- The paper presents a Bayesian framework that models both epistemic and aleatoric uncertainty in neural retrieval, offering calibrated relevance scores.
- It applies efficient MC-Dropout in the final layers to reduce computational overhead while maintaining robust uncertainty estimation.
- Risk-aware reranking using CVaR and the new ERCE metric demonstrates significant improvements in retrieval performance metrics like nDCG.
Efficient Uncertainty and Calibration Modeling for Deep Retrieval Models
Introduction
The paper "Not All Relevance Scores are Equal: Efficient Uncertainty and Calibration Modeling for Deep Retrieval Models" introduces a novel approach to integrate uncertainty modeling into neural information retrieval (IR). This research addresses the limitations of deterministic relevance scoring by establishing a Bayesian framework, which enables the expression of uncertainty and calibration in document retrieval tasks. The approach maintains computational efficiency, allowing for practical deployment even within costly deep learning architectures.
Bayesian Approach to Capture Uncertainty
The paper leverages a Bayesian perspective to represent a retrieval model's uncertainty about its own scoring through distributions rather than isolated point estimates. By employing Monte Carlo Dropout (MC-Dropout) as an efficient variational inference technique, the proposed method captures both epistemic and aleatoric uncertainties. Such uncertainties provide critical information when neural models encounter out-of-distribution documents or during reranking in diverse collections.
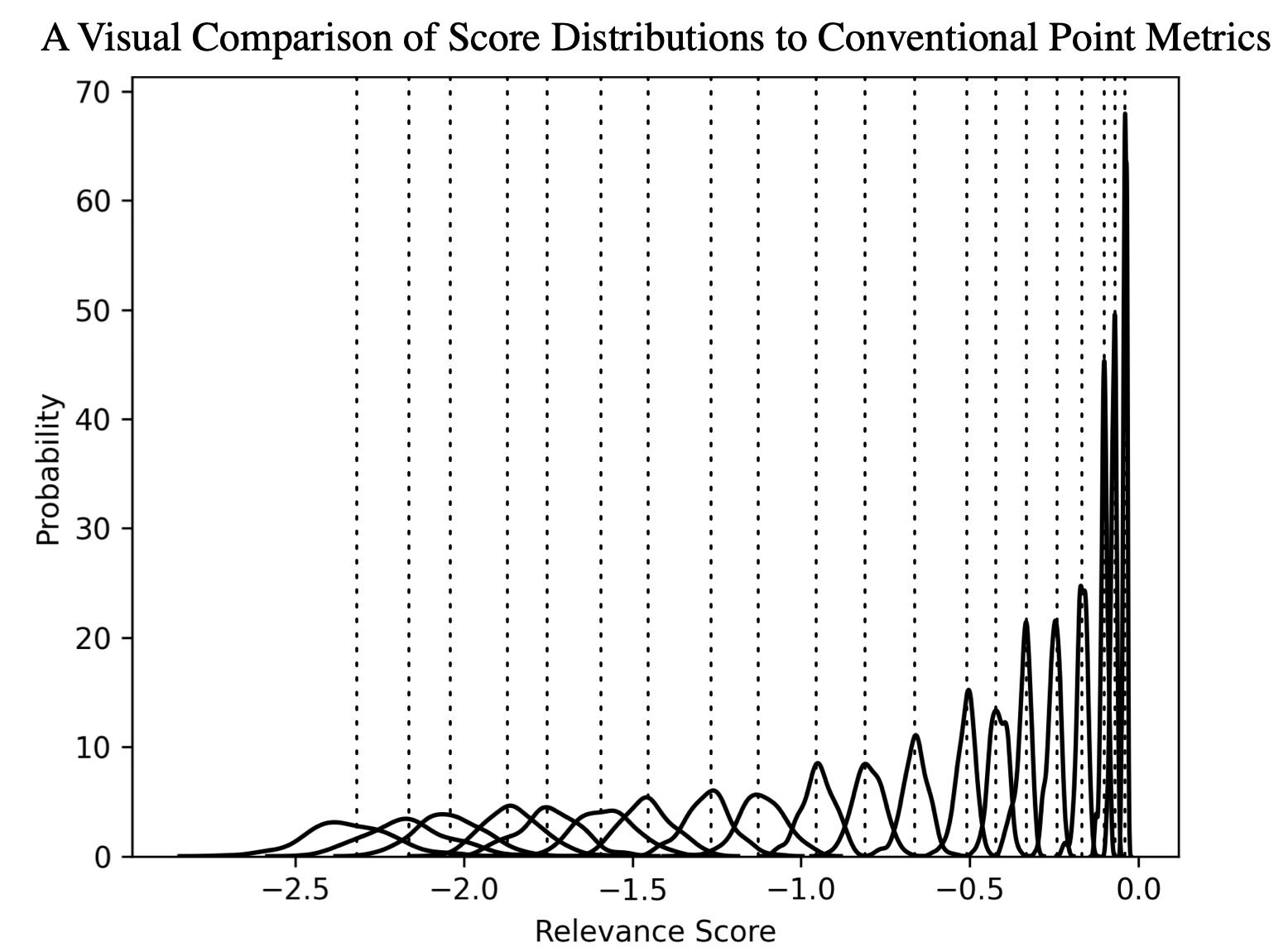
Figure 1: A visual comparison of conventional interpretation versus Bayesian perspective showing score uncertainty.
MC-Dropout involves running dropout at inference time multiple times to simulate draws from the model's distribution, furnishing a distribution of scores rather than a single output. The paper also proposes an efficient modification where only the final layers are subjected to MC-Dropout, thus significantly reducing computational overhead without notable loss in uncertainty estimation fidelity.
Calibration and Risk-Aware Reranking
Calibration, in this context, implies the alignment of predicted scores with their actual relevance. The paper formalizes a new metric, the Expected Ranking Calibration Error (ERCE), optimized for ranking tasks. It measures the uniformity of uncertainty estimates across relevant and non-relevant document pairs within a query. This framework emphasizes relative comparisons across documents rather than attempting absolute relevance scoring.
The concept of Conditional Value at Risk (CVaR) is employed to provide risk-aware reranking strategies. CVaR allows for reordering documents based on the estimated distribution tails of their relevance scores, which reflects either optimistic or pessimistic performance expectations based on user-defined risk tolerance. This approach has been statistically shown to improve ranking metrics such as nDCG, especially under high uncertainty situations.
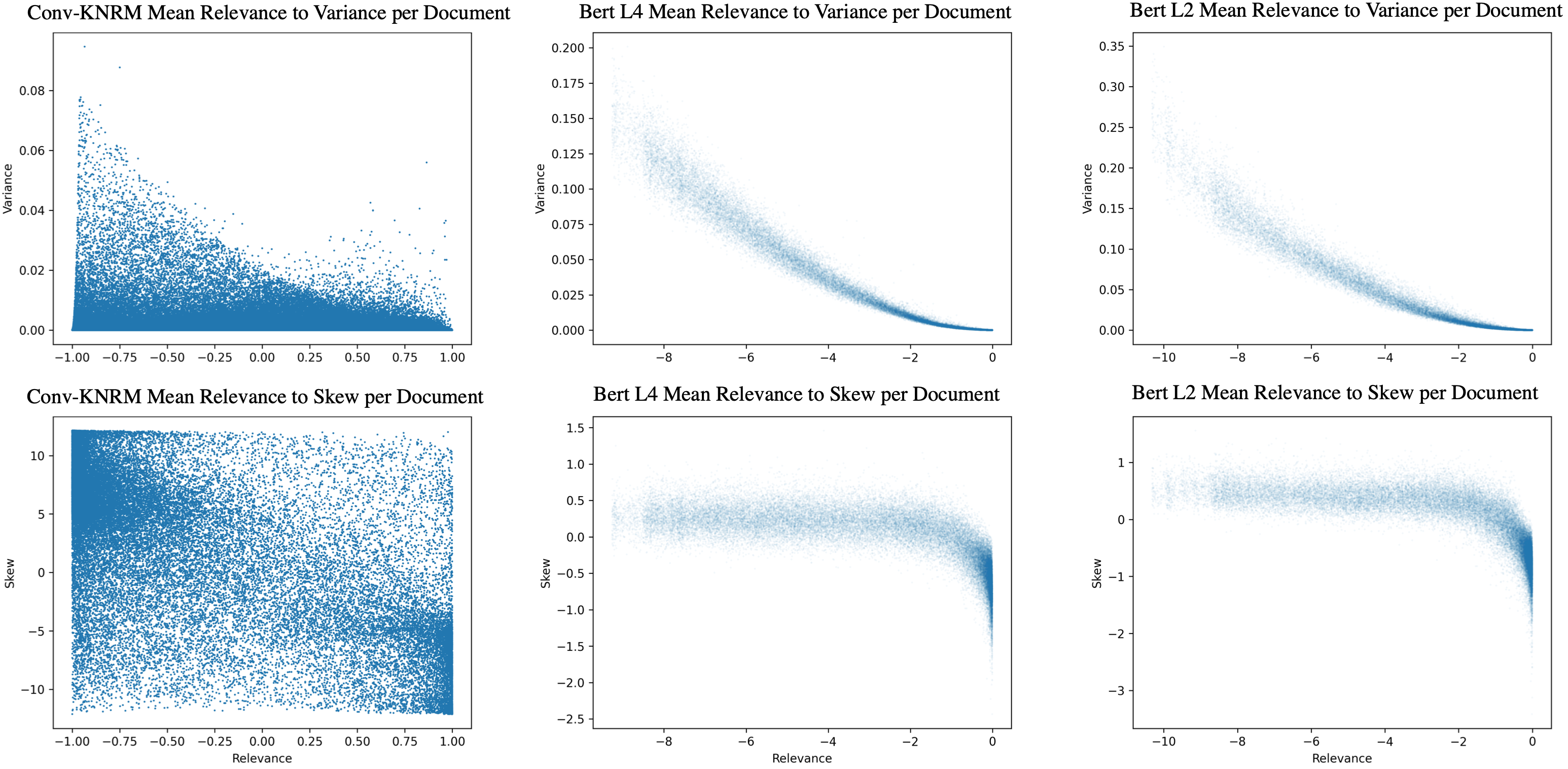
Figure 2: Mean-to-variance and mean-to-skew relationships demonstrating uncertainty expression through Bayesian last-layer dropout.
Empirical Evaluation and Results
The experiments, conducted on datasets like MS MARCO and TREC 2019 Deep Learning Track, reveal that Bayesian models maintain parity with deterministic models in terms of mean performance while providing additional uncertainty insights. Risk-aware rerankings achieved through CVaR have demonstrated increased performance, indicating the model's effective utilization of uncertainty information.
Calibration levels indicated by the ERCE metric suggest substantial improvements in Bayesian models, affirming their enhanced reliability in expressing confidence over a range of document scores. Additionally, the research validates the successful use of uncertainty information in downstream tasks such as query cutoff prediction.
Implementation Considerations
The method's practicality stems from its efficiency and ease of integration with existing IR models. The computational overhead added by MC-Dropout remains manageable, specifically when confined to the model's last layers. This property allows the framework to benefit a wide array of deep retrieval models, including those using BERT and Conv-KNRM architectures, without necessitating extensive computational resources.
Conclusion
The paper presents a compelling framework to incorporate uncertainty modeling in neural IR systems, enhancing their robustness, calibration, and performance. By expanding the application of Bayesian methods to real-world retrieval models, this research sets a foundation for further exploration in domains where uncertainty plays a pivotal role. The practical implications include advancements in areas like risk management in retrieval systems and improving interactions with search engines by providing users with better-calibrated confidence estimates.