- The paper introduces attentive gating and sample similarity regularization to enhance expert specialization in MoE models, improving overall efficiency.
- It implements an innovative gating mechanism that routes similar and dissimilar samples effectively, addressing issues like module collapse.
- Experimental results on MNIST, FashionMNIST, and CIFAR-100 demonstrate significant performance gains and scalable expert utilization improvements.
Improving Expert Specialization in Mixture of Experts
The paper "Improving Expert Specialization in Mixture of Experts" explores enhancements to the traditional Mixture of Experts (MoE) architecture by focusing on improving expert specialization through novel techniques like attentive gating and sample similarity regularization.
Introduction to Mixture of Experts
Mixture of Experts (MoE) is a modular neural network architecture where several neural networks, termed as experts, are combined using a gating network to collaboratively solve a learning problem. In standard MoE models, the gating network determines the contribution of each expert to the final output. While MoE models offer computational efficiency by only activating parts of the network during inference, challenges such as uneven task decomposition and under-utilization of experts persist.
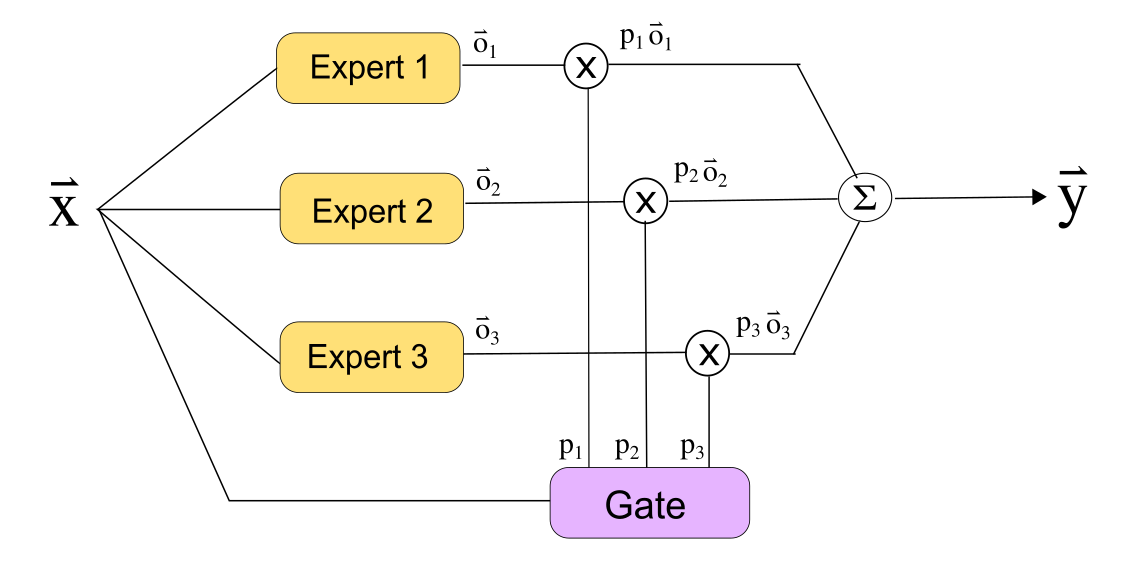
Figure 1: Original Mixture of Experts (MoE) architecture with 3 experts and 1 gate, illustrating traditional task decomposition with potential inefficiencies.
Limitations in Traditional MoE Architectures
The paper identifies significant issues with conventional MoE architectures:
- Task Decomposition: Original MoE models often fail to form intuitive task decompositions, which can lead to inefficient expert utilization. Experiments showcased that for both MNIST and FashionMNIST, experts were not optimally deployed.
- Expert Utilization: The authors demonstrate that training methods can result in only a subset of experts being effectively utilized, adversely impacting performance. This is termed as module collapse when only one expert out of many is utilized, essentially reducing the MoE to a single model.
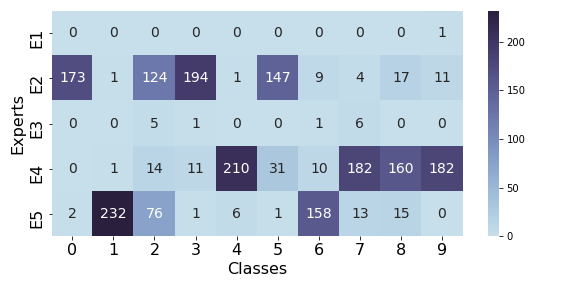
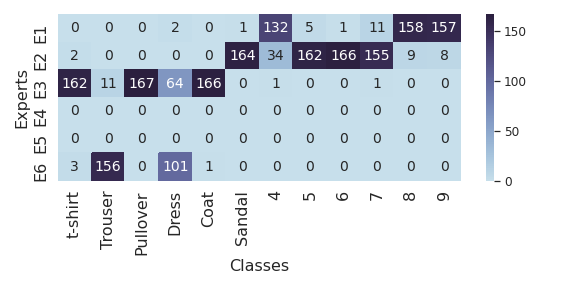
Figure 2: Expert selection table of the original MoE model reveals inefficient and non-intuitive task assignments in MNIST and combined FMNIST datasets.
Novel Contributions: Attentive Gating and Regularization
Attentive Gating Architecture
The authors propose an "attentive gating" mechanism that enhances expert specialization through attention-based techniques analogous to self-attention mechanisms used in NLP. This approach computes gating distributions based on expert outputs, facilitating more informed and balanced expert selections.
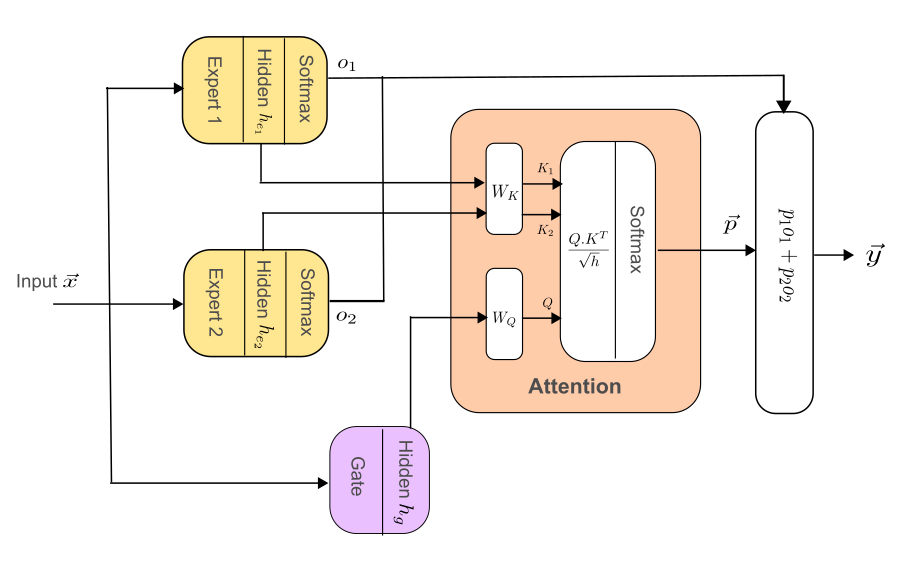
Figure 3: Attentive gating MoE architecture, showcasing the integration of attention mechanisms to refine expert selection.
Sample Similarity Regularization
Recognizing the issue of inequitable expert distribution, the paper introduces a sample similarity-based regularization term, Ls. This regularization function incentivizes routing similar samples to the same expert and dissimilar samples to different experts, fostering better task decomposition.
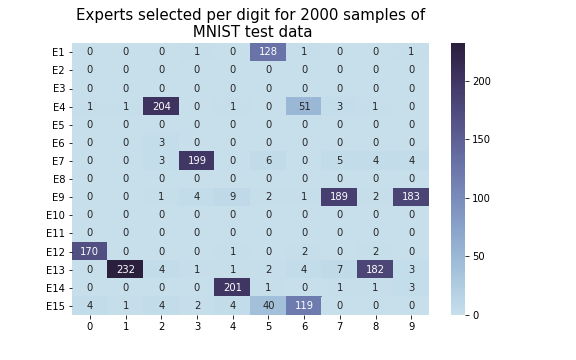
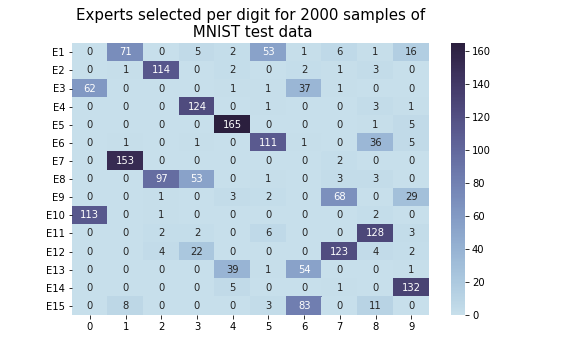
Figure 4: Expert selection table using sample similarity regularization, demonstrating improved expert utilization across tasks.
Experimental Results
Experiments conducted on MNIST, FashionMNIST, and CIFAR-100 datasets reveal that models utilizing attentive gating and sample similarity regularization significantly outperform traditional MoE architectures in terms of both test error rates and efficient expert utilization.
The attentive gating method offers lower entropy in task decomposition without sacrificing performance, while the Ls regularization provides a scalable solution compared to Limportance, especially when handling a larger number of expert layers.
Conclusion
The advancements presented—including attentive gating and Ls regularization—demonstrate significant improvements in expert specialization and efficiency of MoE models. These strategies not only enhance performance metrics but also provide pathways for better scalability and application in multi-modal learning environments. The findings call for further exploration into expert and gate design, opening avenues for future research in adaptive modular architectures.
Overall, these contributions lay a foundation for improved MoE deployment in real-world applications, emphasizing the importance of expert specialization and efficient computational strategies.