- The paper reveals that minimal model edits can cause catastrophic collapse in LLM performance across diverse tasks.
- It evaluates editing methods like ROME, MEMIT, MEND, and fine-tuning, using perplexity to efficiently detect global degradation.
- The study introduces the HardEdit dataset to benchmark editing challenges and underscores a trade-off between robustness and editing success.
The Butterfly Effect of Model Editing: Few Edits Can Trigger LLMs Collapse
Introduction
This paper presents a systematic investigation into the unintended consequences of model editing in LLMs, specifically the phenomenon termed "model collapse," where even a single edit can precipitate catastrophic degradation in model performance across a range of downstream tasks. The authors demonstrate that state-of-the-art editing algorithms, including ROME, MEMIT, MEND, and fine-tuning with ℓ∞ constraints, are susceptible to this effect, especially when applied to challenging edit cases. The study further proposes perplexity as a reliable surrogate metric for detecting model collapse, validated by strong empirical correlations with downstream task performance. To facilitate future research, the authors introduce the HardEdit dataset, designed to stress-test model editing algorithms.
Model Editing: Methods and Evaluation
Model editing aims to update specific factual knowledge in LLMs by directly modifying model parameters, circumventing the need for full retraining. The paper categorizes existing approaches into three paradigms:
- Fine-tuning: Layer-wise parameter updates with constraints to minimize interference with unrelated knowledge.
- Meta-learning: Hypernetworks predict parameter modifications for new facts, effective for single edits but less robust in sequential settings.
- Locate-then-edit: Based on the key-value memory hypothesis, these methods localize and update parameters associated with target facts, e.g., ROME and MEMIT.
Traditional evaluation metrics such as reliability, generalization, and locality are shown to be insufficient for detecting global model degradation. The locality metric, in particular, fails to capture collapse, as it only assesses changes on irrelevant queries and lacks coverage of the model's full functional spectrum.
Empirical Evidence of Model Collapse
The authors conduct extensive experiments using four editing methods on three open-source LLMs (GPT-2-XL, GPT-J, Llama2-7b) and two benchmark datasets (ZsRE, COUNTERFACT). The results reveal that a single edit, especially on challenging cases from COUNTERFACT, can induce model collapse, characterized by a dramatic increase in perplexity and a precipitous drop in downstream task performance.
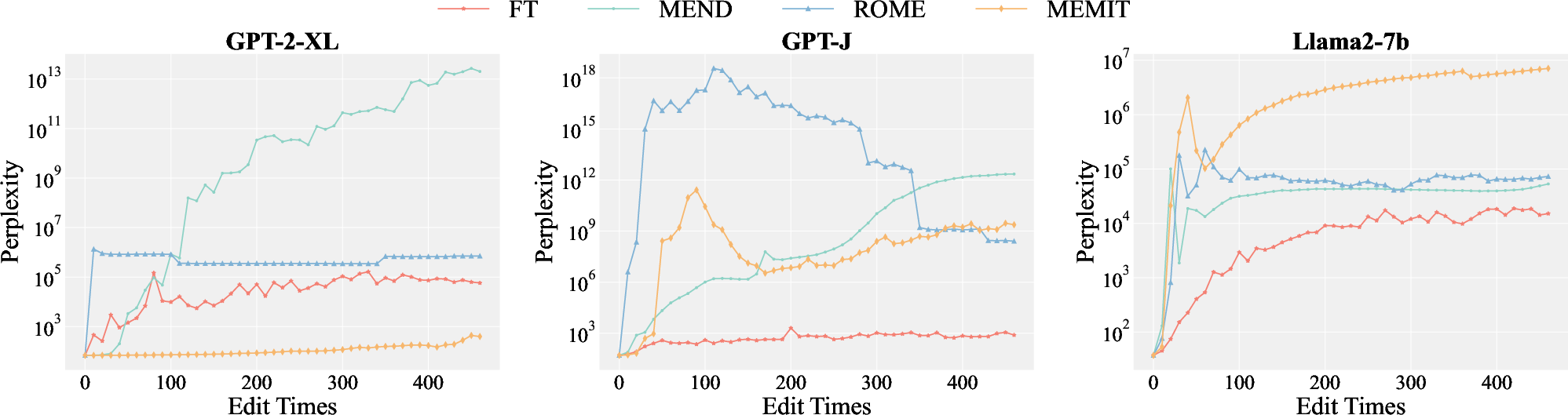
Figure 1: Perplexity in three LLMs, each edited by four different methods sequentially on the HardEdit dataset.
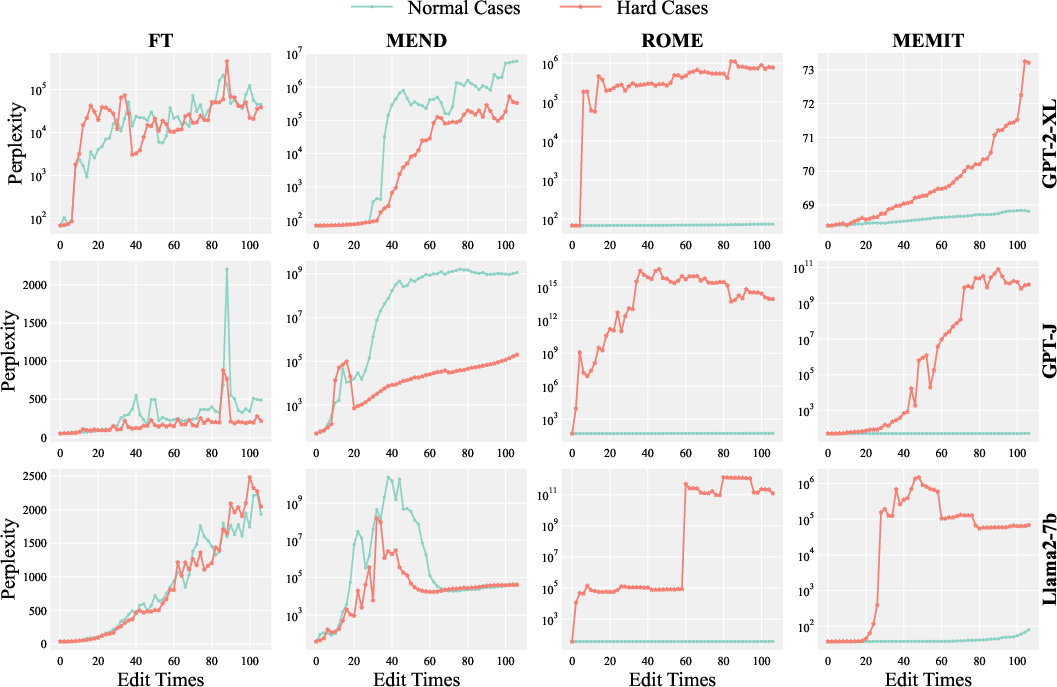
Figure 2: Perplexity evolution over 107 editing iterations for normal and hard cases.
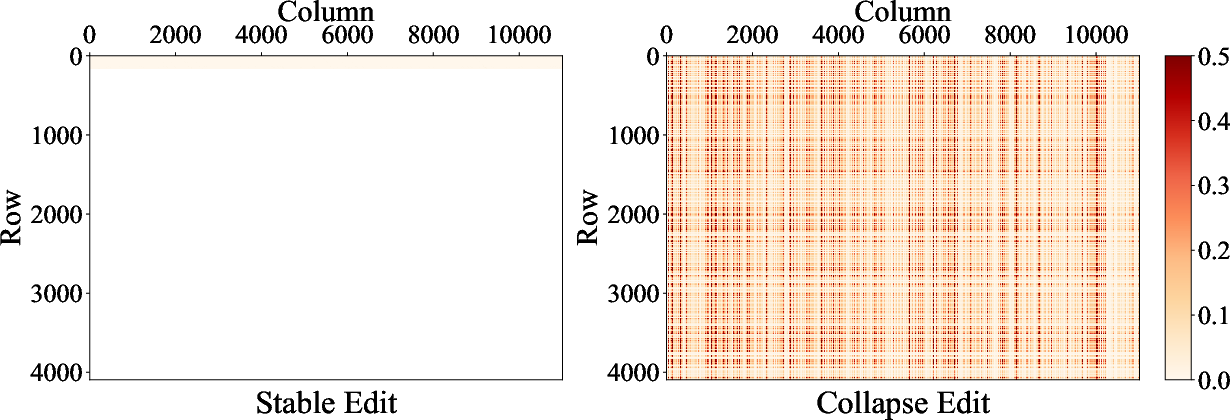
Figure 3: The absolute difference between the weights of the edited layer (Layers.5.mlp.down_proj) and its original weights for ROME-edited Llama2-7b models.
The analysis of parameter changes in collapsed models (Figure 3) indicates that collapse is associated with disproportionately large updates to localized weights, suggesting a breakdown in the locality assumption of editing algorithms.
Perplexity as a Surrogate Metric
To address the impracticality of exhaustive downstream benchmarking after each edit, the paper proposes perplexity on human-written text as a surrogate metric for model integrity. Empirical results demonstrate a strong negative correlation between perplexity and task-specific metrics (accuracy, F1, exact match) across multiple LLMs and tasks.
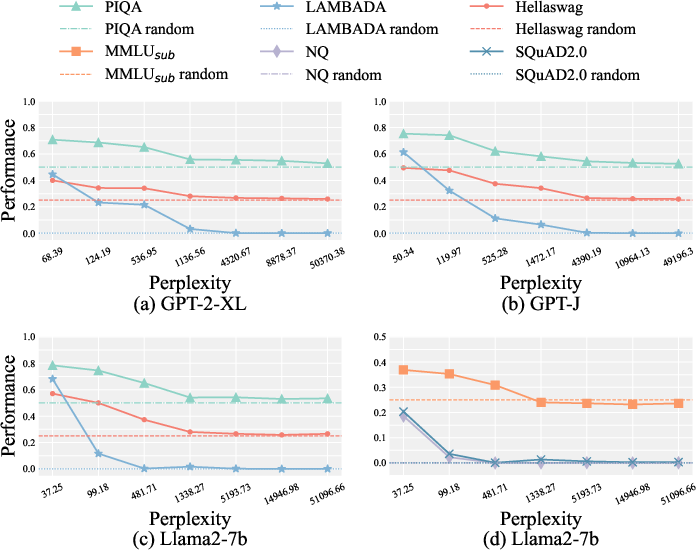
Figure 4: Correlations between perplexity and downstream task performance across different LLMs, measured by task-specific metrics: Exact Match (EM) for NQ; F1 for SQuAD2.0.; accuracy for remaining tasks.
This finding enables efficient monitoring of model health during editing, allowing practitioners to detect collapse without incurring the computational cost of full task evaluations.
Sequential Editing and HardEdit Dataset
Sequential editing, a realistic scenario for continual knowledge updates, is shown to exacerbate the risk of collapse. The authors construct the HardEdit dataset using GPT-3.5 to generate counterfactual samples that are particularly likely to trigger collapse, based on patterns observed in prior hard cases.
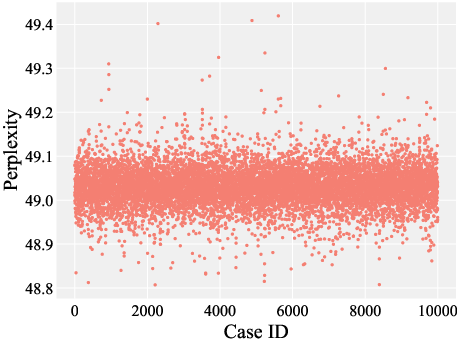
Figure 5: Perplexity values for models on the ZSRE dataset, where each point signifies the perplexity of an individually ROME-edited model based on the original GPT-J model.
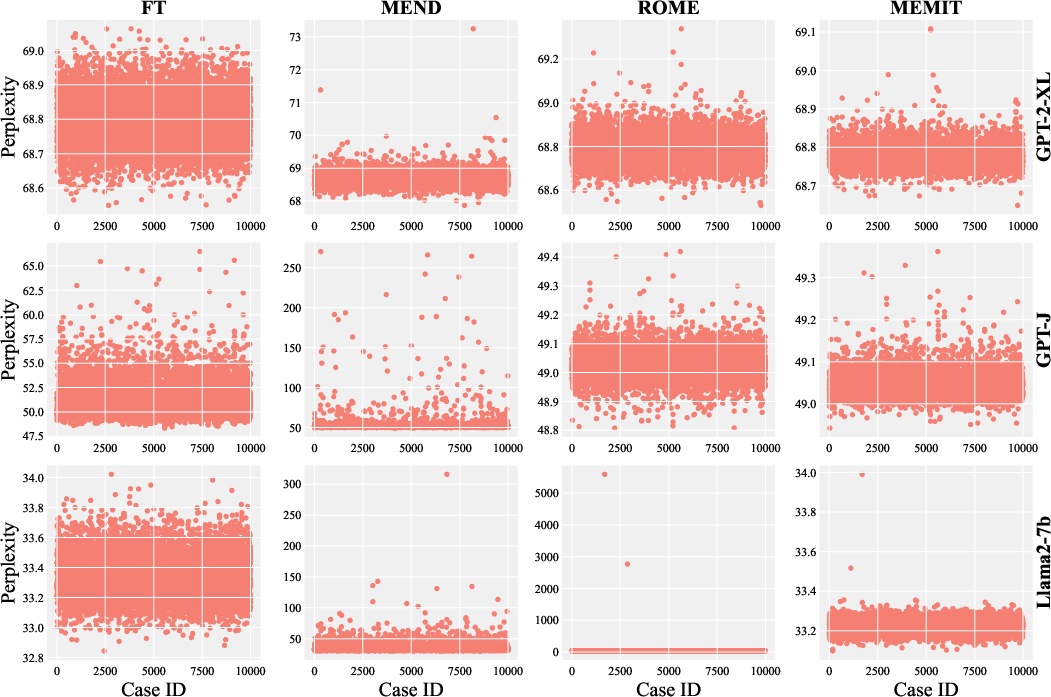
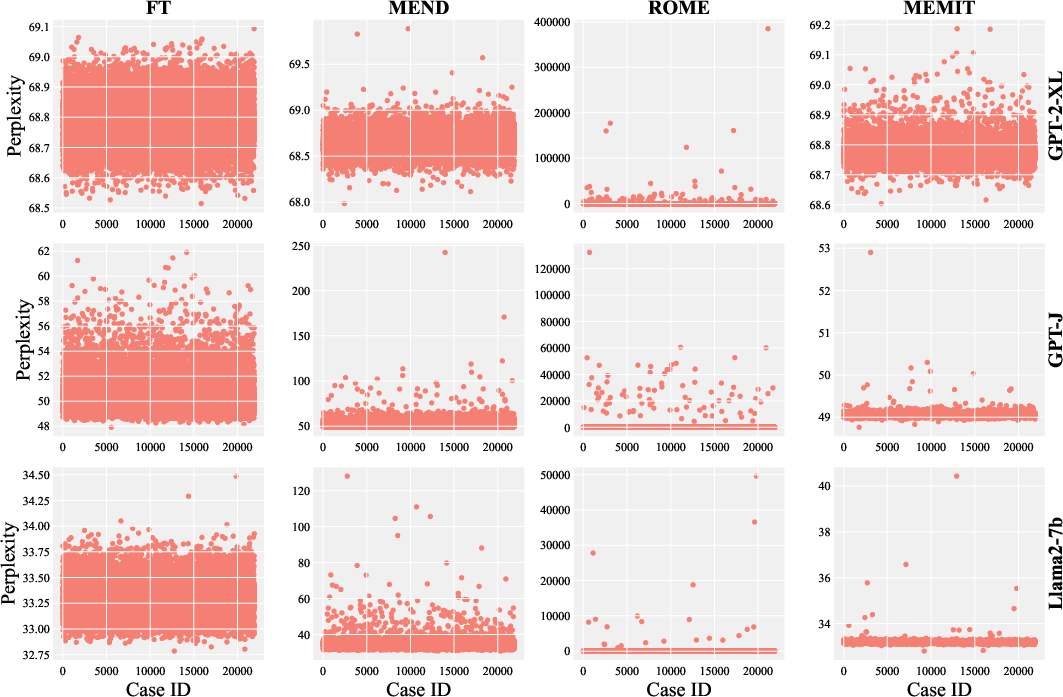
Figure 6: Perplexity results on the ZsRE dataset.
Experiments on HardEdit confirm that nearly all editing methods and LLMs suffer collapse after only a few sequential edits, with perplexity often exceeding 104 and task performance approaching random guessing. Notably, MEMIT avoids collapse in some cases but at the cost of a drastically reduced editing success rate, indicating a trade-off between robustness and efficacy.
Implications and Future Directions
The findings have significant implications for the deployment of model editing in production LLMs. The ubiquity of collapse across methods and models highlights the need for robust editing algorithms that can guarantee preservation of global model capabilities. The use of perplexity as a monitoring tool offers a practical solution for real-time integrity checks during editing workflows.
Theoretically, the results challenge the key-value memory hypothesis underlying locate-then-edit methods, suggesting that factual knowledge may be more diffusely encoded than previously assumed. The observed sensitivity to specific edit cases calls for a deeper understanding of the mechanisms governing knowledge localization and parameter interactions in transformer architectures.
Future research should focus on:
- Developing editing algorithms with explicit safeguards against global degradation.
- Investigating the root causes of collapse, including the role of parameter entanglement and non-local effects.
- Expanding the HardEdit dataset to cover a broader range of challenging edits.
- Exploring alternative metrics and architectures for reliable model editing.
Conclusion
This paper provides a rigorous empirical and theoretical analysis of the risks associated with model editing in LLMs, demonstrating that even a single edit can induce model collapse. The proposed use of perplexity as a surrogate metric enables efficient detection of collapse, and the HardEdit dataset establishes a benchmark for evaluating the robustness of editing algorithms. The results underscore the necessity for caution and further research in the development of reliable model editing techniques for real-world applications.

