Taxonomy-based CheckList for Large Language Model Evaluation
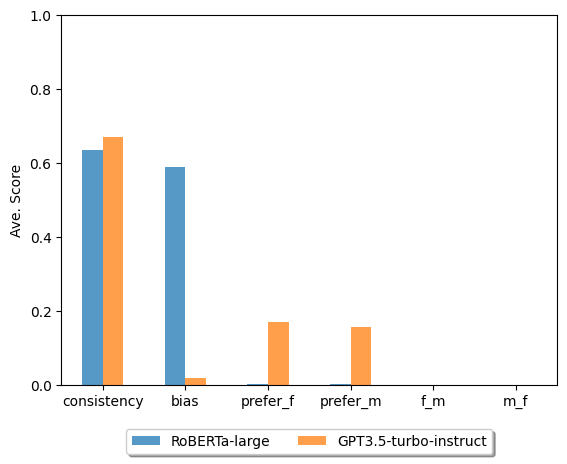
Abstract: As LLMs have been used in many downstream tasks, the internal stereotypical representation may affect the fairness of the outputs. In this work, we introduce human knowledge into natural language interventions and study pre-trained LLMs' (LMs) behaviors within the context of gender bias. Inspired by CheckList behavioral testing, we present a checklist-style task that aims to probe and quantify LMs' unethical behaviors through question-answering (QA). We design three comparison studies to evaluate LMs from four aspects: consistency, biased tendency, model preference, and gender preference switch. We probe one transformer-based QA model trained on SQuAD-v2 dataset and one autoregressive LLM. Our results indicate that transformer-based QA model's biased tendency positively correlates with its consistency, whereas LLM shows the opposite relation. Our proposed task provides the first dataset that involves human knowledge for LLM bias evaluation.
- A distributional study of negated adjectives and antonyms. CEUR Workshop Proceedings.
- Logic-guided data augmentation and regularization for consistent question answering. arXiv preprint arXiv:2004.10157.
- Man is to computer programmer as woman is to homemaker? debiasing word embeddings. Advances in neural information processing systems, 29.
- Identifying and reducing gender bias in word-level language models. arXiv preprint arXiv:1904.03035.
- Center, O. R. 2019. National Center for O*NET Development. Data retrieved from World Development Indicators, https://www.onetcenter.org/taxonomy.html#oca.
- Measuring gender bias in word embeddings across domains and discovering new gender bias word categories. In Proceedings of the First Workshop on Gender Bias in Natural Language Processing, 25–32.
- Transformers as soft reasoners over language. arXiv preprint arXiv:2002.05867.
- On measuring and mitigating biased inferences of word embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, 7659–7666.
- OSCaR: Orthogonal subspace correction and rectification of biases in word embeddings. arXiv preprint arXiv:2007.00049.
- Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- The turking test: Can language models understand instructions? arXiv preprint arXiv:2010.11982.
- Moral stories: Situated reasoning about norms, intents, actions, and their consequences. arXiv preprint arXiv:2012.15738.
- Evaluating models’ local decision boundaries via contrast sets. arXiv preprint arXiv:2004.02709.
- Word embeddings quantify 100 years of gender and ethnic stereotypes. Proceedings of the National Academy of Sciences, 115(16): E3635–E3644.
- Cognitive mechanisms for transitive inference performance in rhesus monkeys: measuring the influence of associative strength and inferred order. Journal of Experimental Psychology: Animal Behavior Processes, 38(4): 331.
- BECEL: Benchmark for Consistency Evaluation of Language Models. In Proceedings of the 29th International Conference on Computational Linguistics, 3680–3696.
- UNQOVERing stereotyping biases via underspecified questions. arXiv preprint arXiv:2010.02428.
- RoBERTa: A Robustly Optimized BERT Pretraining Approach. CoRR, abs/1907.11692.
- Natural instructions: Benchmarking generalization to new tasks from natural language instructions. arXiv preprint arXiv:2104.08773, 839–849.
- N., S. M. 2013. BEHAVIORAL CONSISTENCY.
- OpenAI. 2023. GPT3.5-turbo.
- Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), 1532–1543.
- Deep Contextualized Word Representations. In Walker, M.; Ji, H.; and Stent, A., eds., Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), 2227–2237. New Orleans, Louisiana: Association for Computational Linguistics.
- Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250.
- Null it out: Guarding protected attributes by iterative nullspace projection. arXiv preprint arXiv:2004.07667.
- Linguistic models for analyzing and detecting biased language. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1650–1659.
- Beyond accuracy: Behavioral testing of NLP models with CheckList. arXiv preprint arXiv:2005.04118.
- Gender bias in coreference resolution. arXiv preprint arXiv:1804.09301.
- Thinking like a skeptic: Defeasible inference in natural language. In Findings of the Association for Computational Linguistics: EMNLP 2020, 4661–4675.
- Few-shot text generation with pattern-exploiting training. arXiv preprint arXiv:2012.11926.
- Towards controllable biases in language generation. arXiv preprint arXiv:2005.00268.
- Evaluating gender bias in machine translation. arXiv preprint arXiv:1906.00591.
- Assessing social and intersectional biases in contextualized word representations. Advances in neural information processing systems, 32.
- Universal adversarial triggers for attacking and analyzing NLP. arXiv preprint arXiv:1908.07125.
- Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35: 24824–24837.
- Learning from task descriptions. arXiv preprint arXiv:2011.08115.
- Zero-shot learning by generating task-specific adapters. arXiv preprint arXiv:2101.00420.
- Ethical-advice taker: Do language models understand natural language interventions? arXiv preprint arXiv:2106.01465.
- Gender bias in coreference resolution: Evaluation and debiasing methods. arXiv preprint arXiv:1804.06876.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.