- The paper demonstrates that SNI can be inferred from encrypted TLS traffic by exploiting side-channel features using a deep learning ensemble.
- It compares classical Random Forest methods to novel CNN-RNN architectures, achieving up to 82.3% accuracy in SNI classification.
- The study underscores the privacy risks and the need for enhanced protocols to mitigate metadata leakage in modern TLS deployments.
Deep Learning for Network Traffic Classification: Toward Robust SNI Detection from Encrypted TLS Flows
Introduction and Motivation
The paper "Deep Learning for Network Traffic Classification" (2106.12693) systematically investigates the capabilities of deep learning models for server identification in encrypted HTTPs flows, focusing on the recovery of Server Name Indication (SNI) information from encrypted traffic without direct access to SNI headers. Motivated by the increasing deployment of Transport Layer Security (TLS), which obscures protocol metadata and payload content from traditional traffic analysis, the work addresses whether service-level identifiers can still be inferred by exploiting side-channel statistical artifacts in encrypted traffic. This question has heightened importance given the advent of Encrypted SNI (ESNI) and related privacy advancements.
The attack surface enabled by side-channels in packet timing and size arises directly from the mechanics of TLS handshake protocols and the subsequent encrypted exchange.
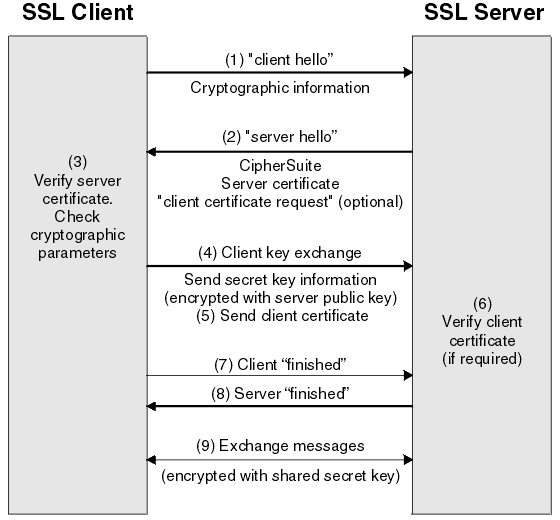
Figure 1: Standard TLS handshake, with SNI transmitted in the clear during the ClientHello message, enabling passive SNI-based classification.
The central research goal is SNI classification—identifying the specific HTTPS service (e.g., drive.google.com, maps.google.com) accessed by a client—using only encrypted TLS traffic, excluding the SNI field itself, which may be absent, encrypted, or spoofed. The task is framed as a supervised learning problem where each connection's label is the ground truth SNI, but only aggregated and sequential side-channel features are provided as predictors.
Prior to the integration of deep learning, state-of-the-art approaches used feature-based classifiers such as Random Forests over handcrafted statistics (packet sizes, inter-arrival times, directionality, etc.). Some success in basic application identification (e.g., SSH vs. Skype) has been shown, but the granularity and robustness for modern web services are insufficient. Only limited forays into deep learning have appeared in the traffic classification field, and none have directly targeted SNI classification at the granularity undertaken in this paper.
Data and Feature Construction
The dataset is derived by systematically crawling top accessed HTTPS sites using Chrome and Firefox over two weeks, resulting in hundreds of thousands of annotated TCP flows. Each connection is labeled by its observed SNI during the TLS handshake but later analyzed after removing all SNI-exposed data.
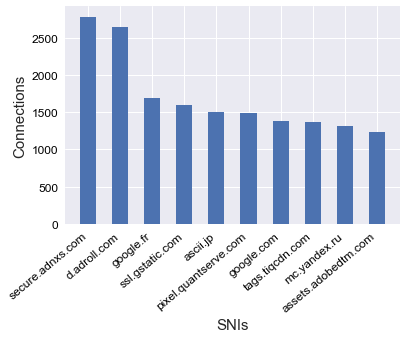
Figure 2: Distribution of the top 10 SNI classes by connection count in the Chrome dataset.
Two families of features are constructed:
- Statistical Features: Aggregate descriptors (mean, quantiles, min/max, variance) of packet sizes, inter-arrival times, and payload sizes, calculated in various directions (client ↔ server).
- Sequence Features: Time-ordered sequences of packet sizes, payload lengths, and log-transformed inter-arrival times, truncated or padded to length n=25 for input to RNN architectures. Directionality is also considered in later experiments.
Model Architectures
The baseline classical approach is a Random Forest trained on statistical features, as advocated in prior works and reinforced by Auto-Sklearn optimization.
For the deep learning approach, the architecture coalesces convolutional and recurrent modules:
- Each input sequence type (packet size, payload, inter-arrival) is processed by its own 1D CNN (extracting short-range dependencies), followed by one or two GRU layers (modeling temporal patterns), then a feedforward classifier.
- An ensemble is formed by averaging the Softmax outputs from the three parallel CNN-GRU pipelines trained on packet size, payload, and inter-arrival sequences.
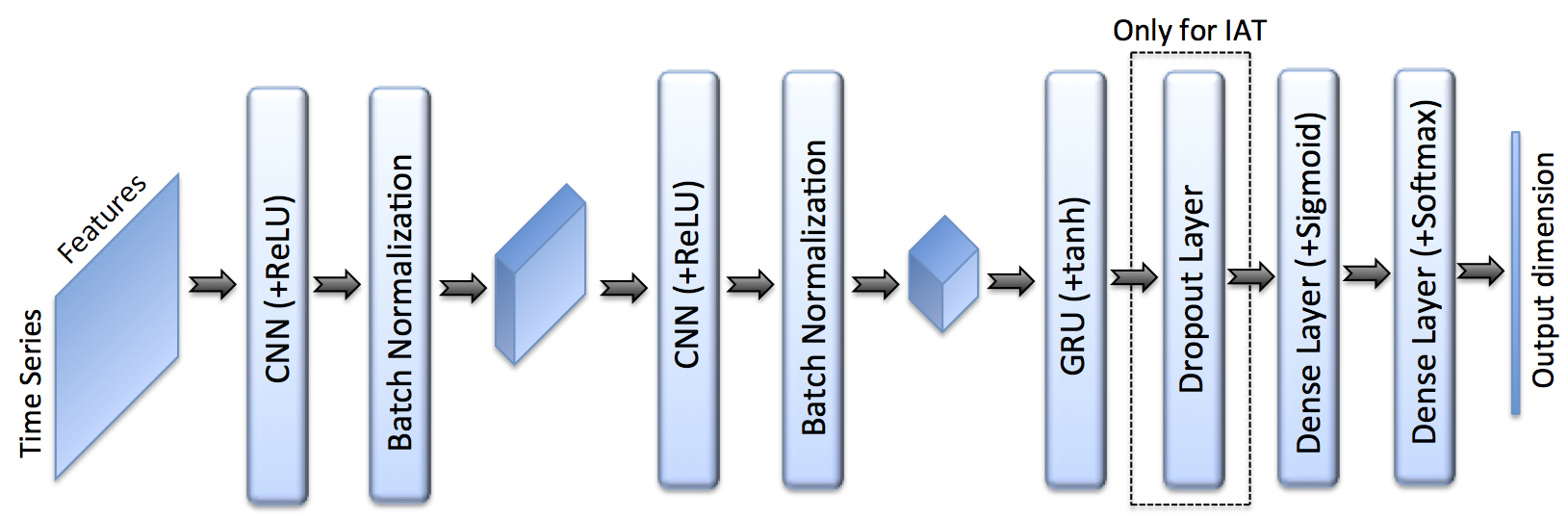
Figure 3: Schematic of the final CNN-RNN model, mapping time-series features to SNI class predictions via convolutional, recurrent, and fully-connected layers.
Benchmarking and Results
Classification accuracy is assessed using extensive 10-fold cross-validation, stratified across varying SNI class cardinalities as determined by the minimum connections per class filter.
- With a minimum of 100 connections (covering 532 SNI classes), Random Forest achieves 92.2% accuracy.
- The best baseline RNN (two-layer GRU on packet sequences) yields 67.8% accuracy.
- Upgraded CNN-RNN networks on packet, payload, and inter-arrival sequences improve single-feature DL accuracy to 77.1%, 78.1%, and 63.2%, respectively.
- The ensemble CNN-RNN over all sequence features further increases accuracy to 82.3%.
Combining the Random Forest with the ensemble CNN-RNN in a weighted meta-ensemble (RF: 1/2, each DL: 1/6) yields measurable gains, surpassing standalone Random Forest in overall and per-class accuracy.
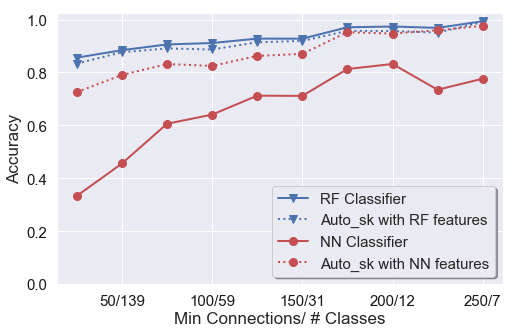
Figure 4: 10-Fold Cross Validation accuracy on day one for various classifiers and feature representations, illustrating the baseline and ensemble improvements.
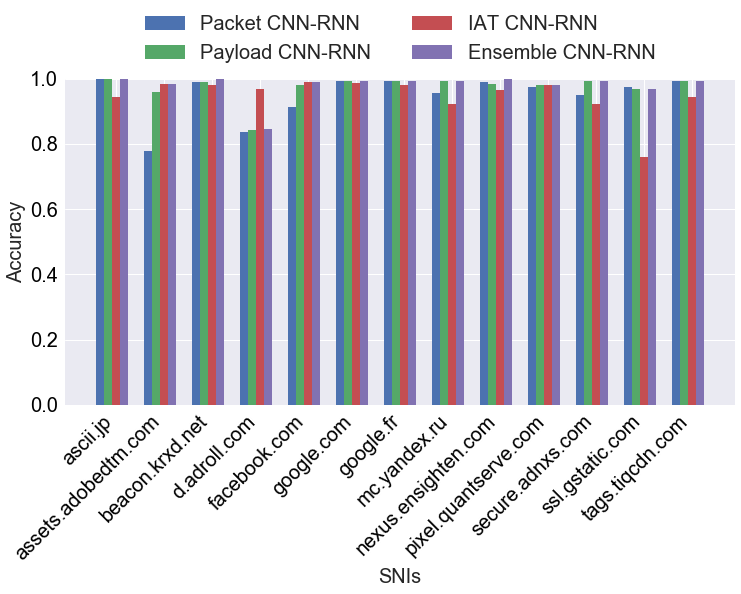
Figure 5: Comparative SNI prediction accuracy by classifier for classes with at least 1000 connections—the ensemble CNN-RNN is superior to any single model.
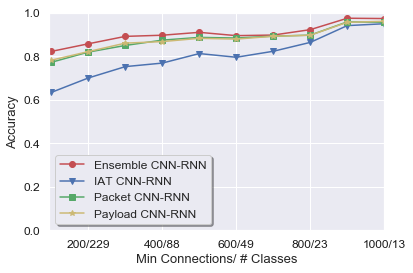
Figure 6: Ensemble CNN-RNN universally outperforms individual CNN-RNNs regardless of minimum connections threshold.
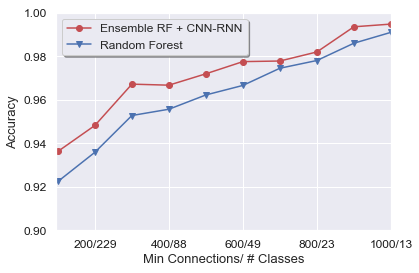
Figure 7: Combining ensemble CNN-RNN predictions with Random Forest yields the highest accuracy, especially for difficult cases (accuracy y-axis is restricted to [0.9,1.0]).
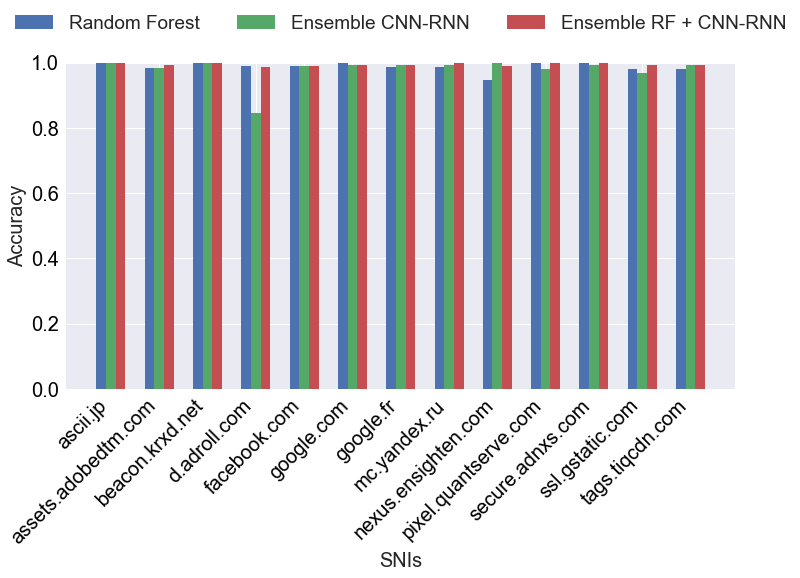
Figure 8: Per-class accuracy across classifiers, substantiating that the RF + CNN-RNN ensemble optimally handles the diversity of real-world SNIs.
Metrics beyond accuracy—macroscopically averaged precision, recall, and F1—consistently reinforce the superiority of the meta-ensemble. These results also highlight strong class imbalance effects and the dependence of achievable accuracy on the minimum sample threshold.
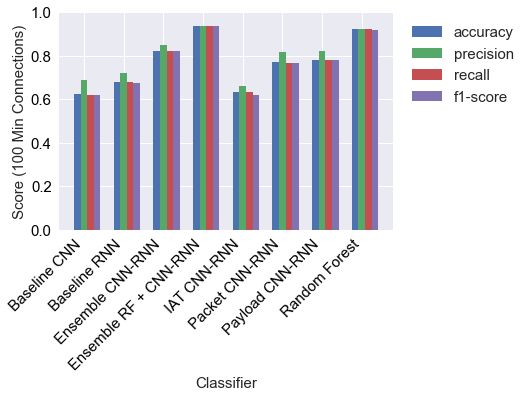
Figure 9: Macro-averaged accuracy, precision, recall, F1 for major classifiers (min connections = 100), with the RF + CNN-RNN ensemble dominating all measures.
Analysis: Model Design and Feature Impact
Directionality was explored as an auxiliary input channel for CNN-RNNs, with mixed and inconsistent impact. Theoretical justification for directionality is well-motivated, but empirical evidence remains inconclusive.
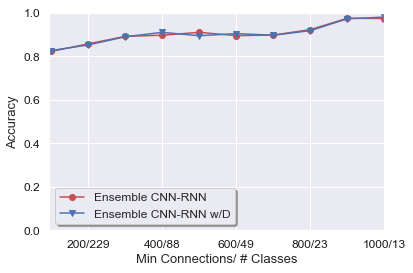
Figure 10: Addition of directional features to CNN-RNN ensembles provides inconsistent effect on classification accuracy, suggesting more nuanced modeling is necessary.
Hyperparameter tuning, alternative weighting schemes for the ensemble components, and per-feature architecture optimization are noted as open avenues for performance improvement. The current design is not tuned for specific cardinality regimes or SNI class distributions.
Implications and Theoretical Consequences
This work confirms that SNI service identifiers can be reliably inferred from side-channel features in encrypted flows using modern deep learning, even in the absence of unencrypted header fields. This contradicts claims that ESNI or similar header-encryption protocols provide complete privacy against service-level traffic analysis. The findings imply that traffic classification is driven not just by information explicitly present in metadata but also by content- and context-dependent statistical patterns implicitly induced by service-specific interaction.
In practical terms, network operators, censors, and attackers can deploy classifiers of this type relying only on observable packet features, regardless of ongoing protocol efforts to hide or obfuscate SNI. Conversely, the results increase the challenge for privacy advocates, indicating that eliminating explicit identifiers alone is insufficient; defending against classification requires suppressing fine-grade traffic statistical variability, which entails significant cost or fundamental protocol redesign.
On the AI methodological side, the results show the efficacy of specialized deep learning models for side-channel inference, but also delineate current limitations. Even sophisticated CNN-RNN ensembles remain outperformed by statistical classifiers (Random Forest) unless combined in a meta-ensemble, suggesting that deeper or alternative neural architectures or feature selection strategies warrant further exploration.
Future Directions
Possible research directions include:
- Real-time deployment and evaluation on live traffic streams with active evasion or adversarial adaptation.
- Optimization of feature engineering pipelines in the presence of ESNI or more aggressive flow-shaping countermeasures.
- Specialized neural architectures explicitly designed for long-range flow dependencies or incorporating self-attention.
- Formal quantification of the information leakage rate from encrypted flows and its bounds under varying obfuscation mechanisms.
Conclusion
Through methodical experimentation and architectural innovation, "Deep Learning for Network Traffic Classification" demonstrates that SNI-level service identification is possible from encrypted HTTPS traffic using only side-channel statistics and deep learning models. A hybrid ensemble (Random Forest plus CNN-RNN) outperforms the previous state-of-the-art, indicating the persistence of metadata leakage and the practical limitations of header-encryption protocols. The results underscore the need for continued research into both defensive mechanisms against traffic analysis and more advanced, adaptive machine learning approaches for traffic inference.

