- The paper introduces an invariant-minimum sufficient (IMS) model that addresses distributional shifts in fine-grained visual categorization.
- It employs a novel soft environment partitioning approach by integrating IRM with Information Bottleneck using matrix-based Rényi's α-order entropy.
- Empirical results on seven benchmarks demonstrate that IMS outperforms state-of-the-art methods in mitigating spurious correlations and redundant features.
Summary of "Coping with Change: Learning Invariant and Minimum Sufficient Representations for Fine-Grained Visual Categorization"
Introduction
The paper "Coping with Change: Learning Invariant and Minimum Sufficient Representations for Fine-Grained Visual Categorization" (2306.04893) addresses the challenges inherent in Fine-Grained Visual Categorization (FGVC), particularly focusing on overcoming the limitations posed by distributional shifts between training and test datasets. Previous approaches often assume that the visual features learned by models remain stable and generalizable across different datasets—a condition that is empirically found not always to hold true for FGVC tasks.
The proposed methodology combines Invariant Risk Minimization (IRM) and Information Bottleneck (IB) principles to learn invariant and minimum sufficient (IMS) representations. This dual approach ensures the extraction of features that are both invariant and succinct, thereby enhancing generalization to unseen test data. The methodology introduces a novel "soft" environment partitioning scheme suitable for FGVC tasks alongside the use of matrix-based Rényi's α-order entropy to stabilize IB training.
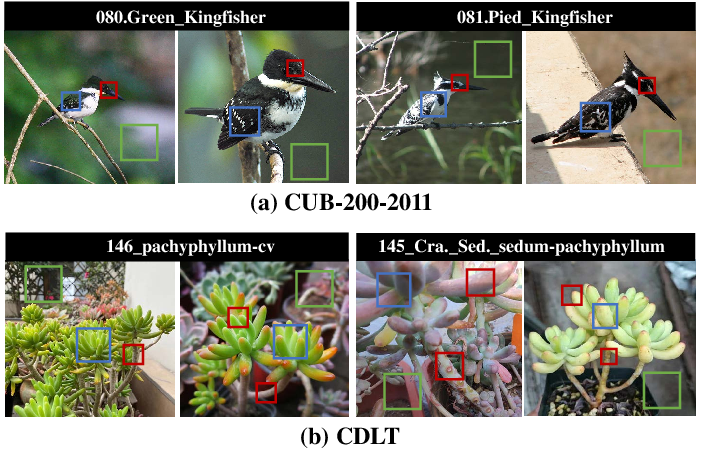
Figure 1: Distributional shift in FGVC leads models to rely on spurious correlations and irrelevant information, with invariant, spurious, and redundant features indicated.
Methodology
Invariant Risk Minimization
IRM is utilized to ensure that the predictor remains invariant across different environments. Formally, IRM seeks an invariant causal predictor by optimizing the risk over multiple environments, constrained to maintain the same predictor under different distributions. The practical application for FGVC, however, requires innovative modifications, as conventional IRM assumes predefined environment partitions which are not available in typical FGVC datasets. This is addressed by using a latent space clustering method to assign instances to environments.
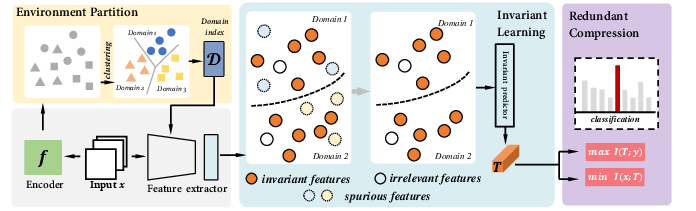
Figure 2: Overview of the proposed method featuring environment partitioning via soft k-means followed by joint IRM and IB training to ensure invariant and minimum sufficiency.
The IB principle compresses learned features to contain just minimal necessary information. In practice, this is challenging with high-dimensional data, necessitating estimators capable of handling mutual information computations. The paper advances this area by applying matrix-based Rényi's α-order entropy functional, facilitating efficient entropy estimation while accommodating minibatch-based optimization.
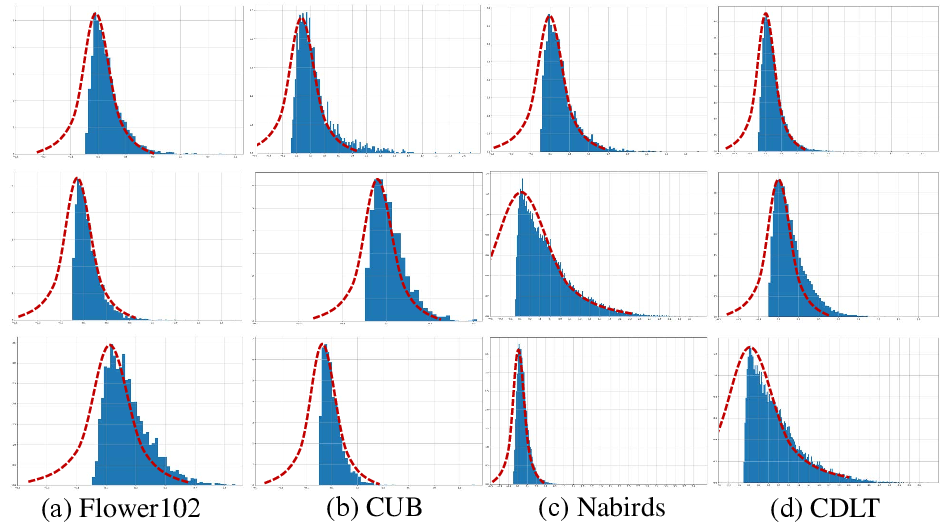
Figure 3: Feature distribution visualization highlights the departure from Gaussian assumptions at the last layer of four datasets.
Experiments
The proposed IMS model outperformed other state-of-the-art approaches across seven benchmark datasets. Notably, IMS displayed robustness and superior performance in scenarios involving distribution shifts—especially prevalent in datasets such as Nabirds and CDLT—demonstrating its effectiveness in learning invariant features. Comprehensive hyperparameter tuning facilitated the model's success; notably, the IMS configuration revealed sensitivity to parameters governing IRM and IB components, guiding optimal settings for trade-offs between risk minimization and feature sufficiency.
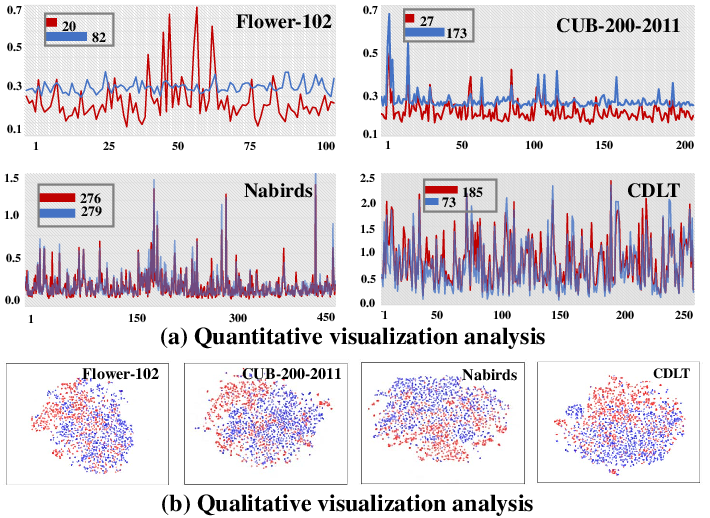
Figure 4: Visualization analysis indicates significant quantitative discrepancies between training and test distributions across multiple datasets, underlining the universal nature of distributional shifts.
Conclusion
The integration of IRM and IB principles in IMS provides a compelling framework for FGVC tasks, simultaneously addressing the challenges posed by spurious correlations and redundant information. Future research may explore extensions of this methodology to cover additional aspects such as explicit environmental indexing and further entropy functional refinements. The IMS's applicability to varied backbone architectures reinforces its potential as a versatile tool for enhancing model generalization under distributional shifts, offering promising directions for practical and algorithmic advancements in AI-driven categorization tasks.
In summary, the paper represents a significant contribution to tackling distributional challenges in FGVC through an information-theoretic lens, offering insights and tools for building more resilient machine learning models.

