- The paper introduces Skill-KNN, a method that improves in-context learning by leveraging task-specific, skill-based descriptions rather than surface-level features.
- It employs a two-stage approach that rewrites inputs into skill-focused representations and retrieves similar examples using cosine similarity of these embeddings.
- Experimental results demonstrate significant gains in semantic parsing accuracy across multiple datasets, outperforming traditional raw-input selection techniques.
Skill-Based Few-Shot Selection for In-Context Learning
In the paper "Skill-Based Few-Shot Selection for In-Context Learning" (2305.14210), the authors propose Skill-KNN, a skill-based selection method designed to enhance in-context learning. This approach specifically addresses the shortcomings of traditional embedding-based selections, which often rely heavily on surface-level natural language features that may not be task-relevant.
Introduction
In-context learning has emerged as a notable paradigm wherein LLMs are adapted to various tasks by providing a few examples without fine-tuning the model's parameters. Selecting the right examples is crucial for optimal performance. Common methods involve embedding raw inputs and finding similar examples based on these embeddings. However, this can lead to bias due to irrelevant features being considered.
Skill-KNN aims to refine this process by creating skill-based descriptions that focus on the relevant task skills rather than surface-level language features. This method is particularly valuable in situations where example banks are frequently updated, as it avoids the need for model retraining or fine-tuning.
Methodology
Skill-KNN's methodology revolves around two main stages. First, it generates skill-based descriptions for each example and test input using predefined annotated demonstrations. This is achieved by prompting an LLM to rewrite an input into a skill-oriented description, focusing solely on the core competencies required for the task (Figure 1).
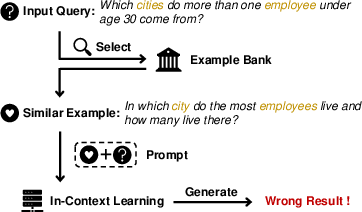
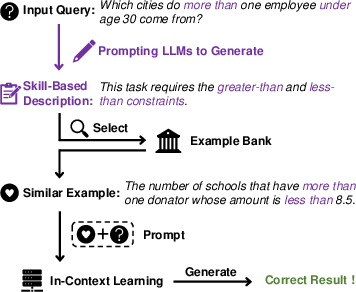
Figure 2: In-context learning with different selection methods. (a) Examples from raw-input-based selection just share similar entities with the input query. (b) With the skill-based description, the selected examples contain the desired task-specific skills.
In the second stage, similar examples are retrieved by embedding the skill-based descriptions and calculating their similarities using cosine similarity measures. Furthermore, the researchers devised two variants of Skill-KNN—consistency-based and distinctiveness-based—that focus on handling order sensitivity and maximizing selection robustness (Figure 3).
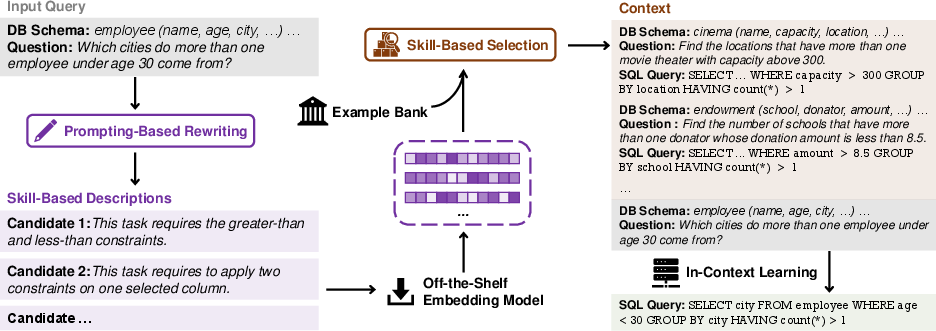
Figure 1: The bird's-eye view of Skill-KNN, a rewrite-then-retrieve selection method to facilitate in-context learning with skill-based descriptions.
Experimental Setup
The efficacy of Skill-KNN is demonstrated through cross-domain semantic parsing experiments across five datasets, including Spider, Dr. Spider, KaggleDBQA, BIRD, and COGS. Performance was measured using execution accuracy on text-to-SQL tasks and exact-match accuracy on COGS, showing substantial improvements over existing methods. For instance, Skill-KNN outperformed raw-input-based selections in many cases, achieving competitive results against oracle methods without relying on ground truth output sequences.
Results and Discussion
The experimental results from Skill-KNN indicate a significant boost in performance across various datasets and models, demonstrating superiority over both training-free and fine-tuning-based methods (Figures 4-5). Key insights include:
- Enhancement of In-Context Learning: Skill-KNN effectively improves the selection process by focusing on intrinsic task-specific skills, resulting in better semantic parsing performance.
- Robustness Against Perturbations: The method maintains high performance across perturbed datasets in Dr. Spider, suggesting robustness against irrelevant language features.
- Effective Variants: The two designed variants help mitigate order sensitivity and enhance selection robustness, showing nuanced differences in performance based on their focus—consistency or distinctiveness.

Figure 3: Two variants of Skill-KNN. The blue and green points represent two candidate sets of skill-based representations.
Conclusion
Skill-KNN offers a promising approach to in-context learning by prioritizing skill-based descriptions, thereby optimizing selection strategies without any requirement for model fine-tuning. This paper highlights its applicability across diverse semantic parsing tasks and underscores its potential for further exploration and extension to other domains requiring in-context learning.
In future work, exploration could include expanding Skill-KNN to tasks beyond semantic parsing, considering task types where surface features are less influential. Additionally, potential improvements in balancing complexity versus simplicity in the selection process could enhance adaptability across varied task requirements.