- The paper introduces a reinforcement learning framework that uses tactile feedback to enhance robotic piano play.
- It formulates piano playing as a Markov Decision Process, integrating CNN and MLP architectures with the SAC algorithm.
- Experimental results demonstrate that RL agents outperform scripted controllers in timing, volume control, and fingering efficiency.
Learning to Play Piano with Dexterous Hands and Touch
Overview
The paper "Towards Learning to Play Piano with Dexterous Hands and Touch" explores the application of reinforcement learning (RL) to teach robotic hands to play the piano by leveraging tactile sensors. The study uses a multi-modal sensory approach that incorporates visual, auditory, and tactile data to train robotic hands on a simulated piano task. The paper demonstrates how tactile feedback and RL can enable a robot to learn rhythm, volume control, and efficient fingering during piano play.
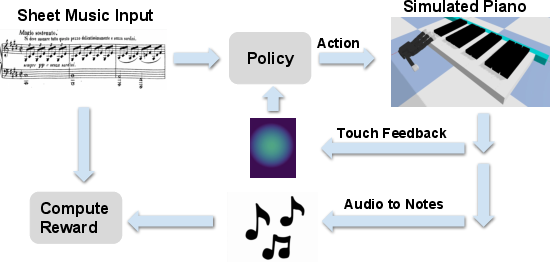
Figure 1: Playing the piano is intrinsically a multi-modal task involving vision, audio, and touch.
Methodology
The primary focus of this research is the formulation of piano playing as a Markov Decision Process (MDP), enabling the application of RL algorithms. A simulation environment was constructed using the Bullet physics engine, featuring a robot hand equipped with DIGIT tactile sensors.
Observation and Action Spaces
- Observation Space: Comprised vectorized MIDI sheet music, tactile sensory data, and the kinematic state of the robot hand.
- Action Space: Includes joint movements and hand positioning for precise piano key interaction.
The core of this approach lies in the reward structure which incentivizes correct key press in terms of timing, velocity, and location.
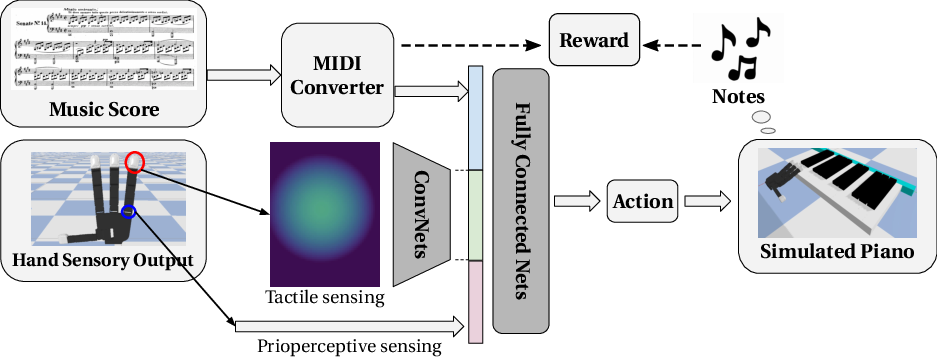
Figure 2: System overview showing the integration of MIDI, tactile, and kinematic data into the policy network.
Implementation and Training
The model employs the Soft Actor-Critic (SAC) algorithm, a type of reinforcement learning known for balancing exploration and exploitation while handling high-dimensional action spaces.
- Network Architecture: The policy network uses a combination of Convolutional Neural Networks (CNN) for tactile image processing and Multilayer Perceptrons (MLP) for other state information.
- Training Regime: Initial exploration steps facilitated better action space coverage, while reward functions were tuned to manage complex task requirements such as chord playing and dynamic rhythm adaptations.
Experimental Results
Empirical studies contrasted the RL-based agents against scripted controllers and random agents across various piano tasks, including one-note, rhythmic, and chord tasks. The experiments verified:
- Learning Efficiency: RL agents could match, if not exceed, the performance of manually programmed agents especially benefiting from tactile inputs.
- Task Complexity: Increased task difficulty required more simulation steps, but RL agents managed extended tasks effectively with compositional policy execution strategies.


Figure 3: Samples from the piano-robot hand simulator demonstrating performance on piano tasks.
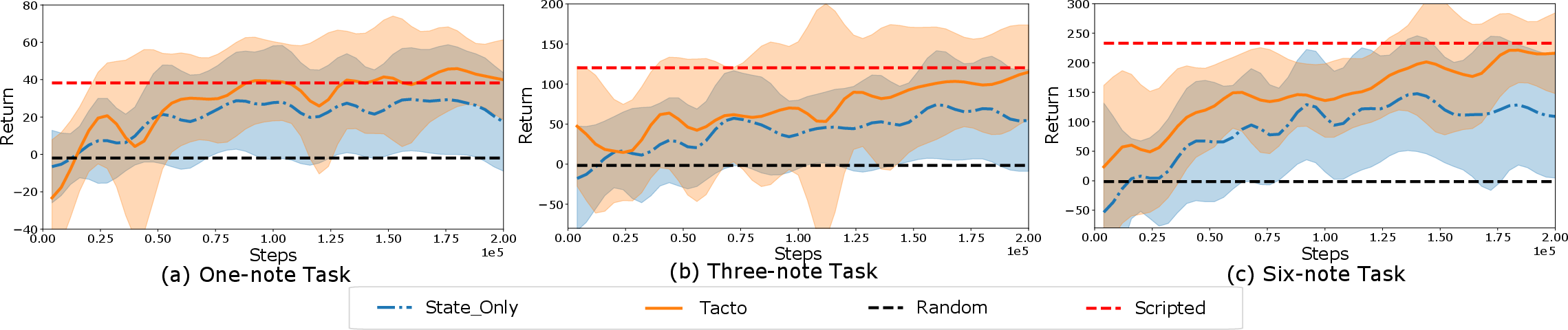
Figure 4: Comparative results for different music task levels showcasing RL agent proficiency.
Compositional Policy Execution
For handling long-horizon tasks, a compositional execution approach was adopted, where policies developed for shorter segments were executed sequentially. This method proved more effective for extended musical performances, highlighting the adaptability of RL to complex tasks when decomposed.
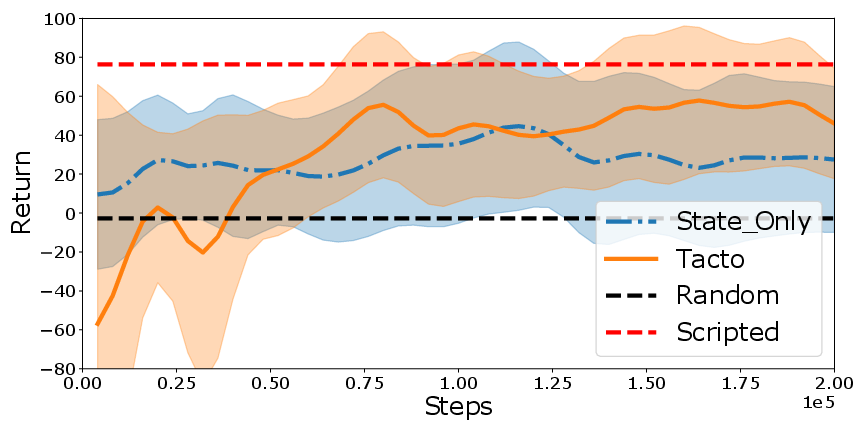
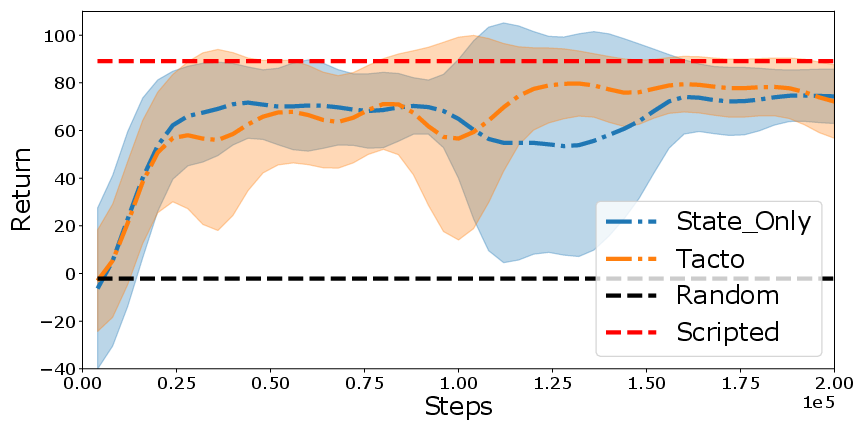
Figure 5: Qualitative results indicating the impact of tactile fingering indicators on task performance.
Conclusion
The paper provides substantial evidence of RL's potential in robotic applications involving fine motor skills and sensor integration. It highlights the role of tactile information in improving robotic dexterity and efficiency in performing musically complex tasks such as piano playing. Future directions may include further exploration of real-world implementation and the extension to other musical instruments or tasks requiring nuanced sensorimotor coordination.