Trace Anything: Representing Any Video in 4D via Trajectory Fields
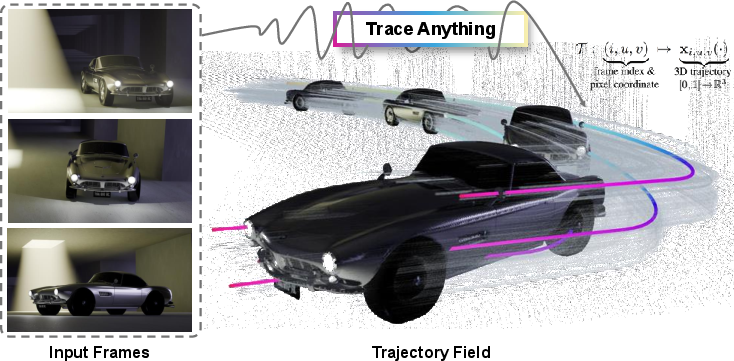
Abstract: Effective spatio-temporal representation is fundamental to modeling, understanding, and predicting dynamics in videos. The atomic unit of a video, the pixel, traces a continuous 3D trajectory over time, serving as the primitive element of dynamics. Based on this principle, we propose representing any video as a Trajectory Field: a dense mapping that assigns a continuous 3D trajectory function of time to each pixel in every frame. With this representation, we introduce Trace Anything, a neural network that predicts the entire trajectory field in a single feed-forward pass. Specifically, for each pixel in each frame, our model predicts a set of control points that parameterizes a trajectory (i.e., a B-spline), yielding its 3D position at arbitrary query time instants. We trained the Trace Anything model on large-scale 4D data, including data from our new platform, and our experiments demonstrate that: (i) Trace Anything achieves state-of-the-art performance on our new benchmark for trajectory field estimation and performs competitively on established point-tracking benchmarks; (ii) it offers significant efficiency gains thanks to its one-pass paradigm, without requiring iterative optimization or auxiliary estimators; and (iii) it exhibits emergent abilities, including goal-conditioned manipulation, motion forecasting, and spatio-temporal fusion. Project page: https://trace-anything.github.io/.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Trace Anything: Representing Any Video in 4D via Trajectory Fields”
Overview
This paper introduces a new way to understand videos called a “Trajectory Field.” Instead of just looking at each frame separately, it treats every tiny dot in a video (every pixel) as if it follows a path in 3D space over time. The authors build a model, called Trace Anything, that predicts these 3D paths for every pixel in a single go. This helps computers better understand how things move and change in videos.
Objectives
The paper focuses on simple, practical goals:
- Create a clear, consistent way to represent any video in “4D” (3D space + time) by giving each pixel a 3D path it follows over time.
- Predict all these paths fast, in one pass, without using extra tools like optical flow or depth estimators.
- Make the system work on regular videos, pairs of images, and even unordered photo collections.
- Improve accuracy and speed on tasks like tracking points and understanding dynamic scenes.
How It Works (Methods and Key Ideas)
To make the ideas easier to imagine, think of this analogy: each pixel is like a tiny sticker attached to something in the scene. As the video plays, that sticker moves through space, leaving a trail. The Trajectory Field stores that trail for every pixel.
Here are the core ideas explained simply:
- 4D representation: “4D” means 3D position over time. So the system figures out where each pixel’s sticker is in 3D at any moment.
- Parametric curves (B‑splines): Each pixel’s path is a smooth curve shaped by a small set of “control points.” Think of control points like pegs that guide the curve, similar to flexible train tracks that bend around pegs.
- Single-pass model: The model, Trace Anything, looks at all input frames once and directly predicts the control points for every pixel. This is like reading a comic book and immediately summarizing where every character moves across all panels in one shot.
- World coordinates: The model puts all paths into the same shared 3D space, so movements line up correctly no matter which frame you start from.
- Training with smart rules:
- Trajectory accuracy: Penalize differences between predicted positions and ground-truth positions at each time.
- Confidence weighting: The model also predicts how sure it is; less certain points count less during training.
- Static regularization: If something doesn’t move, its path should collapse to a single place (no jitter).
- Rigidity regularization: For solid objects, distances between points on the object should stay the same as it moves.
- Correspondence regularization: The same physical point seen in different frames should share the same trajectory.
To train and test the system, the authors built a large synthetic data platform in Blender. It generates realistic videos with detailed ground truth (like exact 3D positions over time), which makes training stable and fair.
Main Findings and Why They Matter
The authors report several important results:
- Strong accuracy: On their new “trajectory field” benchmark, Trace Anything achieves state-of-the-art results, and it performs competitively on well-known point-tracking tests.
- Big speed gains: Because it predicts everything in one pass and avoids slow per-scene optimization, it runs much faster than many existing methods.
- Works on diverse inputs: It handles normal videos, image pairs (start + goal), and even unordered photo sets.
- Emergent abilities:
- Goal-conditioned manipulation: Given a “start” image and a “goal” image (like a robot arm before and after moving an object), it predicts reasonable in-between 3D motion for the arm and objects.
- Motion forecasting: Because trajectories are smooth curves, you can extend them a little into the future (like continuing along the curve’s tangent) to predict what happens next.
- Spatio-temporal fusion: It can gather and align information about a moving thing from different frames back into one reference frame, helping you see a complete, unified picture.
These results matter because they show a more direct, compact way to understand video motion that’s both accurate and efficient. It can replace complex pipelines that stitch together many separate tools.
Why This Matters (Impact)
This approach could make a big difference in areas where understanding motion is key:
- Robotics: Plan movements from video (e.g., move a robot arm smoothly from start to goal).
- AR/VR and video editing: Reconstruct motion in 3D to create effects, merge views, or edit scenes more easily.
- Sports and science: Analyze how people, animals, or objects move in precise 3D over time.
- 3D reconstruction and animation: Use trajectory fields to initialize or improve dynamic 3D models.
By releasing the code, model weights, and data platform, the authors make it easier for others to build on their work. Overall, Trace Anything offers a clean, fast, and general way to represent any video as 3D motion over time, opening the door to better motion understanding and more powerful video-based applications.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of gaps and unresolved questions that, if addressed, could strengthen the work and guide future research.
- Real-world generalization: The model is trained primarily on synthetic Blender and Kubric data, with limited quantitative evaluation on real videos (e.g., DAVIS is used only qualitatively). How well do trajectory fields transfer to diverse real-world conditions, and what domain adaptation or mixed real+synthetic training strategies are needed?
- Metric scale and world coordinates: The paper claims prediction in a shared world coordinate system, but for monocular inputs the absolute scale is inherently ambiguous. How is metric scale established without external calibration, and how does the model behave when scale is unknown or variable across sequences?
- Camera calibration assumptions: Intrinsics, lens distortion, and rolling-shutter effects are not explicitly modeled or estimated. What is the impact of unknown/incorrect intrinsics and non-ideal camera characteristics on trajectory accuracy, and can the model jointly learn intrinsics and poses?
- Timestamp estimation reliability: The timestamp head is introduced for cases without metadata, but its accuracy and failure modes are not quantitatively assessed. How robust is temporal parameter estimation in unordered or sparsely sampled image sets, and can the model recover temporal order in fully unstructured collections?
- Occlusion and visibility modeling: The training masks out invalid pixels (Ω), but the method does not explicitly model visibility, disocclusions, or birth/death of points. How can visibility be estimated and incorporated (e.g., with learned occlusion masks) to avoid hallucinated correspondences across long occlusions or object entrances/exits?
- Topological changes and multi-valued correspondences: The single-trajectory-per-pixel assumption may break for fluids, fractures, object splitting/merging, or severe self-occlusions. How can the representation be extended to handle point birth/death, branching trajectories, or multi-valued mappings over time?
- Adaptive trajectory parameterization: The method fixes cubic B-splines with clamped knots and a global number of control points D. Can knot positions, spline degree, and D be learned per pixel/region to better capture abrupt motions, variable speeds, and complex non-rigid deformations?
- Temporal parameterization and speed: Trajectories are parameterized over normalized time t∈[0,1] with (likely) uniform knots. Would learning non-uniform time-warping or arc-length parameterization reduce error for highly non-uniform motion?
- Regularization dependencies on labels: Static and rigidity regularizations require segmentation or rigidity labels (available in synthetic data). How can these constraints be relaxed or self-supervised for real-world training where such labels are unavailable or noisy?
- Correspondence supervision source: The correspondence regularization relies on known cross-frame matches. In real videos, how can reliable correspondences be obtained (e.g., consistency-based self-supervision) without external trackers?
- Uncertainty calibration: The confidence-adjusted loss uses a heteroscedastic formulation, but predictive uncertainty calibration and downstream usage are not evaluated. Are confidences well-calibrated, and can uncertainty be leveraged for selective prediction, filtering, or planning?
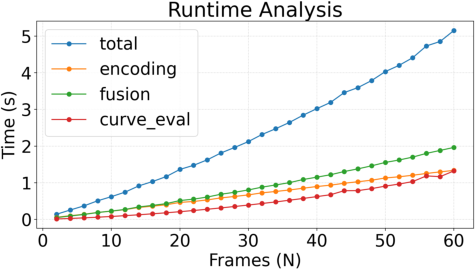
- Scalability to long sequences: Inference subsamples to fewer than 60 frames and scales approximately linearly with frame count. What architectures or streaming strategies enable accurate trajectory fields for hundreds or thousands of frames under memory and latency constraints?
- High-resolution outputs: Training is performed at 512px (longest side). How does accuracy and runtime scale with higher resolutions, and can multi-scale or super-resolution strategies improve fine-grained trajectory fidelity?
- Camera pose estimation in unordered sets: The model reportedly predicts camera poses for unordered collections, but no pose head or quantitative pose evaluation is provided. What is the accuracy of estimated poses, and how are poses jointly optimized with trajectories?
- Evaluation metrics external validity: The proposed SDD and CA are defined on synthetic data. How well do these metrics correlate with performance on downstream tasks (e.g., tracking, reconstruction, manipulation) and in real-world scenes?
- Robustness to challenging imaging effects: Motion blur, rolling shutter, dynamic lighting, specularities, and sensor noise are common in real videos but not explicitly addressed. How robust is the method under these conditions, and can data augmentation or explicit modeling mitigate failures?
- Forecasting beyond short horizons: Velocity-based extrapolation via tangent continuation is shown qualitatively but not evaluated quantitatively. How stable and accurate is long-horizon forecasting, and can learned dynamics models improve extrapolation (e.g., constant acceleration, physics-informed priors)?
- Integration with novel view synthesis: The paper suggests using trajectory fields to initialize dynamic 3DGS/NeRF but does not provide ablations or pipelines. What are effective integration strategies, and do trajectory-initialized NVS models improve rendering quality or speed for dynamic scenes?
- Robotics benchmarks for goal-conditioned manipulation: Results on BridgeData V2 are qualitative. Can predicted end-effector/object trajectories be quantitatively evaluated (e.g., success rate, path feasibility, collision avoidance), and how can control constraints (joint limits, dynamics) be incorporated?
- Cross-video canonicalization: Predictions are in a per-sequence world frame with ambiguous origin and orientation. How can trajectories be canonicalized across videos (e.g., gravity alignment, scale normalization) to enable dataset-level aggregation and comparison?
- Multi-camera and multi-sensor fusion: The approach is demonstrated for single-camera inputs. How can trajectory fields be extended to fuse multi-view, stereo, or event-camera data for improved accuracy and robustness?
- Resource efficiency: Training requires 32×A100 GPUs for >7 days. What model compression, distillation, or efficient attention variants enable similar accuracy on commodity hardware or real-time applications?
- Failure mode analysis: The paper lacks systematic analysis of failure cases (e.g., fast motions, thin structures, heavy occlusions). A taxonomy of failures and targeted remedies (architecture or loss changes) would guide future improvement.
- Data platform coverage and bias: The Blender-based generator’s asset diversity, motion types (e.g., fluids), and lighting/weather conditions may be limited. What content expansions and realism enhancements reduce domain gap, and how do they impact generalization?
- Reproducibility of “emergent abilities”: Capabilities such as instruction-based forecasting rely on external video generation (Seedance 1.0). How reproducible are these results across generators, and can the trajectory model itself learn instruction-conditioned dynamics without external generation?
Glossary
- 3D Gaussian Splatting (3DGS): A rendering technique that represents scenes with 3D Gaussians to achieve fast, high-quality radiance field rendering. "3D Gaussian Splatting (3DGS)~\citep{3dgs} has been extended to dynamics~\citep{wu20234d, yang2023real, luiten2023dynamic, yang2023deformable, li2024spacetime}, improving rendering quality and speed."
- AdamW: An optimization algorithm that decouples weight decay from the gradient update, improving training stability. "using AdamW~\citep{loshchilov2017fixing} with a learning rate of 0.0001 and a cosine annealing schedule."
- All-to-all attention: A transformer mechanism that allows every token to attend to all others across frames, enabling joint multi-frame reasoning. "further relaxed the pairwise assumption with all-to-all attention, enabling joint reasoning over all frames and avoiding pairwise inference."
- Basis functions: A set of functions used to linearly combine control points to form a parametric curve. "Given basis functions , the trajectory is"
- Bézier bases: Polynomial basis functions defining Bézier curves, often used for parametric trajectory representation. "where holds for cubic B-splines with clamped knots or for Bézier bases."
- Bundle adjustment: A global optimization procedure that refines camera poses and 3D structure jointly across views. "feature extraction, image matching, triangulation, relative pose estimation, and global bundle adjustment."
- Canonical frame: A chosen reference frame into which observations from different times are aligned for consistent aggregation. "predicted trajectory fields enable dynamic entities observed across multiple frames to be consistently fused back into a common canonical frame."
- Canonical space: A reference coordinate space to which observations are mapped before modeling deformations over time. "maps observations to a canonical space and models dynamics via deformation fields."
- Camera baselines: The spatial separation between camera viewpoints that affects reconstruction accuracy. "assume static scenes and sufficient camera baselines, leading to degraded performance in dynamic settings."
- Clamped knots: A spline configuration where the knot vector is clamped at the ends to ensure endpoints coincide with control points. "In our implementation, we use cubic B-splines with clamped knots as detailed in \Cref{supp:parametric_curves}."
- Codomain: The target space of a mapping or field to which inputs (from the domain) are sent. "we define a field as a mapping from a domain to a codomain , "
- Confidence adjustment: A training strategy that weights losses by predicted confidence to handle uncertainty. "To account for the varying reliability of predicted trajectories across pixels and control points, we incorporate confidence adjustment."
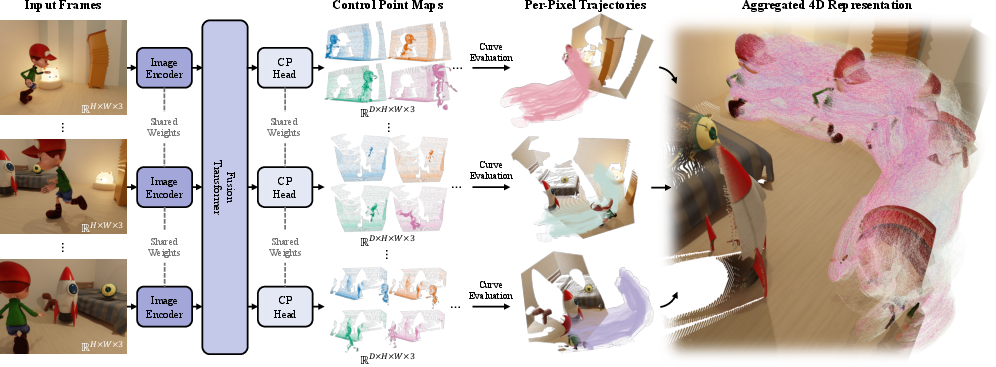
- Control Point Head: A network head that outputs dense control point maps parameterizing trajectories for each pixel. "Built on the backbone features, the control point head outputs dense control point maps for each input frame ."
- Correspondence Agreement (CA): A metric measuring consistency of predicted trajectories across corresponding pixels from different frames. "Correspondence Agreement (CA) measures how consistently dynamic trajectories are predicted from corresponding pixels in different source frames, with lower values indicating better compliance with C2."
- Correspondence regularization: A loss term encouraging matched pixels across frames to share identical control points. "To encourage condition (C2), pixels with known cross-frame correspondences should share identical control points."
- Cosine annealing schedule: A learning rate schedule that decays the rate following a cosine curve to improve convergence. "using AdamW~\citep{loshchilov2017fixing} with a learning rate of 0.0001 and a cosine annealing schedule."
- Cubic B-splines: Piecewise polynomial curves of degree three used to model smooth trajectories with control points. "via cubic B-splines, yielding a 4D reconstruction."
- DeepSpeed ZeRO Stage 2: A distributed training technique that partitions optimizer states and gradients across machines to reduce memory. "and apply DeepSpeed ZeRO Stage 2~\citep{rajbhandari2020zero}, which partitions optimizer states, moment estimates, and gradients across machines."
- Deformation fields: Functions that map points from a canonical space to observed positions over time to model dynamics. "maps observations to a canonical space and models dynamics via deformation fields."
- End-point error (EPE): A metric measuring the Euclidean distance between predicted and ground-truth points, averaged over trajectories. "We evaluate reconstruction accuracy using end-point error (EPE)."
- Feed-forward: A non-iterative inference paradigm where the model predicts outputs in one pass without optimization loops. "we propose Trace Anything, a feed-forward neural network that estimates trajectory fields directly from video frames."
- FlashAttention: An optimized attention algorithm that improves speed and memory efficiency for transformers. "we leverage FlashAttention~\citep{dao2022flashattention,dao2023flashattention} for improved time and memory efficiency"
- Fusion transformer: A transformer module that integrates spatio-temporal context across frames via attention. "followed by a fusion transformer that integrates spatio-temporal context across views through interleaved frame-wise and global attention layers."
- Geometric backbone: The foundational network components focused on geometric reasoning (encoder + transformer) in the pipeline. "We build Trace Anything upon a feed-forward geometric backbone, similar in spirit to recent models~\citep{wang2025vggt, fast3r}."
- Grid-based approaches: Methods that discretize high-dimensional volumes into structured grids to enable efficient representation and rendering. "Grid-based approaches~\citep{cao2023hexplane, kplanes, wang2022fourier, attal2023hyperreel, liu2024gear} discretize the 4D volume into compact planar factors for efficiency."
- Monocular depth estimation: Predicting scene depth from a single camera view. "Unlike prior approaches, our method bypasses monocular depth estimation and 2D trackers and directly predicts dense 3D trajectories in a feed-forward manner."
- Novel view synthesis (NVS): Generating images of a scene from new viewpoints, often requiring dynamic 4D representations. "A large class of 4D representations has been developed for novel view synthesis (NVS) in dynamic scenes, aiming to deliver immersive effects such as “bullet time.”"
- Optical flow: Per-pixel motion vectors in the image plane between frames used to establish correspondences. "relying on optical flow or 2D tracks for cross-frame correspondences"
- Parametric curve: A curve defined by parameters (e.g., time) and basis functions, often using splines or Bézier forms. "The form of the basis functions depends on the type of parametric curve."
- Per-scene optimization: Test-time procedures that optimize model parameters for each scene to align reconstructions globally. "their pairwise inference often requires costly per-scene optimization for global alignment."
- Point cloud: A set of 3D points representing scene geometry, often reconstructed per frame. "produce disjoint per-frame point clouds"
- Pointmaps: Dense per-pixel 3D point predictions aligned to image coordinates. "DUSt3R~\citep{wang2024dust3r} addressed this by directly predicting 3D pointmaps from image pairs."
- Rigidity regularization: A constraint enforcing constant internal distances for pixels within the same rigid segment over control points. "Rigidity regularization. For pixels segmented as belonging to the same rigid region, their trajectories should preserve internal distances across control points."
- Scene flow: The 3D motion field of points in a scene between frames. "For image-pair inference, we compare against the optical flow method SEA-RAFT~\citep{wang2024sea} (lifted to 3D with VGGT~\cite{wang2025vggt}), the scene flow method RAFT-3D~\citep{teed2021raft}"
- Shared world coordinate system: A global coordinate frame in which predictions across frames are jointly expressed. "Predictions are in a shared world coordinate system, with an optional local CP head estimating control points in each frame’s local camera system."
- SLAM: Simultaneous Localization and Mapping, a technique to estimate camera motion and build maps simultaneously. "To handle monocular videos with dynamics, MegaSAM~\citep{li2024_megasam} integrates optimization-based SLAM"
- Spatio-temporal fusion: Aggregating observations across space and time into a consistent representation. "Spatio-temporal fusion. The trajectory field can be leveraged to fuse observations of the dynamic entity across different frames into a canonical frame."
- Spline-based parametric trajectories: Trajectories defined by spline basis functions and control points for smooth 3D motion over time. "defining spline-based parametric trajectories for every pixel."
- Static Degeneracy Deviation (SDD): A metric that quantifies jitter in static-region trajectories to test degeneracy compliance. "Static Degeneracy Deviation (SDD) quantifies the temporal jitter of trajectories in static regions, where smaller values indicate better compliance with C1."
- Static regularization: A loss that encourages control points of pixels in static regions to collapse to overlapping positions. "Static regularization. To encourage condition (C1), pixels in static regions should map to overlapped 3D control points."
- Structure-from-Motion (SfM): A pipeline that reconstructs 3D structure and camera motion from multiple images. "Classical Structure-from-Motion (SfM) pipelines~\citep{hartley2003multiple, agarwal2011building, schonberger2016structure} proceed in sequential stages"
- Tangent continuation: Extrapolating trajectories by extending along their tangents to forecast future motion. "Per-pixel trajectories are extrapolated by tangent continuation, allowing dense motion forecasting without additional predictors"
- Timestamp head: A network component that predicts normalized timestamps when metadata is unavailable. "Otherwise, an auxiliary timestamp head predicts normalized timestamps ."
- Timestamp supervision: A training loss that directly supervises predicted timestamps with ground truth. "When ground-truth timestamps are available, we directly supervise Timestamp Head with an regression loss:"
- Trajectory field: A dense 4D mapping assigning a continuous 3D trajectory over time to every pixel in every frame. "we propose representing any video\textsuperscript{1} as a Trajectory Field: a dense mapping that assigns a continuous 3D trajectory function of time to each pixel in every frame."
- Trajectory loss: The core loss measuring discrepancy between predicted and ground-truth 3D positions evaluated at target timestamps. "We define the loss as"
- 4D correlation volumes: High-dimensional feature correlations across space and time used to improve tracking efficiency. "followed by works~\citep{li2024taptr, cho2024local} that improved efficiency with 4D correlation volumes."
Practical Applications
Immediate Applications
Below are concrete, deployable uses that can be built on the released Trace Anything model, code, and data today (assuming access to a modern GPU and typical video inputs).
- Robotics
- Goal-conditioned manipulation from image pairs
- Use predicted 3D trajectory fields between a start and a goal image to derive feasible end-effector or object motion plans for tabletop manipulation and simple pick-place tasks.
- Tools/workflow: ROS node or MoveIt plugin that ingests two images and outputs a time-parameterized trajectory; validation via simulation (Isaac/Unity) before execution.
- Assumptions/dependencies: monocular scale ambiguity requires an external metric cue (known tool/object size, calibrated camera, or ARUCO markers); scene visibility; GPU for near-real-time inference; safety interlocks for robot execution.
- Dense 3D point tracking for teleoperation, imitation learning, and dataset labeling
- Convert raw RGB streams into consistent 3D trajectories to auto-label demonstrations and learn visuomotor policies.
- Tools/workflow: data loader that writes “Trajectory Field Format” (control-point maps + timestamps) per session; downstream trajectory-to-action mapping (e.g., Track2Act-style).
- Assumptions/dependencies: domain gap from synthetic training to target robot workspace; consistent lighting and texture; camera intrinsics/poses known or estimated.
- Visual effects (VFX), film, and post-production
- Markerless motion and scene tracking for dynamic 3D editing
- Replace labor-intensive rotoscoping and manual tracking with per-pixel 3D trajectories; stabilize, relight, or insert CG assets that remain coherent through occlusions and non-rigid motion.
- Tools/workflow: Nuke/After Effects/Blender add-on to import trajectory fields, warp footage, and anchor assets; batch export as dynamic point clouds.
- Assumptions/dependencies: high-resolution input improves fidelity; metric scale optional; GPU inference; reflective/translucent surfaces may degrade estimates.
- Spatio-temporal fusion for canonical reconstructions
- Aggregate multi-frame observations into a clean, occlusion-free canonical view for asset creation or cleanup (e.g., fusing multiple occluded shots into one complete model).
- Tools/workflow: “Fuse-to-canonical” operator that aligns frames via trajectory fields, outputs a canonical dynamic mesh or time-indexed point cloud.
- AR/VR and creative apps
- Dynamic object anchoring and occlusion-aware overlays
- Anchor virtual content to deforming or moving objects using per-pixel 3D trajectories, improving stability over 2D tracking or per-frame depth alone.
- Tools/workflow: Unity/Unreal plugin that consumes trajectory fields; use cubic B-splines for smooth interpolation between frames.
- Assumptions/dependencies: current model is optimized for offline/near-real-time; mobile deployment needs model distillation or server-side inference.
- Sports analytics and biomechanics
- Automatic player/equipment motion analysis from broadcast video
- Extract 3D trajectories (even with single moving camera) for coaching, performance metrics, and highlight generation.
- Tools/workflow: batch pipeline that ingests game footage, outputs event-aligned 3D trajectories and velocity profiles.
- Assumptions/dependencies: monocular scale needs field/court dimensions; fast motion and motion blur can reduce accuracy; multiple cameras improve robustness.
- Autonomous systems R&D (drones, mobile robots)
- Dynamic 3D scene understanding for research datasets
- Produce dense, temporally consistent 3D tracks for benchmarking perception modules (tracking, forecasting, dynamic mapping) without per-scene optimization.
- Tools/workflow: dataset post-processing tool to augment videos with 3D trajectory annotations; benchmarking harness using paper’s SDD/CA metrics.
- Assumptions/dependencies: real-world generalization for outdoor scenes and rolling-shutter cameras may require fine-tuning.
- Software and 3D content creation
- Initialization of dynamic 3D Gaussian Splatting (3DGS) and NeRF pipelines
- Use trajectory fields to initialize dynamic splats or deformation fields, reducing optimization time and improving convergence in dynamic scenes.
- Tools/workflow: converter that maps per-pixel B-spline control points into time-varying splat primitives.
- Assumptions/dependencies: integration code; consistent camera poses helpful but not strictly required.
- Education and scientific outreach
- Physics labs and classroom demos
- Turn classroom videos into measured 3D trajectories (projectiles, pendulums), demonstrating velocity/acceleration and conservation laws.
- Assumptions/dependencies: scale reference or known baseline for metric outputs; static backgrounds help.
- Security/forensics (analytic support)
- 3D trajectory reconstruction from CCTV footage for incident analysis
- Recover motion paths of people/vehicles to support post-hoc reconstruction.
- Assumptions/dependencies: camera metadata unknown—requires similarity transform alignment; privacy compliance and governance needed.
- Data generation and benchmarks for academia/industry
- Use the released Blender-based platform
- Generate large, diverse synthetic datasets with ground-truth 3D/2D trajectories, depth, semantics for training or evaluating dynamic-scene models.
- Assumptions/dependencies: know-how in Blender scripting; domain randomization for real-world transfer.
Long-Term Applications
These applications are feasible but need further research, scaling, robustness engineering, or multi-system integration (e.g., real-time, metric-scale certainty, regulatory approvals).
- Robotics
- Closed-loop visual whole-body control and loco-manipulation from raw RGB
- Use live trajectory fields for feedback control of mobile manipulators and legged robots in cluttered dynamic environments.
- Potential products: perception-control stack integrating Trace Anything with whole-body controllers, safety fences, and tactile sensing.
- Dependencies: low-latency inference on edge hardware; robust handling of glossy/transparent objects; guaranteed metric scale (sensor fusion with IMU/LiDAR); formal safety validation.
- Instruction-conditioned planning via trajectory fields + generative video
- Chain instruction-to-video models with Trace Anything to propose candidate 3D motion plans given natural language goals.
- Dependencies: reliable generative forecasting; risk-aware selection and verification of generated plans; sim-to-real transfer.
- AR/VR and consumer devices
- Real-time, on-device 4D perception for dynamic occlusion, volumetric telepresence, and 6-DoF video
- Trajectory fields as the backbone for consumer-grade mixed reality that understands and responds to moving scenes.
- Dependencies: model compression/distillation for mobile; multi-camera fusion; privacy-preserving on-device processing.
- Autonomous driving and aerial autonomy
- Integrated dynamic mapping, motion forecasting, and planning
- Replace separate depth/flow/tracking stacks with unified trajectory-field inference; better occlusion reasoning and long-horizon predictions.
- Dependencies: rigorous evaluation under adverse weather/lighting; fusion with radar/LiDAR for metric accuracy; certification and redundancy requirements.
- Healthcare
- Markerless 3D motion capture for rehabilitation and surgical-tool tracking
- Provide dense biomechanical signals from standard OR or clinic cameras.
- Dependencies: regulatory approval; robust operation in sterile, reflective, low-light environments; patient privacy and secure data handling.
- Built environment and digital twins
- Live 4D digital twins of factories, warehouses, and construction sites
- Continuous fusion of dynamic worker/robot/object trajectories into a canonical, queryable model for safety analytics and optimization.
- Dependencies: multi-camera calibration; networked compute; standards for 4D data interchange; worker privacy and labor compliance.
- Media production and virtual production
- End-to-end 4D asset pipelines from casually captured footage
- Turn handheld or crowd-sourced videos into editable dynamic assets without markers or green screens.
- Dependencies: robust multi-view fusion, temporal relighting, material estimation; rights management for user-generated content.
- Public policy and urban planning
- Crowd and traffic flow modeling from city-scale cameras
- Use aggregated trajectory fields to study mobility, safety interventions, and infrastructure planning.
- Dependencies: privacy-preserving analytics (differential privacy, on-device processing), scale to thousands of cameras, standardized governance.
- Scientific computing and environmental monitoring
- Fluid, smoke, and vegetation motion estimation from video for model validation
- Provide dense 3D trajectories as constraints or observations in simulation-in-the-loop workflows.
- Dependencies: domain adaptation for low-texture fluids/gases; multi-spectral inputs.
- Vision foundation models
- 4D pretraining and supervision source
- Use trajectory fields as supervisory signals to train generalist 4D foundation models that unify depth, flow, tracking, and forecasting.
- Dependencies: large-scale real-world 4D datasets; efficient training objectives and architectures.
Cross-cutting assumptions and dependencies
When planning deployments, consider the following common factors that affect feasibility:
- Metric scale and poses
- Monocular inputs often have scale ambiguity; achieving metric accuracy typically needs known camera intrinsics/poses, object size priors, IMU/LiDAR fusion, or multi-view constraints.
- Domain gap and robustness
- The model is trained substantially on synthetic data; performance may degrade with low light, motion blur, reflections/transparency, rolling shutter, or textureless regions; fine-tuning on in-domain data is recommended.
- Compute and latency
- The paper reports fast feed-forward inference (e.g., ~2.3 s for 30 frames on an A100, ~0.2 s for image pairs), which is excellent for offline/near-real-time pipelines; real-time edge deployment will require optimization, quantization, or server offload.
- Data governance and privacy
- Many applications (security, healthcare, urban analytics) require privacy-by-design pipelines, consent, data minimization, and compliance with local regulations.
- Safety and validation
- For robotics and autonomy, incorporate uncertainty estimates (confidence scores in the model), runtime monitors, and fail-safe mechanisms; validate in simulation and controlled trials.
- Interoperability
- Define a storage/exchange specification for trajectory fields (e.g., control-point tensors plus timestamp metadata) and adapters for common engines (ROS, Unity/Unreal, Blender, Nuke).
By aligning these assumptions with the desired sector-specific workflows, organizations can start with immediate, offline uses of trajectory fields and progressively evolve towards real-time, safety-critical, or large-scale deployments.
Collections
Sign up for free to add this paper to one or more collections.