- The paper introduces ISSUES, a framework combining CLIP and textual inversion to create enriched multimodal representations for hateful meme classification.
- The method employs linear adaptations and a Combiner network to fuse text and imagery, achieving superior accuracy and AUROC compared to Hate-CLIPper.
- Experimental results confirm ISSUES delivers state-of-the-art performance on Hateful Memes Challenge datasets, highlighting enhanced model generalizability.
Mapping Memes to Words for Multimodal Hateful Meme Classification
Introduction
The task of classifying multimodal hateful memes involves the complex challenge of interpreting the combined meaning of text and images. This paper introduces ISSUES, a method leveraging advanced multimodal techniques to classify hateful content more effectively. ISSUES builds on the CLIP vision-LLM and incorporates the textual inversion technique to create a more robust representation for meme classification.
Proposed Approach
ISSUES leverages a pre-trained CLIP model, which aligns visual and textual data in a common embedding space. This approach is further enhanced with textual inversion, a technique that maps an image into a pseudo-word token in the CLIP embedding space, utilizing the SEARLE textual inversion network for efficient token generation.

Figure 1: Examples of multimodal image-text memes. Given a meme, we want to classify whether its content conveys hate. The proposed ISSUES approach is more effective at evaluating the hatefulness of the memes than the state-of-the-art method Hate-CLIPper.
Textual Inversion Enhancement
By applying textual inversion, ISSUES enriches textual features to include multimodal information within the textual embedding domain. This is achieved by mapping images of memes into pseudo-word tokens that capture both visual and textual semantics, creating a more comprehensive representation.
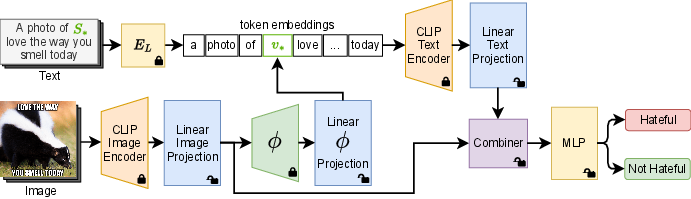
Figure 2: Overview of the proposed approach. We disentangle CLIP common embedding space via linear projections. We employ textual inversion to make the textual representation multimodal. We fuse the textual and visual features with a Combiner architecture.
Disentangling Embedding Spaces
The model employs linear projections to adapt the pre-trained CLIP embedding spaces, allowing separate, task-oriented tuning of image and text features. A two-stage training strategy is used to optimize these projections, ensuring that multimodal representations are effectively disentangled.
Multimodal Fusion Network
The Combiner network is used to fuse the multimodal representations. It takes the adapted visual and textual embeddings and integrates them into a meaningful representation. This fusion is critical for accurately capturing the nuanced interactions between meme text and imagery, facilitating more effective classification.
Experimental Results
The experiments demonstrate that ISSUES exceeds current state-of-the-art performance on the Hateful Memes Challenge and HarMeme datasets. In particular, ISSUES outperforms the widely recognized Hate-CLIPper model, illustrating its superior capability in handling the intricacies of multimodal meme classification.
Quantitative results on the HMC test set:
| Method |
Accuracy |
AUROC |
| CLIP Text-Only |
63.50 |
63.43 |
| CLIP Image-Only |
74.65 |
81.35 |
| ISSUES |
77.70 |
85.51 |
The results from the HarMeme dataset further underscore the model's generalizability, achieving strong performance in real-world, uncurated meme scenarios.
Conclusion
ISSUES presents a robust framework for classifying hateful memes by enhancing the multimodal capabilities of the CLIP model through textual inversion and effective embedding adaptation. Its state-of-the-art performance on challenging datasets confirms the potential of leveraging powerful vision-LLMs and advanced fusion strategies for complex classification tasks. Future research may explore extending these methods to broader multimodal content understanding and further refining model efficiency and deployment capability.