- The paper presents a novel approach using Video Vision Transformers that leverages spatiotemporal attention mechanisms for enhanced violence detection accuracy.
- It employs tubelet embeddings, frame augmentation, and Transformer layers to efficiently process video data with limited datasets.
- Experimental results on benchmark datasets demonstrate superior performance compared to state-of-the-art methods in detecting violent behavior.
The paper "Video Vision Transformers for Violence Detection" (2209.03561) explores the application of Video Vision Transformers (ViViT) to automate the detection of violent incidents in video sequences. It presents a novel approach based on deep learning that aims to discern violent behaviors in feeds from surveillance systems, aiming to enhance urban safety and prompt law enforcement actions. The approach leverages Transformers' capability to process video data, incorporating spatial and temporal attention mechanisms to improve classification accuracy within smaller training datasets.
Introduction
The prevalence of violent behavior in public spaces is an increasing concern, driving the need for automated surveillance solutions. Traditional systems often fail to provide timely responses to unfolding events, highlighting the importance of developing efficient violence detection systems. This paper introduces a framework using ViViT models, which represent video sequences as spatiotemporal tokens that are processed by a network of Transformer layers.
The framework aims to address shortcomings in traditional computer vision methods by employing the self-attention mechanisms inherent to Transformers. It builds on the initiative of a purely Transformer-based approach, scrutinizing its performance in identifying aggressive behaviors in video sequences.
Proposed Methodology
The proposed solution consists of multiple stages, including pre-processing of video data, augmentation of video frames, and classification using ViViT models.
Pre-processing
Video data are converted into sequences of frames. Each frame is resized to a smaller dimension while maintaining the original aspect ratio. This process ensures computational efficiency and adherence to the representation of key spatial features.
Video Frames Augmentation
To compensate for the lack of inductive biases in Transformers, the paper employs extensive augmentation techniques. This includes operations like random rotation, Gaussian blur, and uniform perturbations, which assist in training models with limited datasets.
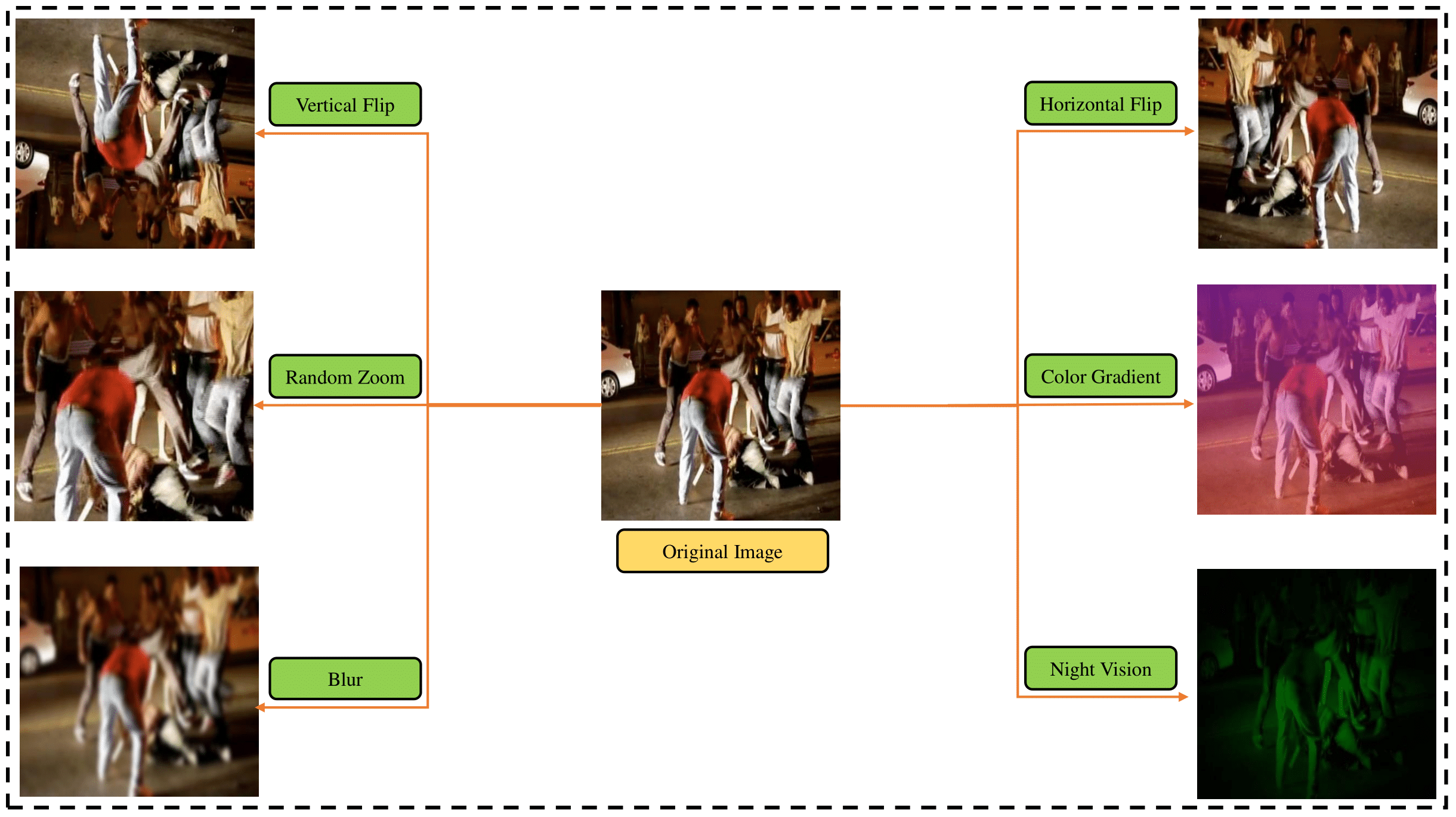
Figure 1: Illustration of single frame augmentation techniques applied to enhance model training.
The paper implements ViViT models by initially embedding video frames into spatiotemporal tokens via tubelet embedding—an approach which segments video frames into small volumes including temporal and spatial slices.
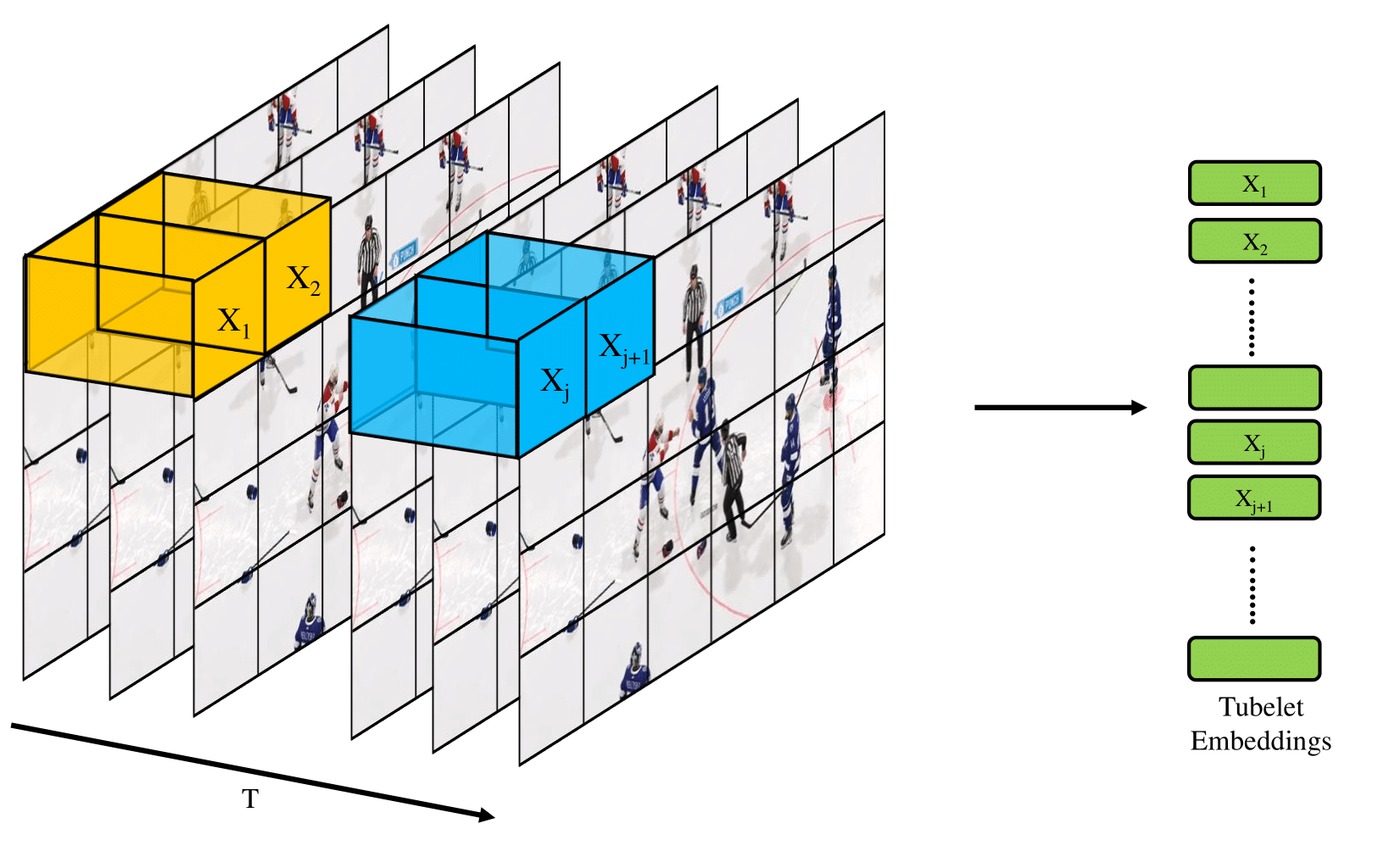
Figure 2: Tubelet embedding method for generating spatiotemporal patches from video frames.
Following embedding, tokens are processed through a series of transformer layers consisting of Multi-Head Self Attention (MSA) and Multi-Layer Perceptron (MLP) blocks, equipped with layer normalization and residual connections.
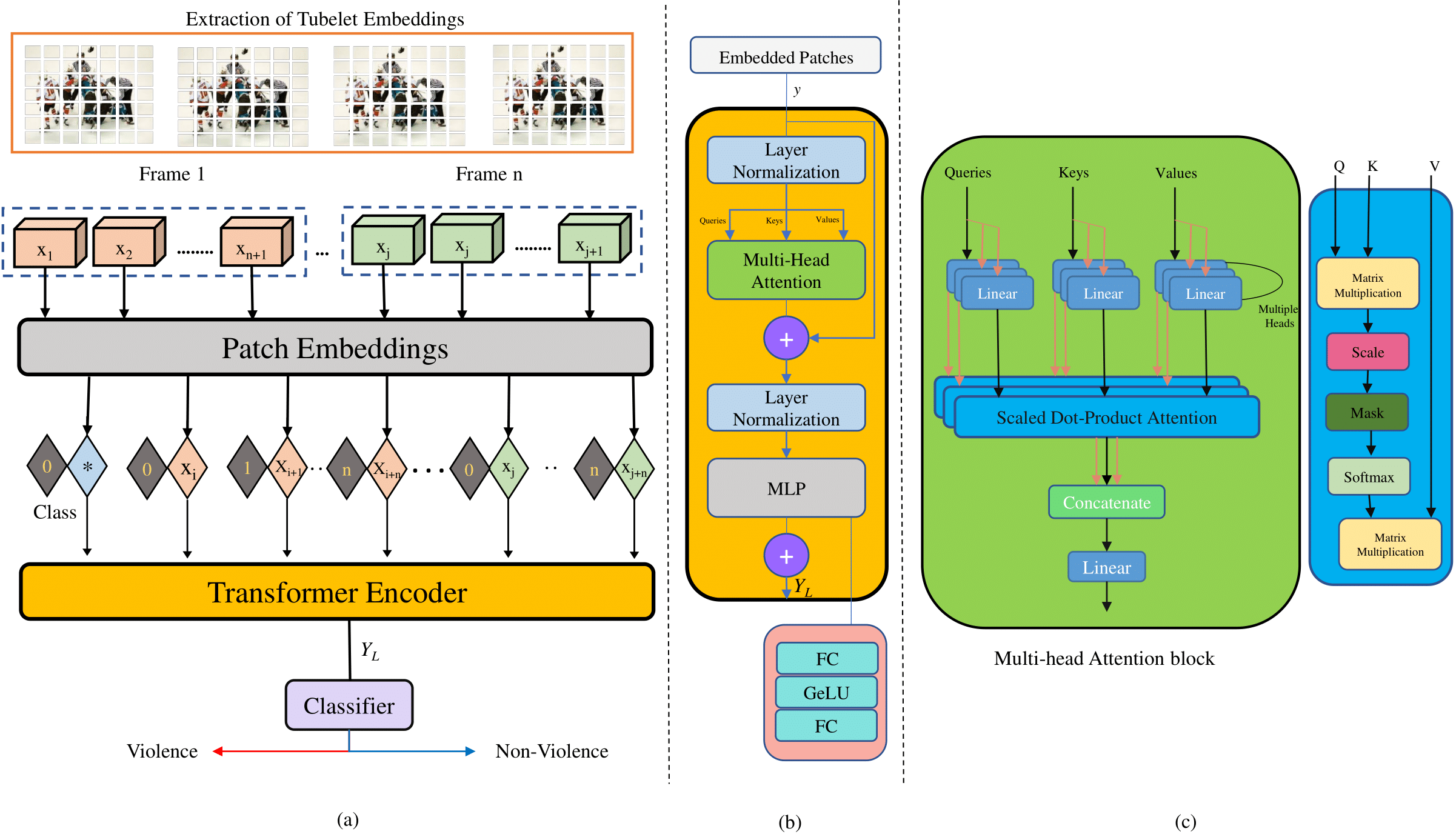
Figure 3: (a) Generation of patch embeddings and conceptual overview of ViViT model (b) Transformer Encoder architecture (c) Multi-head Attention block structure.
Experimental Results
The paper reports experiments conducted on benchmark datasets such as Hockey Fight and Violent Crowd to evaluate the model’s performance. For both datasets, the proposed ViViT framework outperforms state-of-the-art approaches. Specific tuning of hyperparameters such as learning rate, batch size, and patch dimensions contributed to achieving high classification accuracy.
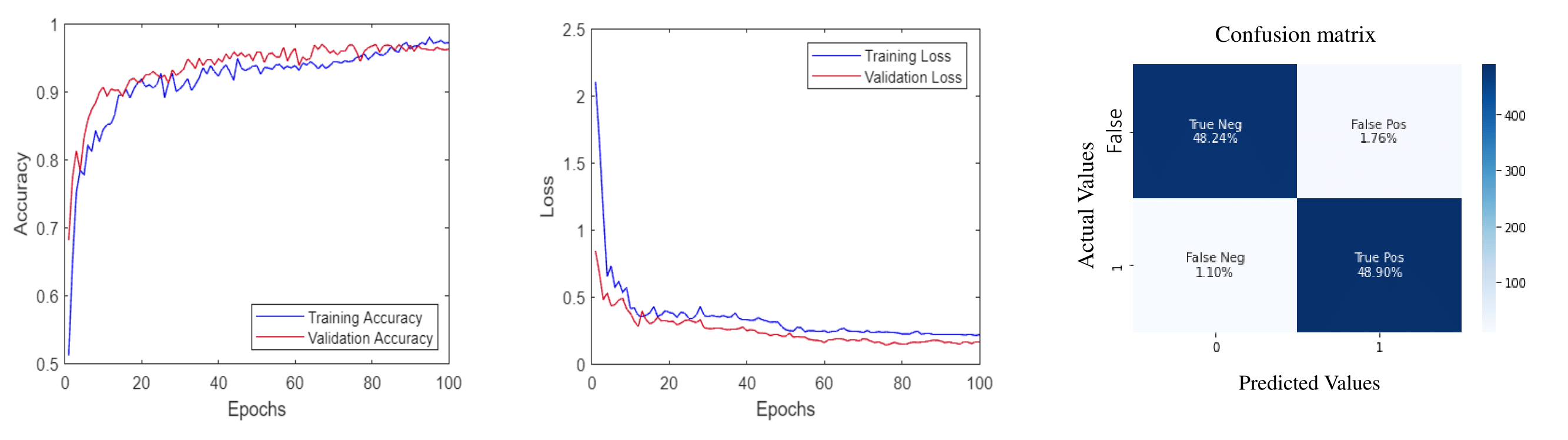
Figure 4: Learning curves of training and validation accuracy and loss for hockey fight and its confusion matrix.
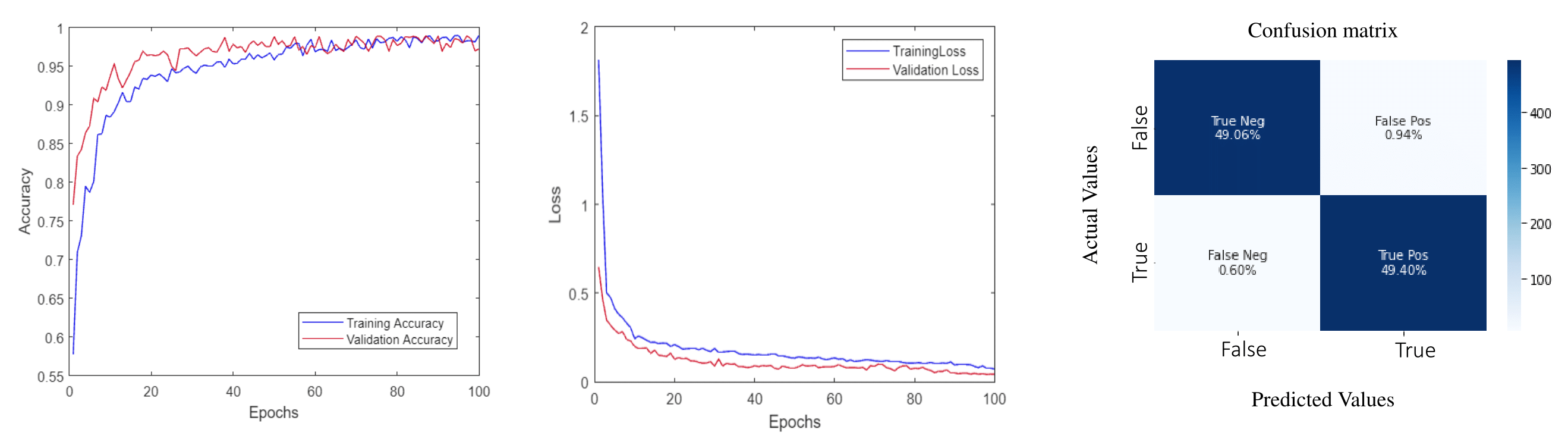
Figure 5: Learning curves of training and validation accuracy and loss for crowd violence and its confusion matrix.
These results underscore the model’s competitiveness over existing methods in terms of both accuracy and robustness across multiple environments.
Conclusion
The paper demonstrates how Video Vision Transformers can become instrumental in the domain of automated violence detection, especially by transforming video data into interpretable spatiotemporal sequences and employing advanced attention mechanisms. Future work involves exploring generative adversarial networks (GANs) for data expansion and testing different ViViT variants for further enhancement in model performance.
This research contributes significant insights into leveraging transformer models for challenging computer vision tasks, positing a scalable approach that can be adapted to extensive surveillance applications.