- The paper introduces an Approximate Archetypal Analysis (AAA) algorithm that leverages probabilistic methods to efficiently reduce data dimensionality and maintain predictive accuracy.
- It utilizes truncated SVD and random projection techniques to construct approximate convex hulls, streamlining data representation in high-dimensional spaces.
- Empirical results on datasets such as S&P 500 stocks, Intel images, and MNIST digits demonstrate significant improvements in computational efficiency and representation accuracy.
Probabilistic Methods for Approximate Archetypal Analysis
Introduction
The paper presents an innovative approach to archetypal analysis (AA), addressing the computational limitations that have historically constrained its application to large-scale datasets. By leveraging probabilistic methods from high-dimensional geometry, the authors introduce techniques for dimensionality reduction and representation cardinality reduction. These techniques aim to streamline the AA process without sacrificing predictive accuracy or computational efficiency.
Convex Hull and Dimensionality Reduction
Archetypal analysis seeks to find a convex polytope that can represent the dataset through archetypes located at its vertices. However, computing these archetypes directly from high-dimensional data can be computationally intensive. The paper suggests using two key preprocessing steps: dimensionality reduction and cardinality reduction.
Dimensionality Reduction: The authors propose using a truncated Singular Value Decomposition (SVD) to embed the original dataset into a lower-dimensional subspace while preserving its geometric properties. The SVD offers an efficient computation of rank-reducing matrices, which minimizes the Frobenius norm approximation error — thus enabling AA to operate effectively even when large datasets are involved (Figure 1).
Approximate Convex Hulls: A random projection strategy is employed to identify significant extreme points that represent the convex hull of the dataset. This is done by analyzing the curvature of data points, enabling a parsimonious subset selection to construct an approximate convex hull efficiently, which reduces computational demand while maintaining adequate representation of the dataset's structure (Figure 2).

Figure 1: An example of the convex hull (red solid curves) and an approximate convex hull (blue dashed curve) of a randomly generated dataset.
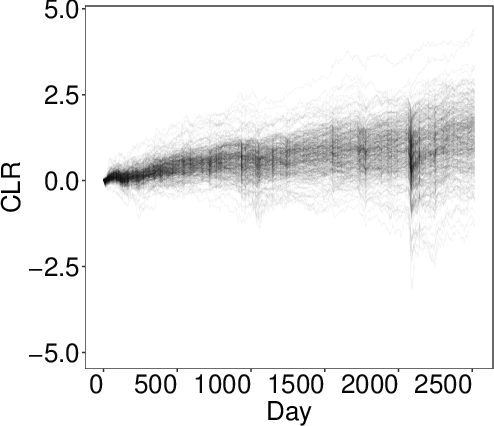
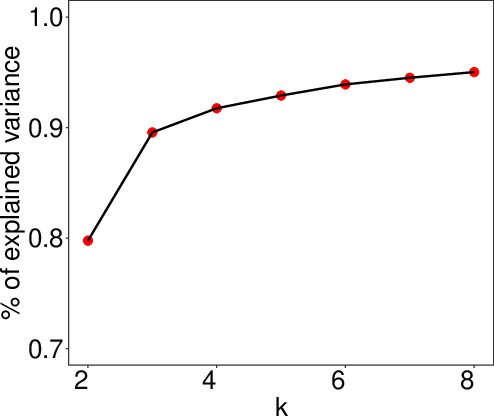
Figure 2: The CLR of 504 S{additional_guidance}P 500 stocks from December 2011 to December 2021 (left). Variances of $explained by the k archetypes identified by AA as a function of k for k=2,\cdots, 8 (right).*
### Probabilistic Approach and Algorithm
The paper provides a theoretical foundation for the probabilistic methods employed in reducing data complexity, demonstrating that the convex hull achieved through randomized projections retains accuracy akin to exact solutions. The proposed "Approximate Archetypal Analysis" (AAA) algorithm combines these reduction techniques, ensuring a solution with minimal prediction error. The algorithm's efficiency is validated through extensive numeric experiments across diverse datasets, with empirical results showcasing its robustness in preserving data variance and reducing computation time.
(Figure 3)
*Figure 3: Instances of the computed archetypes by SVD-AA, AAA, and archetypes in the first 10 experiments.*
(Figure 4)
*Figure 4: Boxplots of the running times (left) and residuals (right) of SVD-AA, AAA and archetypes in 100 experiments.*
### Numerical Results and Practical Implications
The novel methods proposed in the paper enable AA to handle large and high-dimensional datasets. The authors apply their AAA algorithm to datasets like S&P 500 stock prices, Intel image scenes, and MNIST handwritten digits, demonstrating significant improvements in computational efficiency without compromising accuracy (Figure 3 and Figure 4). On the practical side, these methods can be integrated into machine learning pipelines whenever interpretable decomposition of data into patterns or features is required.
(Figure 5)
*Figure 5: Variances explained by the first five principal components of$ (left). Scatterplot of the reduced representation of $$ with respect to the first two left singular vectors (which account for 97\% of the variation of the dataset) and its convex hull. The red triangles are the reduced representation of the three archetypes (right).
Conclusion
The paper offers a comprehensive solution to the computational challenges faced by archetypal analysis, making it viable for large-scale data applications. By achieving reductions in both dimensional and cardinal representations efficiently, AA can be leveraged practically in various fields that demand data analysis and pattern recognition. Future research may focus on optimizing these probabilistic methods further or exploring their convergence with other advanced computational techniques.