbose samples. arXiv preprint arXiv:2404.16557, 2024b.
- Explaining and harnessing adversarial examples. In ICLR, 2015.
- Black-box adversarial attacks with limited queries and information. In ICML, 2018.
- Referitgame: Referring to objects in photographs of natural scenes. In EMNLP, 2014.
- Align before fuse: Vision and language representation learning with momentum distillation. In NeurIPS, 2021.
- Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In ICML, 2022a.
- Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In ICML, 2023.
- Referring transformer: A one-step approach to multi-task visual grounding. In NeurIPS, 2021.
- Backdoor learning: A survey. IEEE Transactions on Neural Networks and Learning Systems, 2022b.
- Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023.
- Visual knowledge graph for human action reasoning in videos. In ACM MM, 2022a.
- Simvtp: Simple video text pre-training with masked autoencoders. arXiv preprint arXiv:2212.03490, 2022b.
- Follow your pose: Pose-guided text-to-video generation using pose-free videos. In AAAI, 2024.
- Towards deep learning models resistant to adversarial attacks. In ICLR, 2018.
- Generation and comprehension of unambiguous object descriptions. In CVPR, 2016.
- OpenAI. Gpt-4 technical report. 2023.
- Kosmos-2: Grounding multimodal large language models to the world. arXiv preprint arXiv:2306.14824, 2023.
- Visual adversarial examples jailbreak large language models. arXiv preprint arXiv:2306.13213, 2023.
- Tbt: Targeted neural network attack with bit trojan. In CVPR, 2020.
- Poison frogs! targeted clean-label poisoning attacks on neural networks. In NeurIPS, 2018.
- Visionllm: Large language model is also an open-ended decoder for vision-centric tasks. In NeurIPS, 2024a.
- Stop reasoning! when multimodal llms with chain-of-thought reasoning meets adversarial images. arXiv preprint arXiv:2402.14899, 2024b.
- Cheating suffix: Targeted attack to text-to-image diffusion models with multi-modal priors. arXiv preprint arXiv:2402.01369, 2024.
- Modeling context in referring expressions. In ECCV, 2016.
- Grounding referring expressions in images by variational context. In CVPR, 2018.
- Theoretically principled trade-off between robustness and accuracy. In ICML, 2019.
- On evaluating adversarial robustness of large vision-language models. arXiv preprint arXiv:2305.16934, 2023.
- Minigpt-4: Enhancing vision-language understanding with advanced large language models. 2023.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.