AdaptMI: Adaptive Skill-based In-context Math Instruction for Small Language Models
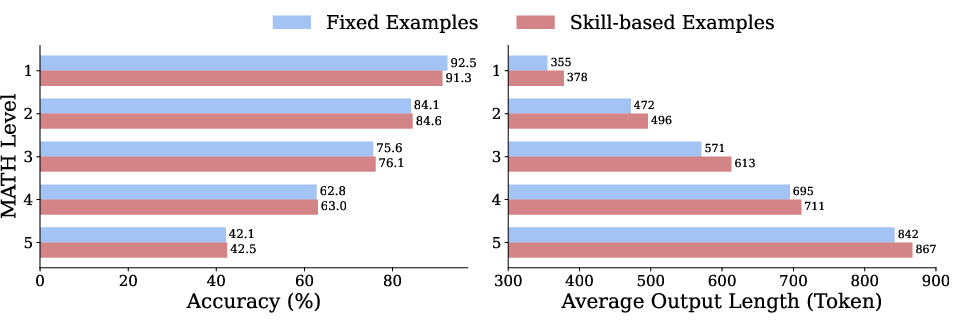
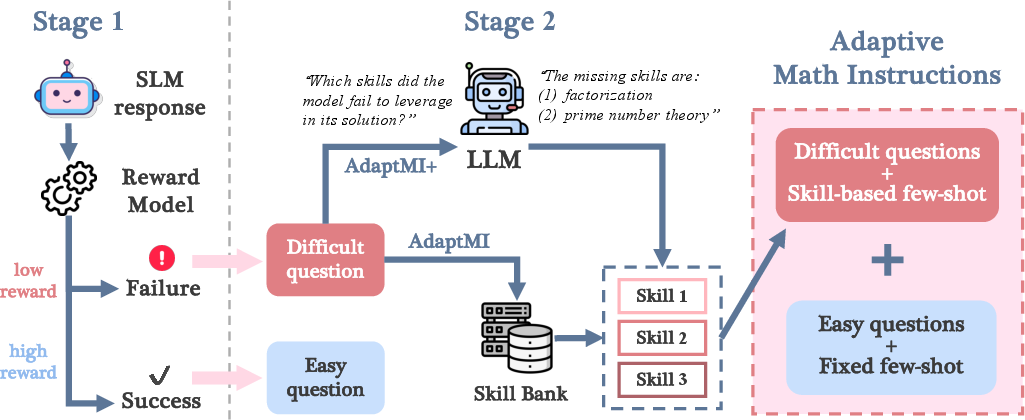
Abstract: In-context learning (ICL) allows a LLM to improve its problem-solving capability when provided with suitable information in context. Since the choice of in-context information can be determined based on the problem itself, in-context learning is analogous to human learning from teachers in a classroom. Recent works (Didolkar et al., 2024a; 2024b) show that ICL performance can be improved by leveraging a frontier LLM's (LLM) ability to predict required skills to solve a problem, popularly referred to as an LLM's metacognition, and using the recommended skills to construct necessary in-context examples. While this skill-based strategy boosts ICL performance in larger models, its gains on small LLMs (SLMs) have been minimal, highlighting a performance gap in ICL capabilities. We investigate this gap and show that skill-based prompting can hurt SLM performance on easy questions by introducing unnecessary information, akin to cognitive overload. To address this, we introduce AdaptMI, an adaptive approach to selecting skill-based in-context Math Instructions for SLMs. Inspired by cognitive load theory from human pedagogy, our method only introduces skill-based examples when the model performs poorly. We further propose AdaptMI+, which adds examples targeted to the specific skills missing from the model's responses. On 5-shot evaluations across popular math benchmarks and five SLMs (1B--7B; Qwen, Llama), AdaptMI+ improves accuracy by up to 6% over naive skill-based strategies.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

