- The paper presents CSAR, a consensus-based approach that merges simulated and real-world training to improve robotic manipulation and lower training costs.
- The methodology leverages simulated cameras, a structured reward mechanism, and an end-to-end DRL network to optimize pick-and-place performance.
- Experimental results show that increasing simulated agents and fine-tuning initial policies enhance real-world success rates and adaptability to new objects.
Sim-and-Real Reinforcement Learning for Manipulation: A Consensus-based Approach
The paper "Sim-and-Real Reinforcement Learning for Manipulation: A Consensus-based Approach" proposes an innovative algorithm for training robotic manipulators through a combined simulated and real-world environment. The primary focus is on enhancing training efficiency and decreasing real-world experimentation costs while maintaining effectiveness in task execution, specifically robot manipulation tasks such as pick-and-place operations.
Introduction
The rising need for efficient training models in robotic manipulation tasks has prompted the exploration of deep reinforcement learning (DRL) methods. Traditionally, sim-to-real models offer a training mechanism where robots learn in a simulated environment and then adapt to real-world conditions. However, discrepancies between simulation and reality often hinder performance.
A new proposition is the sim-and-real approach, integrating both simulated and real-world training processes. The paper introduces a Consensus-based Sim-And-Real deep reinforcement learning (CSAR) algorithm that combines the advantages of both worlds. CSAR leverages consensus principles from control engineering to harmonize learning between simulated and actual environments.
The outlined algorithm shows that the best policy in simulation does not directly correlate with optimal performance in a sim-and-real framework. Additionally, involving a greater number of simulated agents in training enhances the overall learning efficiency of the process.
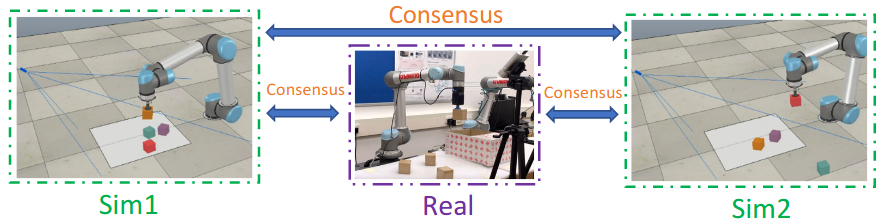
Figure 1: Pick-and-place objects with the CSAR approach.
Methodology
System Framework
The proposed framework involves a defined workspace captured using simulated cameras, generating input heightmaps for DRL processing. This system operates similarly in real-world environments with modifications to account for real-world camera variability. The CSAR algorithm performs training within this hybrid environment, allowing for parallel learning and interaction between simulated and real agents.
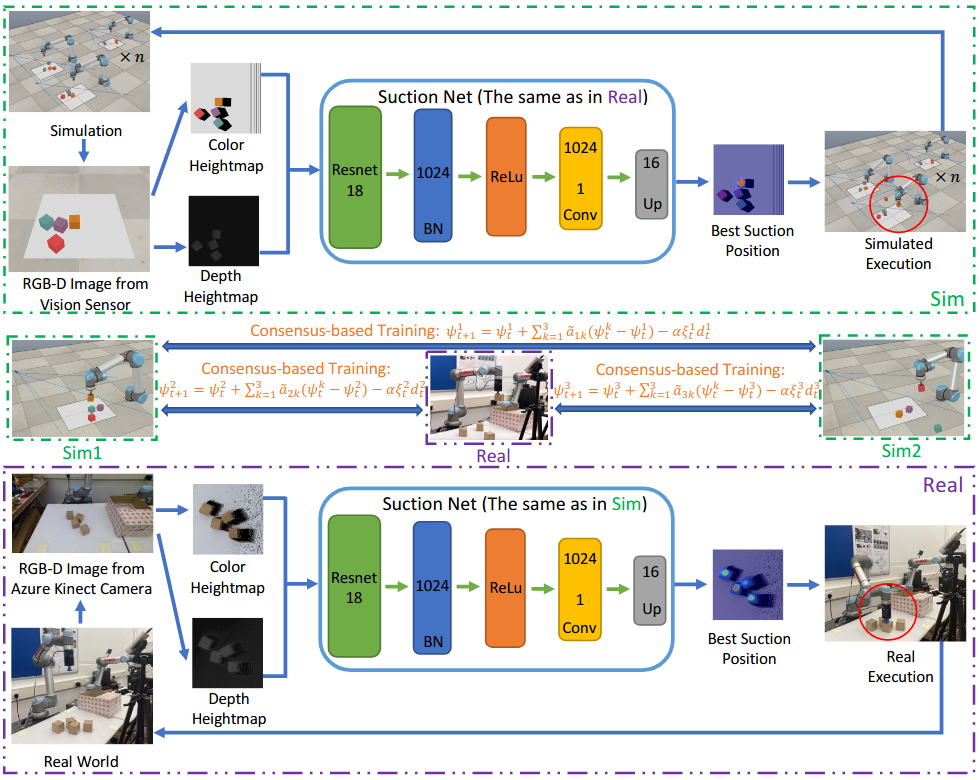
Figure 2: Overview of the proposed DRL framework with consensus-based training in the sim-and-real environment.
DRL Setup
- Action and State Space: DRL actions are derived from predicted suction positions on heightmaps. Meanwhile, states are represented by these heightmaps to focus on situational contexts during task execution.
- Reward Mechanism: A structured reward system differentiates effective suctions by distance thresholds to enhance learning precision and efficiency.
- Neural Network Architecture: A lightweight end-to-end network processes the heightmaps using convolutional layers for efficient decision-making on the best suction positions.
The algorithm operates under consensus-based training principles, ensuring coherent policy generation through iterative interactions amongst agents.
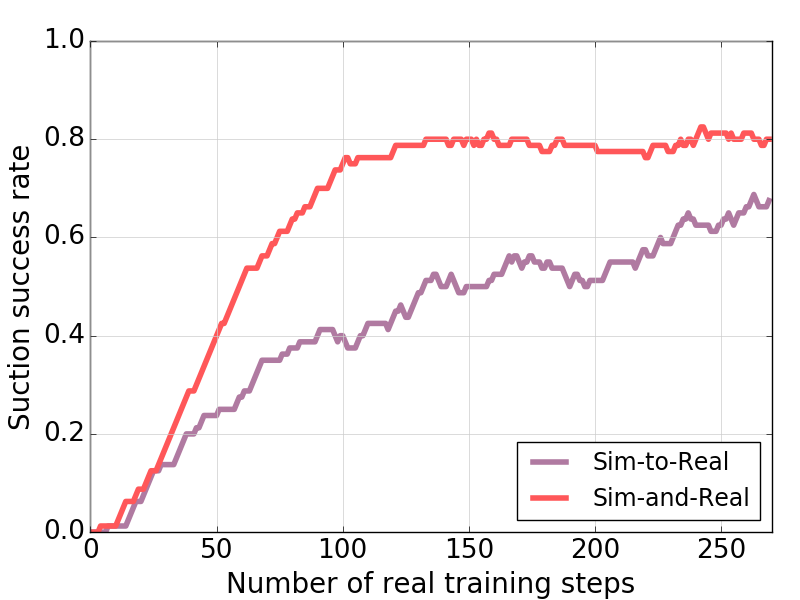
Experiments and Results
The experiments underscore the CSAR's potency in accelerating training and reducing costs:
Figure 4: Suction success rates of the real robot with different initial weights when applying the Sim-and-Real strategy.
- Agent Configuration: Increasing simulation agents enhances learning, reducing the disparity between simulated and real-world environments, thus optimizing training times.
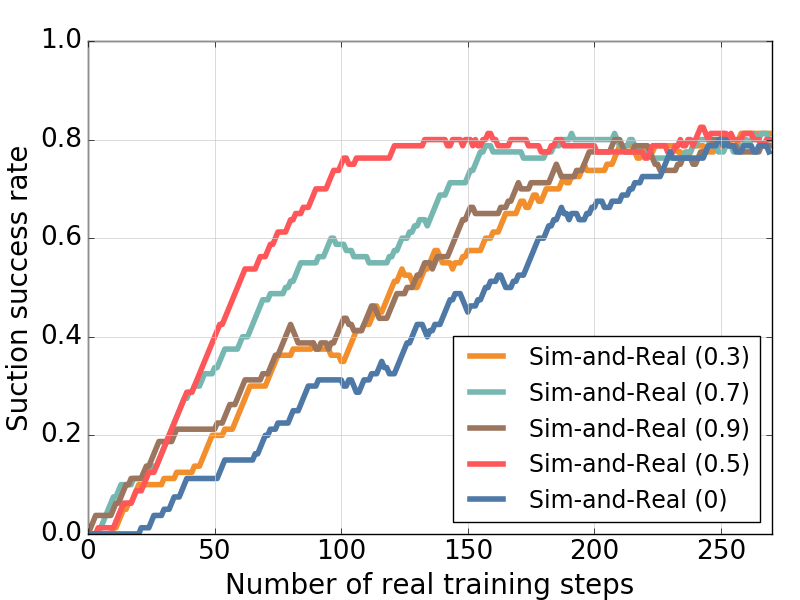
Figure 5: Suction success rates of the real robot with different numbers of simulated robots using Sim-and-Real strategy.
- Generalization Capability: The ability to adapt to novel objects beyond training demonstrates the CSAR's robustness and flexibility, underscoring its applicability to real-world diversity.
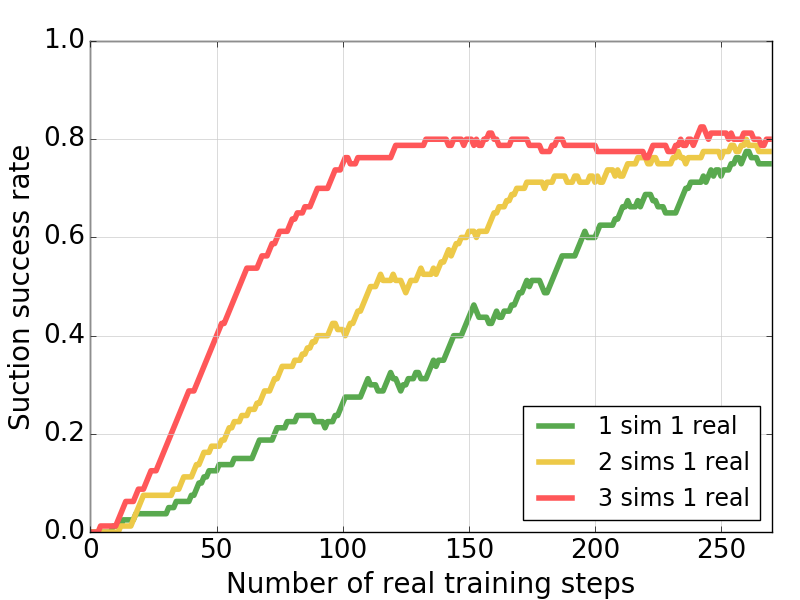
Figure 6: Novel objects for validation: (a) Environment 1; (b) Environment 2; (c) Environment 3.
Conclusion
The CSAR framework signifies an advancement in reinforcement learning for real-world robotics, highlighting its efficacy in dynamic and unpredictable environments. By strategically integrating simulated and real-world learning, it maximizes resource utility and minimizes constraints. Future research may explore extending this methodology to more complex scenarios, further optimizing the interface between simulated and real environments.