- The paper introduces CREST, a framework that uses causal interventions in simulation to isolate key state variables, resulting in more efficient manipulation policies.
- The methodology reduces input dimensionality by focusing solely on causally relevant features, enhancing sim-to-real transfer and robustness against domain shifts.
- Experimental results in block stacking and crate opening tasks confirm that CREST maintains stable performance despite increasing irrelevant variable contexts.
Causal Reasoning in Simulation for Structure and Transfer Learning of Robot Manipulation Policies
Introduction
The paper "Causal Reasoning in Simulation for Structure and Transfer Learning of Robot Manipulation Policies" (2103.16772) introduces CREST, a novel framework designed to improve the efficiency and robustness of sim-to-real transfer learning in robotic manipulation tasks. CREST leverages causal reasoning within simulation environments to discern the essential state variables pertinent to task execution, thus enabling the formulation of manipulation policies that are both compact and adaptable to unforeseen distribution shifts in real-world applications.
Methodology
CREST operates by conducting causal interventions using an internal model—a simplified simulation with approximate dynamics—to identify relevant state-action relationships. This identification aids in constructing neural network policies that ingest only significant state variables, leading to models that are inherently resistant to perturbations in irrelevant features.
Causal Structure Learning: CREST's core operation involves two primary steps. The first step identifies the collective relevant state variables for a given policy through iterative interventions in the simulation, asking, "If a variable changes, does the task execution still succeed?" The second step furthers this by associating each policy parameter with its specific subset of relevant state variables, fine-tuning inputs precisely to task requirements.
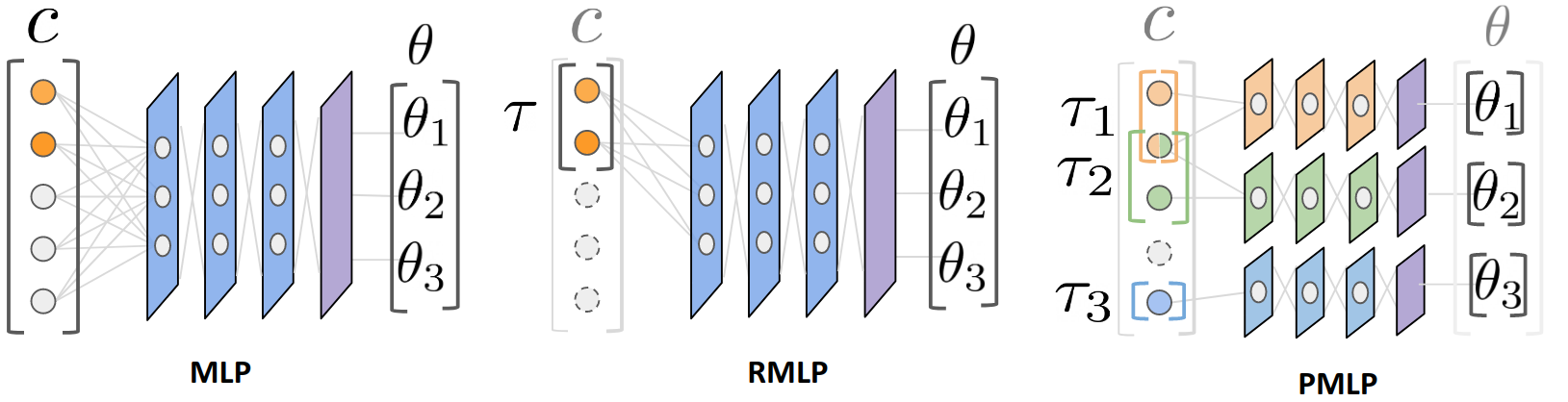
Figure 1: A visualization of the different policy types. CREST is used to construct both the Reduced MLP (RMLP) and Partitioned MLP (PMLP).
Policy Learning and Transfer
The policies derived via CREST are encapsulated within neural network architectures optimized for structure-driven learning. These include the baseline MLP, a Reduced MLP (RMLP) where the input is limited to relevant states, and a Partitioned MLP (PMLP) that assigns input subsets to specific policy parameters.
Each network is pretrained in the internal model environment utilizing domain randomization, allowing the model to adapt to a spectrum of task variations. Subsequently, the pretrained models are transferred and fine-tuned in the target simulation, minimizing the reliance on costly real-world data collection.
Experimental Results
The efficacy of CREST was evaluated through simulation experiments involving block stacking and crate opening tasks, with trials conducted in NVIDIA Isaac Gym. These tasks illustrated that CREST-enabled policies maintain robustness amidst significant irrelevant variable distribution shifts—a common scenario in sim-to-real transitions—by reducing input dimensionality solely to causally significant variables.
Block Stacking Task: CREST's data efficiency allows scalability concerning the number of distractors (blocks), demonstrating that performance remains stable without degradation from increasing irrelevant context dimensions.
Crate Opening Task: Despite a nonlinear relationship between relevant states and actions, CREST-based policies demonstrated similar resilience in the face of domain shifts, confirming the approach’s general applicability.
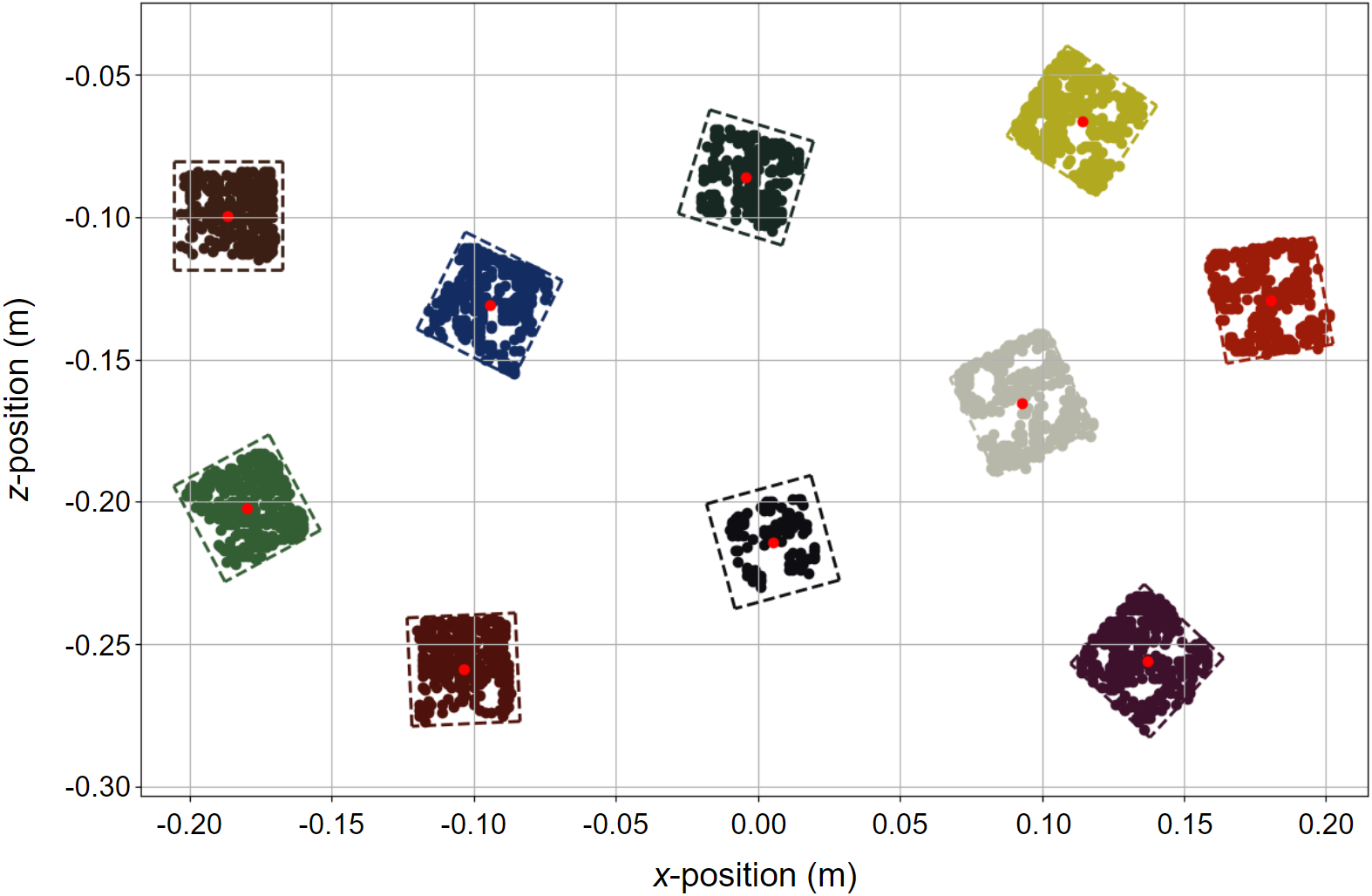
Figure 2: Block state estimation used for the sim-to-real experiments using RGB-D perception.
Conclusion
The CREST framework effectively streamlines robot manipulation policies, improving both sample efficiency for training and robustness against domain shifts. Its strength lies in its causal reasoning capabilities, which enable robots to focus on pertinent elements of the task environment, thus fostering adaptable learning. Future directions include the integration of precondition learning to mitigate infeasibility concerns and the development of automated methods for learning the internal model itself.
The potential of structure-based transfer learning, as embodied by CREST, signifies a pivotal shift toward more resilient and efficient sim-to-real methodologies in robotics, with implications for broader applications in adaptive AI systems.