- The paper presents a framework using AI assistants to combine automated suggestions with human insights for efficient data cleaning.
- It details interactive methods, such as the datadiff tool in JupyterLab, to iteratively refine data transformations and resolve errors.
- The evaluation demonstrates enhanced accuracy in data handling, highlighting the practical benefits of mixing algorithmic and expert inputs.
AI Assistants: A Framework for Semi-Automated Data Wrangling
The paper "AI Assistants: A Framework for Semi-Automated Data Wrangling" introduces a structured approach to data wrangling by leveraging AI assistants to reduce manual effort in cleaning and transforming data. This framework addresses common challenges faced by data scientists and seeks to enhance productivity by integrating human insights with automated processes.
Introduction to AI Assistants
Data wrangling involves tedious tasks such as merging datasets, transforming formats, and correcting errors. Despite advancements in AI, these tasks are rarely automated due to domain-specific requirements and edge cases best handled with human intuition. The proposed framework introduces AI assistants, interactive tools that balance automated recommendations with human input to effectively manage data wrangling challenges.
Interactive Framework
AI assistants facilitate semi-automatic workflows by recommending data transformations and iterating upon user feedback. This interaction improves results over purely manual or automatic methods. For instance, the datadiff AI assistant used in JupyterLab helps align datasets by suggesting patches that the user can refine interactively. Such an approach allows for correction of algorithmic mistakes through contextual human insights.
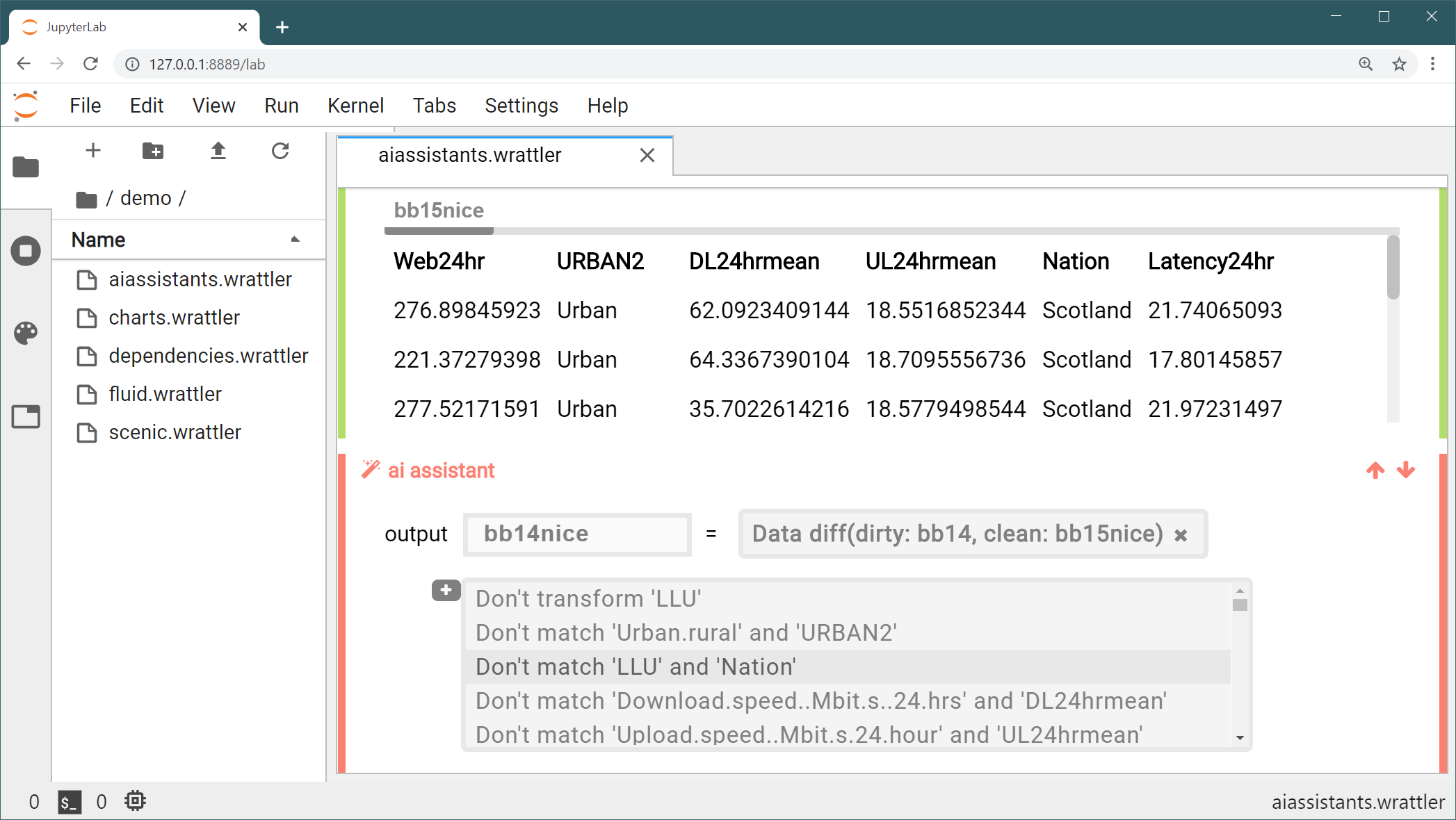
Figure 1: Using the datadiff AI assistant in JupyterLab to semi-automatically merge data from two sources, parsed by an earlier R script.
Theoretical Foundation
The framework defines AI assistants with three operations: f, bestX, and choicesX. The function f(e,X) applies the best cleaning script e to input data X. The operation bestX(H) suggests the most suitable script considering past human interactions H. Finally, choicesX(H) provides a list of options for the user to influence subsequent iterations, thus refining the transformation iteratively.
Optimization Perspective
AI assistants often optimize an objective function QH(X,e), which evaluates how well an expression e transforms input data X given human constraints H. This probabilistic modeling forms the basis for assistants in various domains, including parsing CSV formats and semantic type inference.
Practical Implementations
The framework describes implementations of several AI assistants transforming existing static tools into interactive ones:
- datadiff: Aligns datasets by applying patches such as recoding categorical values or reordering columns. Errors in automatic matching, like mismatched categorical columns, are resolved through user constraints.
- CleverCSV: Parses non-standard CSV files by iterating over potential dialects and incorporating user-specified delimiters or quote characters to ensure accurate parsing.
- ptype: Infers types for data columns in environments with mixed or missing data. User interactions refine type classification, especially for complex types like dates.
- ColNet: Predicts semantic types using knowledge graphs, allowing user guidance to adjust for ambiguities or missing entries.
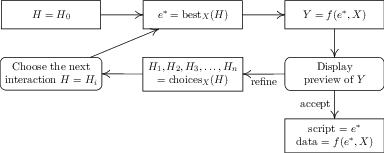
Figure 2: Flowchart illustrating the interaction between an analyst and an AI assistant. Steps drawn as rounded rectangles correspond to user interactions with the system.
Evaluation and Scenarios
The effectiveness of the proposed AI assistants is demonstrated through qualitative scenarios and quantitative measures. For example, in data merging tasks using datadiff, user interactions significantly reduce errors compared to manual edits or static tools. Similarly, CleverCSV and ptype offer robust solutions for format and type inference requiring minimal input from the user.
Conclusion
The framework for AI assistants presented in this paper significantly enhances data wrangling by integrating human expertise into automated processes. This solution addresses the limitations of fully automated tools by promoting a mixed-initiative approach. As the framework is generic and extensible, it promises to tackle a wider range of data challenges and enable more intelligent data management processes in future systems.
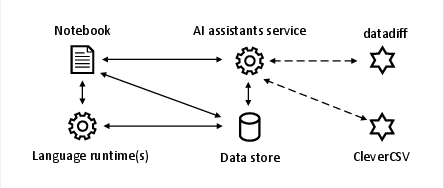
Figure 3: AI assistants in Wrattler (partly adapted from Wrattler framework).

