- The paper proposes DiffAVA, a novel framework that integrates visual context with text embeddings for personalized, visually-aligned audio generation.
- It employs a visual-aligned CLAP module and latent diffusion models, demonstrating superior temporal synchronization and fidelity on the AudioCaps dataset.
- Experimental results reveal improved Inception Score and lower KL divergence compared to models like DiffSound and AudioLDM, enhancing multi-modal consistency.
DiffAVA: Personalized Text-to-Audio Generation with Visual Alignment
Introduction
The burgeoning field of Text-to-Audio (TTA) generation hinges on the ability to synthesize audio signals from textual descriptors, a capability rapidly evolving through advancements in machine learning and diffusion models. However, existing methodologies often neglect the critical alignment between audio and video content, resulting in dissonance between generated sounds and corresponding visual stimuli. In response to this gap, the authors present DiffAVA, a novel framework leveraging latent diffusion models to enhance TTA generation by embedding visual alignment into the process.
DiffAVA introduces a multi-faceted approach that incorporates visual context into the generation pipeline, ensuring that synthesized audio not only matches textual descriptors but is also congruent with accompanying visual data. This integration is achieved through fine-tuning visual-text alignment modules, updating text embeddings with visual context, and leveraging these enhanced embeddings as conditions for latent diffusion models.
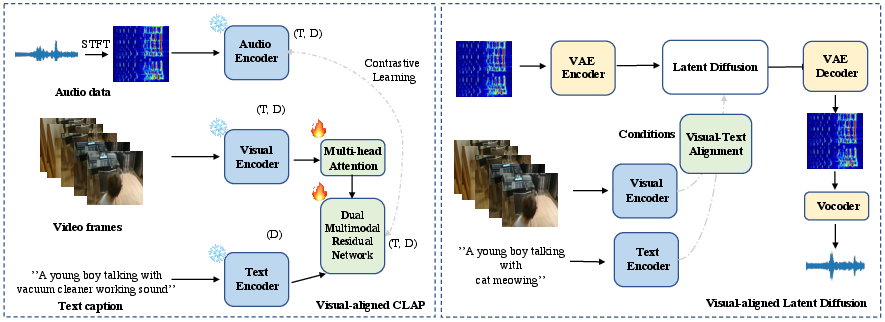
Figure 1: Illustration of the proposed latent diffusion models for personalized Text-to-audio generation with visual alignment (DiffAVA).
Methodology
Visual-aligned CLAP
At the core of DiffAVA is Visual-aligned Contrastive Language-Audio Pre-training (CLAP), an innovative module designed to rectify the traditional approaches' shortcomings by embedding visual content alongside textual information. The process involves a multi-head attention transformer tasked with aggregating temporal data from video features, which are then integrated with text embeddings via a dual multi-modal residual network. This integration crafts visual-aligned text embeddings, forming a basis for subsequent audio generation.
To ensure robust alignment between text, audio, and video, a contrastive learning objective is applied, defined to optimize the alignment between textual features and audio representations. This objective utilizes a batch-wise temporal alignment strategy, reinforcing the cross-modal semantic consistency essential for accurate TTA generation.
Visual-aligned Latent Diffusion
Post visual-aligned CLAP pre-training, DiffAVA employs the refined text embeddings as conditions for latent diffusion models, in particular, tuning only the visual-text alignment modules while relying on frozen modality-specific encoders. This setup expedites the generation process without compromising the personalization and accuracy of the audio synthesis. Notably, DiffAVA capitalizes on the existing latent diffusion models, such as those in AudioLDM, harnessing their proven capabilities while extending them with visual alignment.
Experimental Evaluation
The effectiveness of DiffAVA is substantiated through experiments on the AudioCaps dataset, showcasing its superior performance in generating visually-aligned audio. Quantitative metrics reveal DiffAVA's prowess, particularly its Inception Score (IS) and Kullback–Leibler (KL) divergence, where it surpasses existing models like DiffSound and AudioLDM. These results underscore its ability to synthesize high-fidelity, contextually appropriate audio more aligned with the visual content than predecessors.

Figure 2: Qualitative comparisons with AudioLDM on visual-aligned TTA generation.
Qualitative comparisons further highlight DiffAVA’s capability, where it consistently outperforms AudioLDM by producing audio more accurately timed with visual events depicted in videos. This temporal precision signifies a marked improvement in maintaining synchronization across modalities, a notable advancement in the field.
Conclusion
DiffAVA represents a significant step forward in TTA generation by embedding visual context into the audio synthesis process through innovative application of latent diffusion models. Its framework demonstrates a scalable and efficient approach to combining textual, audio, and visual information, leading to robust and contextually aligned audio outputs. As the landscape of generative models evolves, the principles and methodologies pioneered by DiffAVA are poised to inform future developments, encouraging further exploration into multi-modal synchronization and enriched content generation.