- The paper introduces a benchmark designed to evaluate long text understanding across domains with tasks like summarization, question answering, and natural language inference.
- It employs a unified text-to-text evaluation format using metrics such as ROUGE, F1, and exact match to standardize performance comparisons.
- Baseline experiments with BART and LED reveal that models benefit from extended context, underscoring the need for specialized transformer architectures.
Introduction
The paper "SCROLLS: Standardized CompaRison Over Long Language Sequences" introduces a new benchmark aimed at addressing a critical gap in NLP—evaluating model performance over long texts. While most existing benchmarks focus on short texts, SCROLLS emphasizes tasks that require reasoning over extended discourses across various domains such as literature, meeting transcripts, and scientific articles. The benchmark is composed of multiple tasks including summarization, question answering (QA), and natural language inference (NLI), specifically curated to challenge current NLP models to handle long-range dependencies effectively.
The SCROLLS benchmark incorporates seven datasets (GovReport, SummScreen, QMSum, Qasper, NarrativeQA, QUALITY, and ContractNLI) chosen for their naturally long input texts and the diversity of tasks they cover, from summarization to multiple-choice QA. A critical aspect of SCROLLS is the emphasis on tasks that require synthesizing dispersed information across long texts, unlike conventional benchmarks that typically involve texts of much shorter lengths.
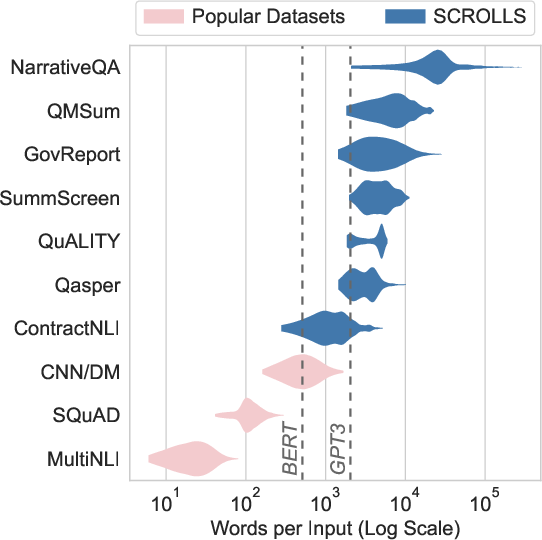
Figure 1: The distribution of words per input in SCROLLS datasets (blue), compared to frequently-used NLP datasets (pink).
Evaluation Metrics
SCROLLS employs a unified text-to-text format across its datasets, which simplifies model evaluation. The benchmark uses different evaluation metrics tailored to the nature of each task: ROUGE for summarization, F1 for QA, and exact match (EM) for multiple-choice and NLI tasks. Notably, SCROLLS provides a live leaderboard that aggregates performance across tasks, offering an aggregate score representation to facilitate cross-model comparisons.
Baseline Experiments
Initial baselines using BART and Longformer Encoder-Decoder (LED) reveal significant opportunities for improvement. The experiments underscored a consistent trend: access to more context (longer input sequences) generally led to better model performances. However, even with LED's extensive input capabilities, the results suggest existing models are currently inadequate at capturing the nuanced dependencies inherent in long texts.
Results Analysis
The experiments offer insight into the challenges posed by SCROLLS:
- Context Length: Increasing input token length considerably improves model performance, as evident from BART and LED baseline comparisons. Models that process longer sequences achieve higher aggregate scores, reflecting the necessity of longer contexts to capture relevant dependencies.
- Comparison of Models: Despite LED being specialized for longer texts, BART achieves competitive scores with a significantly smaller input token capacity. This raises considerations regarding the optimization needs for transformer variants handling extensive contexts.
Dataset Characteristics
The benchmark capitalizes on the intricate nature of naturally long texts. The quantitative and qualitative analyses establish the presence of widely dispersed critical information within inputs that models must consolidate to produce correct outputs. This dispersion is a defining characteristic contributing to SCROLLS' challenge.
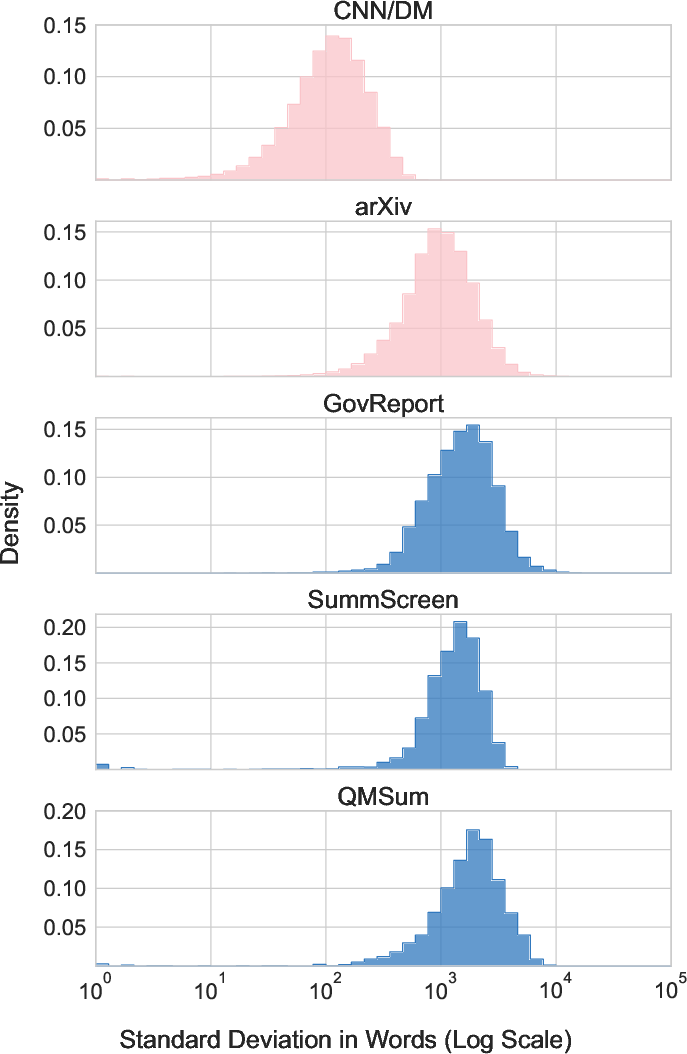
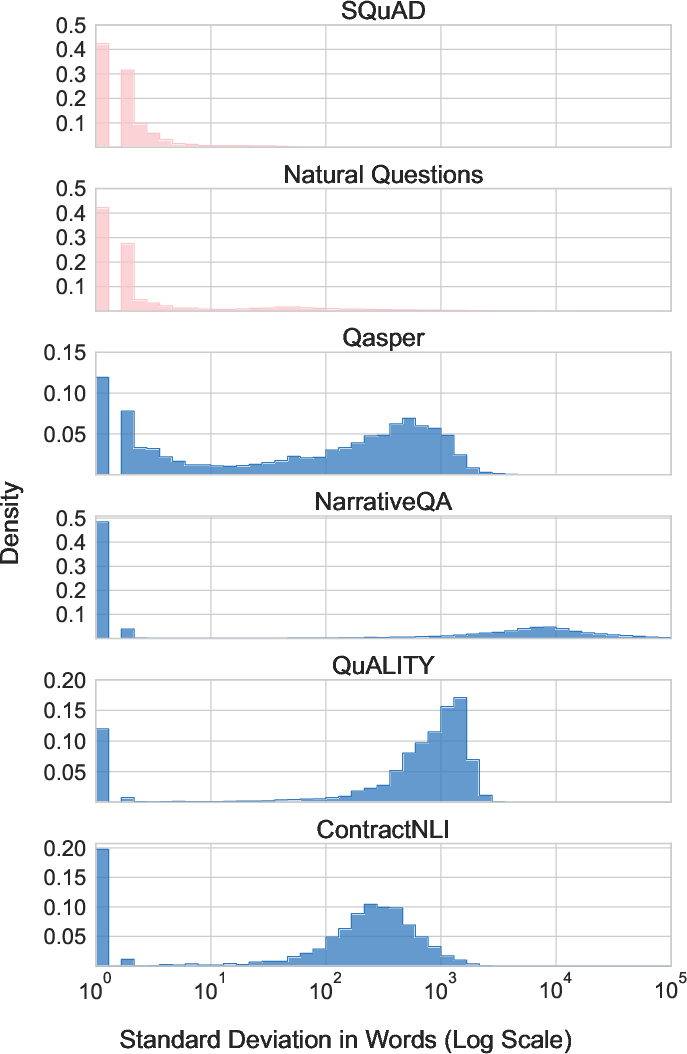
Figure 2: Summarization datasets.
Implications and Future Work
The release of SCROLLS holds implications both practical and theoretical. Practically, it initiates a shift towards developing architectures capable of effectively processing long texts. Theoretically, SCROLLS pushes the boundaries on understanding long-range dependencies in text, paving the way for novel pretraining strategies and evaluation methodologies. Future research could focus on optimizing transformer models specifically for the complexities of long discourse and extending SCROLLS to include multilingual datasets.
Conclusion
SCROLLS provides an innovative benchmark filling the gap left by traditional short-text benchmarks, presenting a specialized environment to test and improve transformer architectures' capabilities over long texts. Its comprehensive design and baseline results highlight significant opportunities for advancement in NLP models' handling of long-range dependencies and suggest critical paths for future research and development.
(Figure 3)
Figure 3: Summarization datasets.

