- The paper presents shelLM, a honeypot that uses LLMs to dynamically simulate realistic Linux shell interactions.
- It employs session-based architecture and advanced prompt engineering to maintain state and generate context-aware command outputs.
- Experimental evaluation achieved 92.04% accuracy in deceiving users, demonstrating its potential for adaptive cybersecurity defenses.
LLM in the Shell: Generative Honeypots
Introduction
The paper "LLM in the Shell: Generative Honeypots" (2309.00155) presents shelLM, a novel honeypot system leveraging LLMs to dynamically generate realistic shell environments and command outputs. Traditional honeypots suffer from deterministic responses, limited adaptability, and insufficient realism, making them easily identifiable by skilled attackers. By integrating LLMs, shelLM aims to overcome these limitations, providing a more convincing and interactive deception platform for cybersecurity research and defense.
System Architecture and Prompt Engineering
The core innovation of shelLM lies in its session-based architecture and advanced prompt engineering. Each session maintains state consistency by transferring the session history into subsequent prompts, ensuring continuity and realism across user interactions. The system employs a personality prompt to instantiate the LLM as a Linux terminal, reinforced with chain-of-thought (CoT) and few-shot prompting to guide output fidelity and prevent model disclosure.
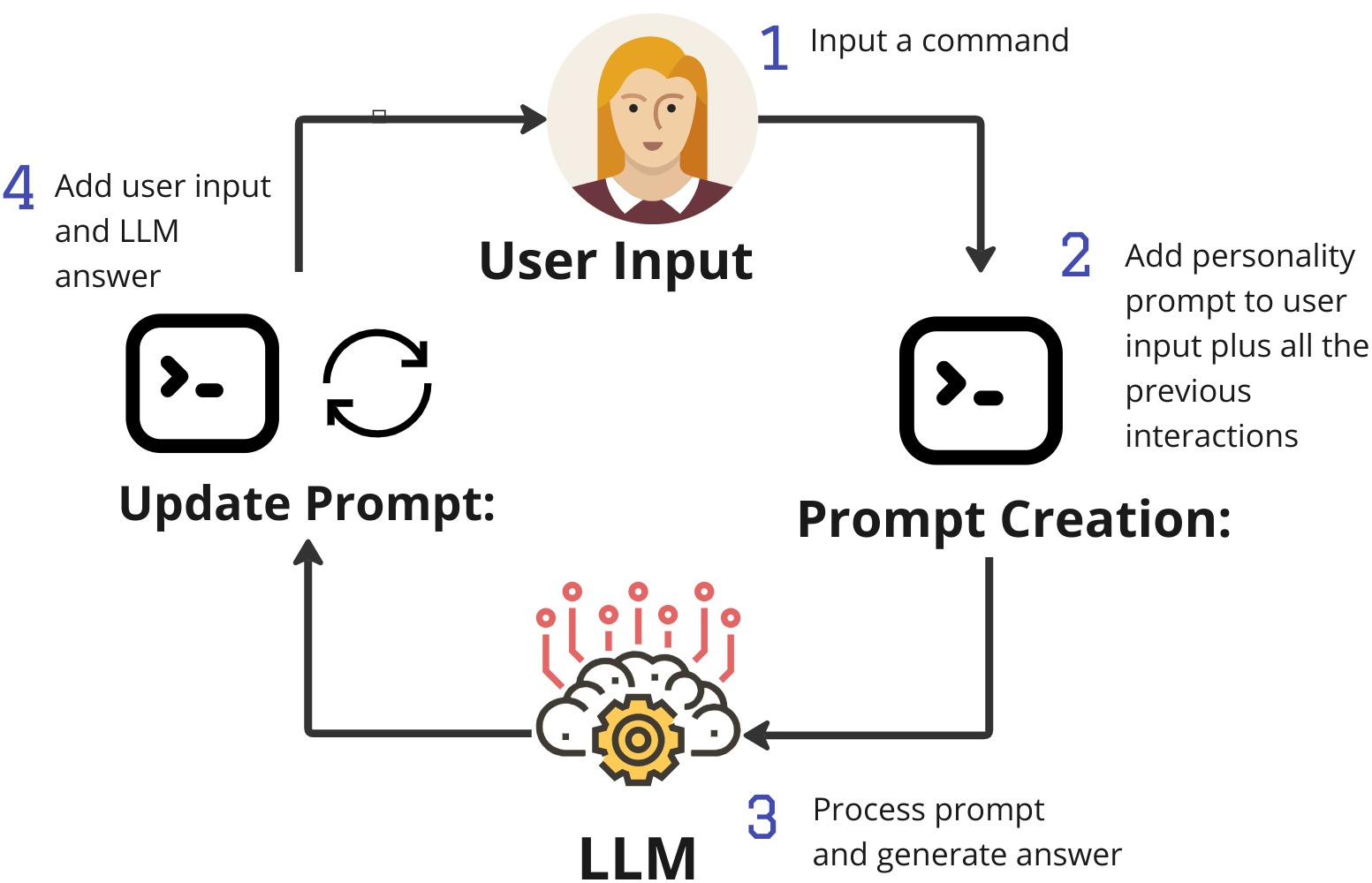
Figure 1: Prompt construction during a shelLM session, illustrating the integration of personality prompt, session history, and user command for each LLM interaction.
The prompt construction process is iterative: user input is appended to the session history, which, together with the personality prompt, forms the input to the LLM. The output is then added to the history, maintaining a coherent and evolving system state. This approach enables the LLM to simulate complex system behaviors, including dynamic file system generation and context-aware command responses.
Realism in Command Output
Empirical demonstrations highlight shelLM's ability to generate credible outputs for a variety of Linux commands. The system was evaluated using GPT-3.5-turbo-16k with deterministic decoding (temperature = 0), ensuring reproducibility and minimizing stochastic artifacts. Outputs for commands such as ping, xinput, and wget were indistinguishable from those of a genuine Linux system, as shown in the following examples.

Figure 2: Example output of a ping command generated by the shelLM LLM honeypot, emulating network diagnostics.
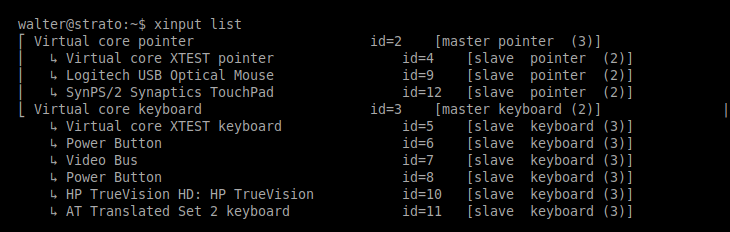
Figure 3: Example output of a xinput command generated by the shelLM LLM honeypot, demonstrating input device configuration simulation.
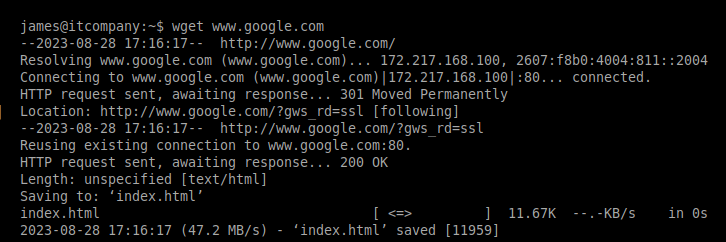
Figure 4: Example output of a wget command generated by the shelLM LLM honeypot, replicating network interactions with external servers.
The system's ability to generate plausible outputs for both common and obscure commands is a direct consequence of leveraging the LLM's extensive pretraining on diverse system logs and documentation.
Experimental Evaluation
The credibility of shelLM was assessed through a human-subject experiment involving 12 participants with varying security expertise. Each participant interacted with a dedicated honeypot instance via SSH, executing a total of 226 commands spanning file management, networking, and system administration. Participants were tasked with identifying outputs that revealed the system as a honeypot.
The evaluation employed a confusion matrix to classify responses as true positives (TP), false positives (FP), true negatives (TN), and false negatives (FN), with expert validation of participant assessments. The key metrics included overall accuracy, false negative rate (FNR), true negative rate (TNR), and false discovery rate (FDR).
The system achieved an overall accuracy of 92.04%, with a TNR of 90.76% and an FNR of 2.32%. Notably, the FDR was 9.23%, indicating that most outputs were not erroneously flagged as honeypot artifacts. Widely used commands such as ls, pwd, and whoami consistently produced credible outputs, while inconsistencies were primarily observed in complex directory structures (e.g., /proc, /etc), attributable to context window limitations and LLM memory constraints.
Cost Analysis
A significant practical consideration is the operational cost of deploying shelLM at scale. The use of GPT-3.5-turbo-16k incurs nontrivial expenses, with an estimated cost of $0.70 per full 16k-token session. The average session cost during experiments was approximately$0.4 per 30 minutes of active use, translating to $0.8 per hour. The majority of the cost is associated with input tokens due to the accumulation of session history. The initial personality prompt alone accounted for 2138 tokens per session.
These costs necessitate careful deployment planning, particularly for large-scale or continuous honeypot operations. Alternative strategies may include prompt compression, selective history retention, or migration to more cost-effective open-source LLMs as they become available.
Limitations and Future Directions
The primary limitations of shelLM stem from LLM context window constraints and occasional output anomalies. As session history grows, relevant information may be lost or diluted, leading to degraded output quality—a phenomenon consistent with recent findings on LLM context utilization. Additionally, response latency is affected by API throughput and model inference time.
Future work will focus on model fine-tuning to enhance long-context retention, reduce behavioral drift, and improve error management. Comparative studies with established honeypots will elucidate the relative effectiveness of LLM-based deception. Further experiments will assess attacker engagement and the system's ability to differentiate between human and automated adversaries.
Conclusion
The shelLM system demonstrates that LLMs can be effectively harnessed to create dynamic, realistic honeypots capable of deceiving human attackers. The integration of advanced prompt engineering and session management yields high-fidelity command outputs, validated by empirical user studies. While operational costs and context limitations present challenges, the approach offers a promising direction for adaptive, interactive cybersecurity defenses. Continued research into model optimization and deployment strategies will be essential for realizing the full potential of generative honeypots in practical settings.

