- The paper demonstrates that deterministic BERT-based rankers are poorly calibrated under distributional shifts, affecting ranking quality.
- It introduces stochastic rankers using MC Dropout and Deep Ensembles, achieving up to 14% improvement in calibration error.
- Uncertainty estimates also enhance risk-aware ranking and improve unanswerable context predictions by up to 33%.
On the Calibration and Uncertainty of Neural Learning to Rank Models
Introduction
The paper "On the Calibration and Uncertainty of Neural Learning to Rank Models" addresses significant challenges in implementing neural Learning to Rank (L2R) approaches, particularly those based on BERT. The Probability Ranking Principle (PRP) asserts that optimal document ranking is achieved by ordering documents according to their probability of relevance. However, this principle assumes two conditions: the calibration of predicted probabilities and the certainty of these predictions. Deep neural networks (DNNs), including BERT-based models, often lack robust calibration and certainty in predictions. This paper proposes stochastic neural rankers that output predictive distributions to address these issues.
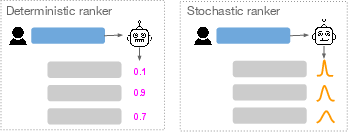
Figure 1: While deterministic neural rankers output a point estimate probability, stochastic neural rankers output a predictive distribution.
Calibration of Neural Rankers
Deterministic Neural Rankers
Initial experiments reveal that deterministic BERT-based rankers are inadequately calibrated, especially under distributional shifts such as cross-domain and cross-negative sampling conditions. In controlled environments where test data distributions mirror training data (no shift), BERT performs well with low calibration errors as depicted by near-diagonal calibration curves.
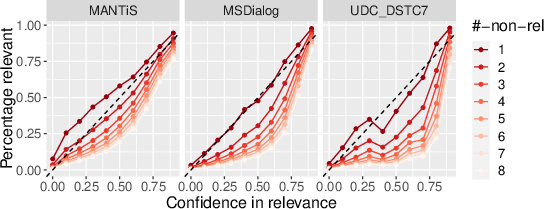
Figure 2: Calibration of BERT trained on balanced data but tested on unbalanced data reflects calibration errors in realistic conditions.
Stochastic Neural Rankers
To enhance calibration, the authors propose stochastic neural ranking approaches using techniques such as MC Dropout and Deep Ensembles. These methods yield stochastic BERT-based rankers (S-BERT) that provide better calibration compared to deterministic models, evidenced by reduced empirical calibration error (ECE) in various settings, achieving average improvements of 14% for Deep Ensembles and 10% for MC Dropout.
Uncertainty Estimates for Enhanced Neural Ranking
Risk-Aware Ranking
The stochastic rankers facilitate risk-aware neural ranking by incorporating uncertainty into the ranking process. By adjusting the risk aversion parameter b, models prioritize predictions with lower uncertainty, thereby improving ranking efficacy in challenging cross-domain and cross-NS setups. This approach demonstrated average improvements in ranking performance by 2% using Deep Ensembles and 1.7% using MC Dropout.
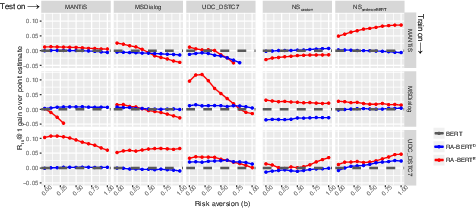
Figure 3: Gains in response ranking effectiveness under different values of risk aversion parameter b.
Predicting Unanswerable Contexts
Additionally, uncertainty estimates prove beneficial for predicting unanswerable conversational contexts (None Of The Above - NOTA). Using uncertainties as features in a Random Forest classifier improved NOTA prediction by an average of 33%, underscoring the utility of stochastic rankers beyond traditional ranking tasks.
Conclusion
The research underscores the importance of calibration and uncertainty modeling in neural L2R systems, particularly for BERT-based models. By implementing stochastic neural rankers, the paper presents substantial advancements in calibration, risk-aware ranking, and enhanced performance in predicting conversational contexts lacking suitable responses. Future directions include applying stochastic neural rankers to other IR tasks, fair retrieval, and dynamic query reformulation. The frameworks and findings contribute significantly to the development and implementation of more reliable and interpretable neural ranking systems.

