- The paper introduces a two-field system that splits video content into a canonical content field and a 3D temporal deformation field for enhanced reconstruction fidelity.
- It employs multi-resolution hash tables with efficient MLPs and regularization strategies such as annealed hash encoding and flow-guided consistency loss to ensure semantic precision.
- CoDeF enables applications in video-to-video translation, object tracking, super-resolution, and interactive editing by effectively adapting image processing techniques for video.
CoDeF: Content Deformation Fields for Temporally Consistent Video Processing
The representation of video data has encountered numerous challenges, particularly in maintaining temporal consistency and reconstruction fidelity. The concept of Content Deformation Fields (CoDeF) offers a novel approach, aiming to bridge the gap between efficient video processing and the robust application of established image algorithms. The paper "CoDeF: Content Deformation Fields for Temporally Consistent Video Processing" (2308.07926) introduces a groundbreaking video representation methodology that addresses these core challenges through a two-field system.
Methodology
Canonical Content and Temporal Deformation Fields
The proposed video representation, termed CoDeF, consists of two distinct components: the canonical content field and the temporal deformation field. The canonical field aggregates static contents across an entire video into a 2D framework, optimizing semantic inheritance such as object shapes. The 3D temporal deformation field, conversely, records transformations pertinent to each video frame. Implemented through multi-resolution hash tables facilitated by efficient MLPs, these fields yield a video representation that supports the lifting of image processing algorithms to video processing tasks.
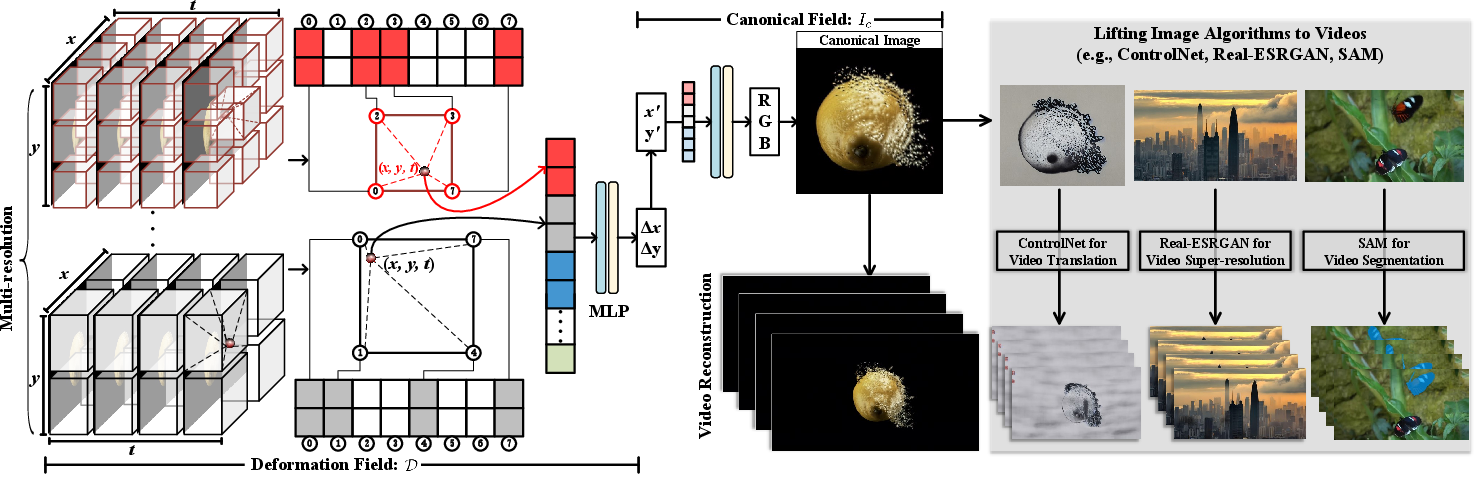
Figure 1: Illustration of the proposed video representation, black, which factorizes an arbitrary video into a 2D content canonical field and a 3D temporal deformation field.
Optimization and Regularization
To achieve maximal reconstruction fidelity and semantic correctness, CoDeF integrates regularization strategies within its optimization pipeline. The training procedure includes annealed hash encoding, fostering a balanced representation between canonical image naturalness and reconstruction fidelity. This is coupled with a flow-guided consistency loss, ensuring the temporal deformation field maintains smoothness across frames.

Figure 2: Ablation study on the effectiveness of annealed hash. The unnaturalness in the canonical image will harm the performance of downstream tasks.
Grouped Content Deformation Fields
For complex scenarios involving multiple overlapping objects or significant occlusions, CoDeF incorporates semantic masks, facilitating enhanced object separation and deformation modeling. This grouped field technique further refines the canonical and deformation fields' robustness, ensuring accurate video reconstruction.
Applications
Video-to-Video Translation
The primary application of CoDeF is in video-to-video translation, leveraging ControlNet for prompt-guided transformations. CoDeF supports high-fidelity output and temporal consistency, outperforming traditional methods like Text2Live and diffusion-based video translation approaches.

Figure 3: Qualitative comparison on the task of text-guided video-to-video translation across different methods.
Video Object Tracking and Super-Resolution
CoDeF enables seamless lifting of image algorithms to video contexts. Utilizing SAM for segmentation and R-ESRGAN for super-resolution, the framework effectively propagates processing across video frames, ensuring high-quality, consistent outputs.

Figure 4: Video object tracking results achieved by lifting an image segmentation algorithm.

Figure 5: Video super-resolution results achieved by lifting an image super-resolution algorithm.
User-Interactive Video Editing
Notably, CoDeF permits user interactive video editing, allowing modifications to a single canonical image to be translated throughout the video sequence with temporal consistency.

Figure 6: User interactive video editing achieved by editing only one image and propagating the outcomes along the time axis.
Implications and Future Directions
The introduction of CoDeF represents a significant stride in achieving temporally consistent video processing. This methodology offers implications for enhancing real-time video editing tools and developing efficient video communication technologies. The prospect of expanding CoDeF toward feed-forward implicit fields and integrating 3D priors marks a promising trajectory for future research.
In conclusion, CoDeF delineates a pivotal framework that empowers video content to leverage sophisticated image processing algorithms, setting a foundation for continued innovation in temporally coherent video synthesis and editing.

